
Let’s Learn More About Python Data Classes

We’re Earthly. We simplify and speed up software building with containerization. Ideal for Python projects like the ones using data classes. Give us a look.
Since their introduction in Python 3.7, data classes have emerged as a popular choice for Python classes that store data. In a previous tutorial, we talked about what data classes are and some of their features, including out-of-the-box support for object comparison, type hints, and default values of fields. In this follow-up tutorial, we’ll continue to explore some more features of Python data classes.
We’ll take a closer look at setting default values with default_factory, initializing new fields from pre-existing fields with __post_init__, and much more. We’ll also discuss the improved support for __slots__ in data classes since Python 3.10.
Let’s get started!
Before We Begin
📋 Prerequisites
This tutorial assumes a basic understanding of Python data classes.
- To run the code example in the section on
__slots__, you need Python 3.10 or a later version. - All other code snippets will work as expected with Python 3.7+.
You can find the code used in this tutorial on GitHub.
To keep things simple, I’ll use the Student class from the previous tutorial on data classes:
from dataclasses import dataclass, field
@dataclass
class Student:
name: str
roll_no: str
major: str
year: str
gpa: float
classes: list = field(default_factory=list)Before we go any further, let’s review what we know about data classes:
- Data classes are great for defining data-oriented classes and have default implementations of the
__init__,__repr__, and__eq__methods. - They support type hints and default values for fields. Data class definitions do not allow mutable default arguments for fields.
- All data class instances are mutable by default, but you can set the
frozenparameter toTruein the@dataclassdecorator to make instances immutable.
Well, this was a quick review of data classes and not a replacement to reading the data classes tutorial. 🙂
Now let’s go beyond the basics of data classes!
Set More Complex Default Values With default_factory
Previously, we talked about how data classes allow us to specify default values for fields, both literals and callables. We also learned that they do not allow us to use mutable defaults. If you remember, we added a classes field, and used the field() function with default_factory set to the callable list, classes: list = field(default_factory=list).
However, you can use default_factory for other built-in and user-defined functions as well.
Now, let’s modify the Student data class a bit:
- Remove the
classesfield. - Rename the
roll_nofield toroll_num. (Why?roll_numreads better thanroll_no!)
At this point, the Student data class looks like this:
from dataclasses import dataclass, field
@dataclass
class Student:
name: str
roll_num: str
major: str
year: str
gpa: floatNext, let’s define a generate_roll_num() function that returns a roll_num string. The returned string is nine characters long, where the characters are sampled at random from the alphabet of uppercase letters and the digits 0-9:
import random
random.seed(42)
import string
...
alphabet = string.ascii_uppercase + string.digits
def generate_roll_num():
roll_num = ''.join(random.choices(alphabet,k=9))
return roll_num
...As default arguments should follow non-default arguments, let’s move roll_num as the last field in the data class definition. And set default_factory in the field() function to generate_roll_num.
from dataclasses import dataclass, field
@dataclass
class Student:
name: str
major: str
year: str
gpa: float
roll_num: str = field(default_factory=generate_roll_num)The default_factory calls the generate_roll_num function to initialize the roll_num field with a default value - whenever an instance of the Student class is created.
Let’s instantiate a Student object to verify this:
>>> from main import Student
>>> jane = Student('Jane','Computer Science','senior',3.99)
>>> janeAnd we see that jane has a roll_num field:
Student(
name="Jane", major="Computer Science", year="senior", gpa=3.99,\
roll_num="XAJI0Y6DP"
)Exclude Fields From the Data Class Constructor
Setting a default value makes a field optional in the constructor. And the default value is used only if the user does not provide the value for that field in the constructor.
So users of the class can still pass in whatever they like for the roll_num field. Here’s an example:
>>> julia = Student('Julia','Economics','junior',3.72,"don't know")
>>> juliaFor the Student object julia, the roll_num field has been set to the string “don’t know”:
Student(name='Julia', major='Economics', year='junior', gpa=3.72,\
roll_num="don't know")Suppose you need the following behavior instead: Users are required to use the roll numbers generated by the generate_roll_num function; they should not be able to initialize this field.
So how do we do that?

The field() function also has an init parameter that we can set to False.
from dataclasses import dataclass, field
@dataclass
class Student:
name: str
major: str
year: str
gpa: float
roll_num: str = field(default_factory=generate_roll_num, init=False)Now try initializing the roll_num field by passing in a value to the constructor:
>>> jake = Student('Jake','Math','sophomore',3.33,'MyRollNum')You’ll get the following error:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: __init__() takes 4 positional arguments but 5 were givenThe traceback reads that the constructor takes only four positional arguments; it cannot take in the fifth positional argument corresponding to the roll_num field. So now, the only way to initialize roll_num is to use the generate_roll_num() function. And that’s the behavior we wanted, yes? Great. What’s next?
A Note on Keyword-Only Arguments [In Python 3.10+]
In all the examples thus far, we’ve passed in the values as positional arguments in the constructor.
However, if you want to enforce that the users specify only keyword arguments to instantiate objects, you can set the kw_only parameter in the @dataclass decorator to True. This can help improve readability.
Use __post_init__ to Create Fields Post Initialization
So far, we’ve learned how to use default_factory to generate default values from custom functions, and exclude fields from the constructor by setting init to False. Next, let’s learn how to construct new fields from existing fields.
As a first step, remove the name field and add two new fields, first_name and last_name:
from dataclasses import dataclass, field
@dataclass
class Student:
first_name: str
last_name: str
...Say you’d like to add an email field, a string of the form first_name.last_name@uni.edu (not super fancy, but works!). And we don’t want the users of the class to initialize this field, so we set init=False:
from dataclasses import dataclass, field
@dataclass
class Student:
first_name: str
last_name: str
major: str
year: str
gpa: float
roll_num: str = field(default_factory=generate_roll_num, init=False)
email: str = field(init=False)We know the following:
- To initialize the
emailfield, use thefirst_nameand thelast_namefields. - To ensure users cannot initialize this field, set
init=Falsein thefield()function.

So far so good. But, wait!
We’ll get to know the first_name and the last_name only after the Student object has been instantiated. So when and how do we initialize the email field? Here’s where the __post_init__ method can help.
The __post_init__ special method is called immediately after an object is instantiated. Meaning by the time __post_init__ is called, we already know the first_name and the last_name.
So we can add the __post_init__ method and set the email field:
def __post_init__(self):
self.email = f"{self.first_name}.{self.last_name}@uni.edu"Is the __post_init__ method working as expected? Let’s create a Student object to verify that:
>>> jane = Student('Jane','Lee','Computer Science','senior',3.99)
>>> janeAnd yes! 📧 The email field has been set for the student ‘Jane Lee’:
Student(
first_name="Jane",
last_name="Lee",
major="Computer Science",
year="senior",
gpa=3.99,
roll_num="XAJI0Y6DP",
email="Jane.Lee@uni.edu",
)Order and Sort Data Class Instances
Sorting data class instances on a field can often be helpful. And we’ll learn how to do that.
Let’s add a tuition field to the Student data class, an integer with a default value of 10000:
...
@dataclass
class Student:
first_name: str
last_name: str
major: str
year: str
gpa: float
roll_num: str = field(default_factory=generate_roll_num, init=False)
email: str = field(init=False)
tuition: int = 10000What’s the Goal?
Given a list of instances of the Student data class, we’d like to sort them in the increasing order of tuition. As of now, we don’t quite know how to do that, but we’ll get there soon!
Next, create two Student objects:
jane = Student('Jane','Lee','Computer Science','senior',3.99)
julia = Student('Julia','Doe','Economics','junior',3.63,27000)For jane, the default tuition of 10000 will be used. Let’s try doing julia > jane:
print(julia > jane)We see that the comparison doesn’t make sense as yet:
Traceback (most recent call last):
File "main.py", line 52, in <module>
print(julia > jane)
TypeError: '>' not supported between instances of 'Student' and 'Student'If you remember, data classes come with the __eq__ method that lets us compare two objects for equality of attributes. However, other comparisons between objects are not supported by default. So what’s the plan? 🤔
Enter order and sort_index
To enforce ordering among data class instances, and subsequently, sort them based on a specific field in the data class, you should set order to True in the @dataclass decorator and define a sort_index.
You can add the sort_index field to the data class. And you should see the patterns in the field() function already:
- Users need not initialize the
sort_index, so setinittoFalse. - You can as well exclude the field from the representation string by setting
reprtoFalse.
...
@dataclass(order=True)
class Student:
sort_index:int = field(init=False,repr=False)
first_name: str
last_name: str
major: str
year: str
gpa: float
roll_num: str = field(default_factory=generate_roll_num, init=False)
email: str = field(init=False)
tuition: int = 10000Here again, we’d like to use tuition as the key to sort on, but we’ll get to know the tuition only after the objects are instantiated. And you already know what to do, right? Yeah, use the __post_init__ method. ✅
Just the way you set the email field, you can set the sort _index to tuition in the __post_init__ method, too:
def __post_init__(self):
self.email = f"{self.first_name}.{self.last_name}@uni.edu"
self.sort_index = self.tuitionNow create a few more Student objects:
jane = Student('Jane','Lee','Computer Science','senior',3.99,30000)
julia = Student('Julia','Doe','Economics','junior',3.63,27000)
jake = Student('Jake','Langdon','Math','senior',3.89,28000)
joy = Student('Joy','Smith','Political Science','sophomore',4.00)Collect the instances in a list and call the sort() method on it - just the way you’d sort a list of integers or strings:
instance_list = [jane,julia,jake,joy]
instance_list.sort()Now that we’ve sorted instance_list in place, let’s loop through it and print out only the names of the students and the corresponding tuition:
for instance in instance_list:
print(f"{instance.first_name} {instance.last_name}'s tuition: {instance.tuition}")Well, there you go! The sorting works as expected.
Joy Smith's tuition: 10000
Julia Doe's tuition: 27000
Jake Langdon's tuition: 28000
Jane Lee's tuition: 30000Setting order=True Facilitates Comparison. But How?
We set order=True and specified the sorting index. Somehow the instance list was sorted, based on the tuition field, just the way we wanted. But how did it happen?
To achieve this in a regular Python class, you’ll have to define the comparison methods __gt__, __ge__, __lt__, and __le__. But in a data class, when you set order=True, you get a ready-to-use implementation of these methods.
Let’s go ahead and get the methods associated with the Student data class:
from inspect import getmembers,isfunction
from pprint import pprint
...
pprint(getmembers(Student,isfunction))And we see all the four comparison methods:
[('__eq__', <function __create_fn__.<locals>.__eq__ at 0x01C93CD0>),
('__ge__', <function __create_fn__.<locals>.__ge__ at 0x01C93DA8>),
('__gt__', <function __create_fn__.<locals>.__gt__ at 0x01C93D60>),
('__init__', <function __create_fn__.<locals>.__init__ at 0x01C93BF8>),
('__le__', <function __create_fn__.<locals>.__le__ at 0x01C93D18>),
('__lt__', <function __create_fn__.<locals>.__lt__ at 0x01C93C40>),
('__post_init__', <function Student.__post_init__ at 0x01C93BB0>),
('__repr__', <function __create_fn__.<locals>.__repr__ at 0x01C93C88>)]So for anything we want to do with classes and their instances, data classes come with batteries included? Yeah, it seems safe to say so!
Subclass Data Classes to Extend Functionality
Suppose you need a TA class to store information about students who work as teaching assistants.

Well, TAs are students, too. So each TA object will have all the fields that a Student object has. In addition, let’s say TAs have the following three fields:
coursefor which they work as a teaching assistant,hours_per_week, andstipend.
Instead of creating a new TA data class with the same attributes as the Student data class and a few additional attributes, we can extend the functionality of the Student class using inheritance.
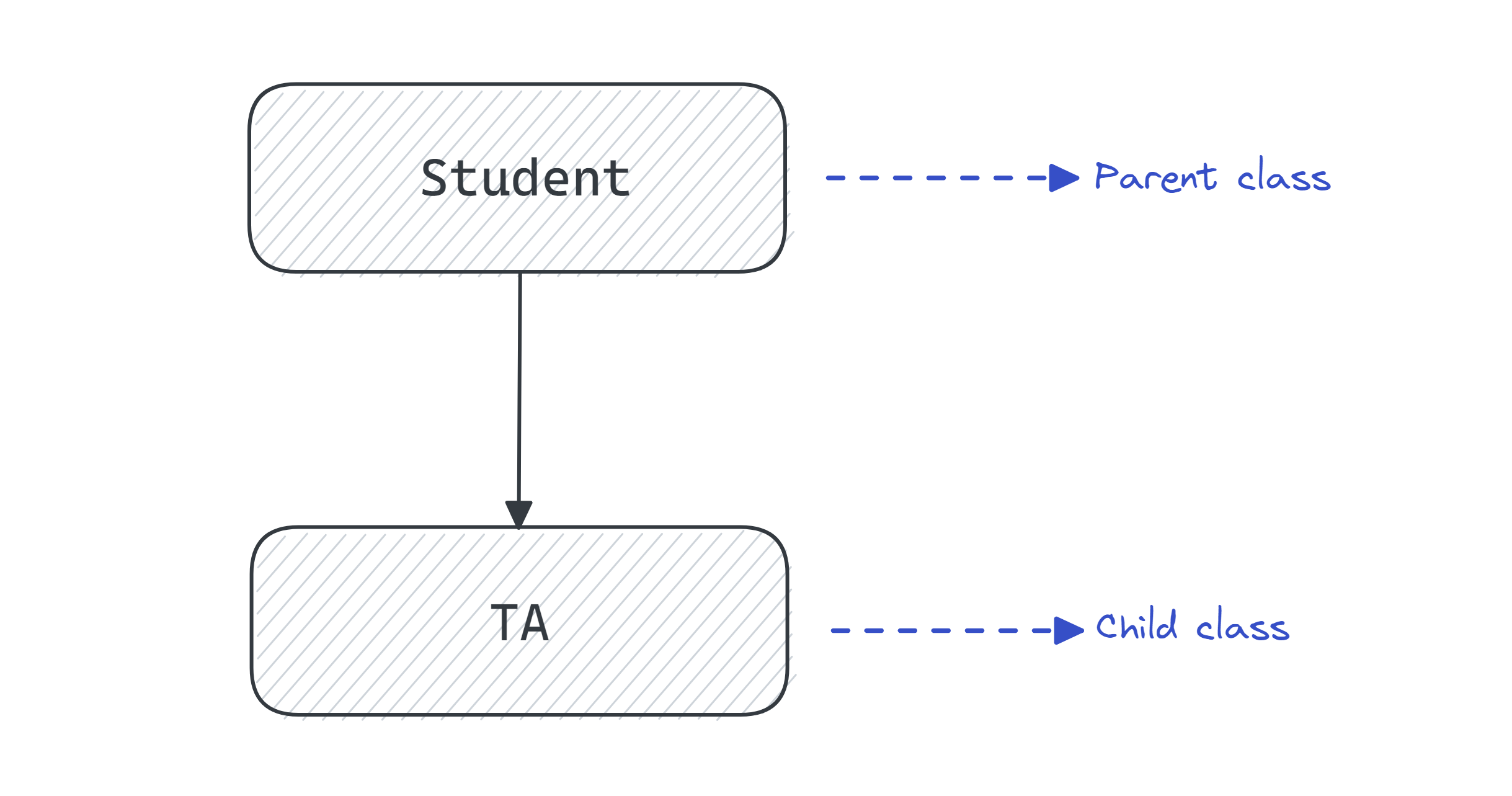
Let’s create a TA subclass that inherits from the Student class:
@dataclass
class TA(Student):
course: str = None
hours_per_week: int = 0
stipend: int = 100We can create TA objects and access the fields:
>>> from main import TA
>>> mia = TA('Mia','Gray','Math','senior',4.00,33000,'Algebra',5,500)
>>> mia.course
'Algebra'
>>> mia.hours_per_week
5
>>> mia.stipend
500📝 What You Should Know About Inheritance and Default Values for Fields
In the TA example, we set default values for all fields in the child class (subclass), so we did not run into errors. But there’s a caveat you should be aware of.
If you remember, when creating a data class, we mentioned that fields with default values should always come after those without default values.
When you create a subclass form an existing data class, the ordering of fields is preserved. Meaning the fields in the parent class come first, followed by the fields in the subclass.
Try removing the default values from the TA subclass:
@dataclass
class TA(Student):
course: str
hours_per_week: int
stipend: int And run the script again:
Traceback (most recent call last):
File "main.py", line 47, in <module>
class TA(Student):
...
raise TypeError(f'non-default argument {f.name!r} '
TypeError: non-default argument 'course' follows default argumentWe get an error as a non-default argument follows a default argument.
Therefore, if the parent data class has default values for one or more fields, all fields in the subclass should have default values, too.
Use Slots for More Efficient Data Classes
📌 This section requires Python 3.10 or later.
We’ll use the following version of the Student data class. The @dataclass decorator takes an optional slots parameter that’s set to False by default.
...
@dataclass(slots=False)
class Student:
first_name: str
last_name: str
major: str
year: str
gpa: float
roll_num: str = field(default_factory=generate_roll_num, init=False)
email: str = field(init=False)
tuition: int = 10000
def __post_init__(self):
self.email = f"{self.first_name}.{self.last_name}@uni.edu"
...All data class instances have a special __dict__ attribute that stores the values of instance variables:
jane = Student('Jane','Lee','Computer Science','senior',3.99,30000)
print(f"Instance variable dict: {jane.__dict__}")Here’s the __dict__ corresponding to jane:
Instance variable dict:{'first_name': 'Jane', 'last_name': 'Lee', 'major': 'Computer Science', 'year': 'senior', 'gpa': 3.99,
'roll_num': 'XAJI0Y6DP', 'email': 'Jane.Lee@uni.edu'}This gives you the flexibility to add instance variables on the go. For example, you can add a watches_anime field to jane like so: jane.watches_anime = True.
But dictionaries take up memory. This is not a problem when you have fewer attributes and don’t need to create too many data class instances. But it can be impactful when you need to create a large number of instances.
Can we do something so that this __dict__ attribute is no longer created for data class instances? That way, we won’t run into memory issues. Glad you asked.
Enter __slots__
When you know that the data class instances always have a fixed set of attributes, you can use __slots__ to store the values in slots instead of in dictionaries. So when you use __slots__, the __dict__ is no longer created. Rather, the instance variables are now treated as properties.
So how does using __slots__ help?1 Well, you get the following advantages :
- Substantially low memory footprint as the
__dict__is not created for instances - Marginal improvement in attribute access speed
To use slots, you need to set slots to True in the @dataclass decorator2:
...
@dataclass(slots=True)
class StudentSlots:
first_name: str
last_name: str
major: str
year: str
gpa: float
roll_num: str = field(default_factory=generate_roll_num, init=False)
email:str = field(init=False)
tuition:int = 10000
def __post_init__(self):
self.email = f"{self.first_name}.{self.last_name}@uni.edu"
...Comparing Memory Footprint
🧩 What I Learned About sys.getsizeof()
I’ve (almost always) used sys.getsizeof() to get size of objects in Python. But only recently I learned that it does not account for the sizes of objects that are referenced inside the specific object. Let me explain this with a simple example.
Suppose you have three Python dictionaries of the following form:

Let’s create three super simple dictionaries that take the above form:
>>> dict_1 = {"key1": "value1"}
>>> dict_2 = {"key1": {"key2": "value2"}}
>>> dict_3 = {"key1": {"key2": {"key3": "value3"}}}You’d expect the above dictionaries to have different sizes given that dict_2 and dict_3 reference dictionaries within them. However, sys.getsizeof() views them as dictionaries containing a single key-value pair. Which is technically right, though!
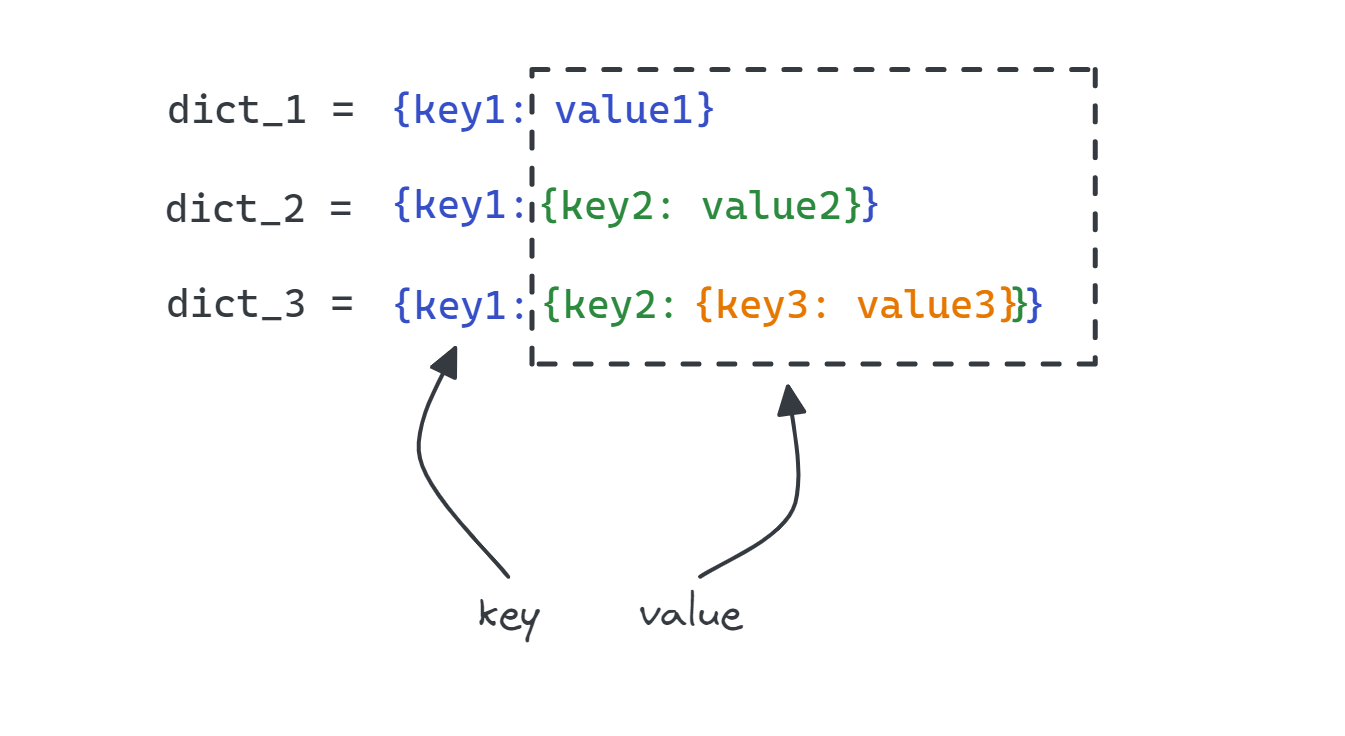
So we get the same size for the three objects:
>>> import sys
>>> sys.getsizeof(dict_1)
128
>>> sys.getsizeof(dict_2)
128
>>> sys.getsizeof(dict_3)
128We’ll not use sys.getsizeof() to compute the sizes of instances of Student and StudentSlots data classes. But you can go ahead and try the following if you’d like:
jane_slots = StudentSlots('Jane','Lee','Computer Science','senior',3.99,30000)
jane = Student('Jane','Lee','Computer Science','senior',3.99,30000)Now use sys.getsizeof() to get the size of the jane and jane_slots objects:
import sys
print(f"sys.getsizeof(jane):{sys.getsizeof(jane)}")
print(f"sys.getsizeof(jane_slots):{sys.getsizeof(jane_slots)}")In this case, the data class instance with slots seems to take up more memory, which contradicts our memory savings claim.
sys.getsizeof(jane):48
sys.getsizeof(jane_slots):104This can be attributed to how sys.getsizeof() calculates object sizes — without taking into account the referenced objects.
Pympler, another Python package, provides functionality to compute the approximate sizes of the object in memory. The asizeof() function in Pympler’s asizeof module tries to recursively add up the sizes of the objects referenced within an object, and returns the approximate size of the object in bytes.
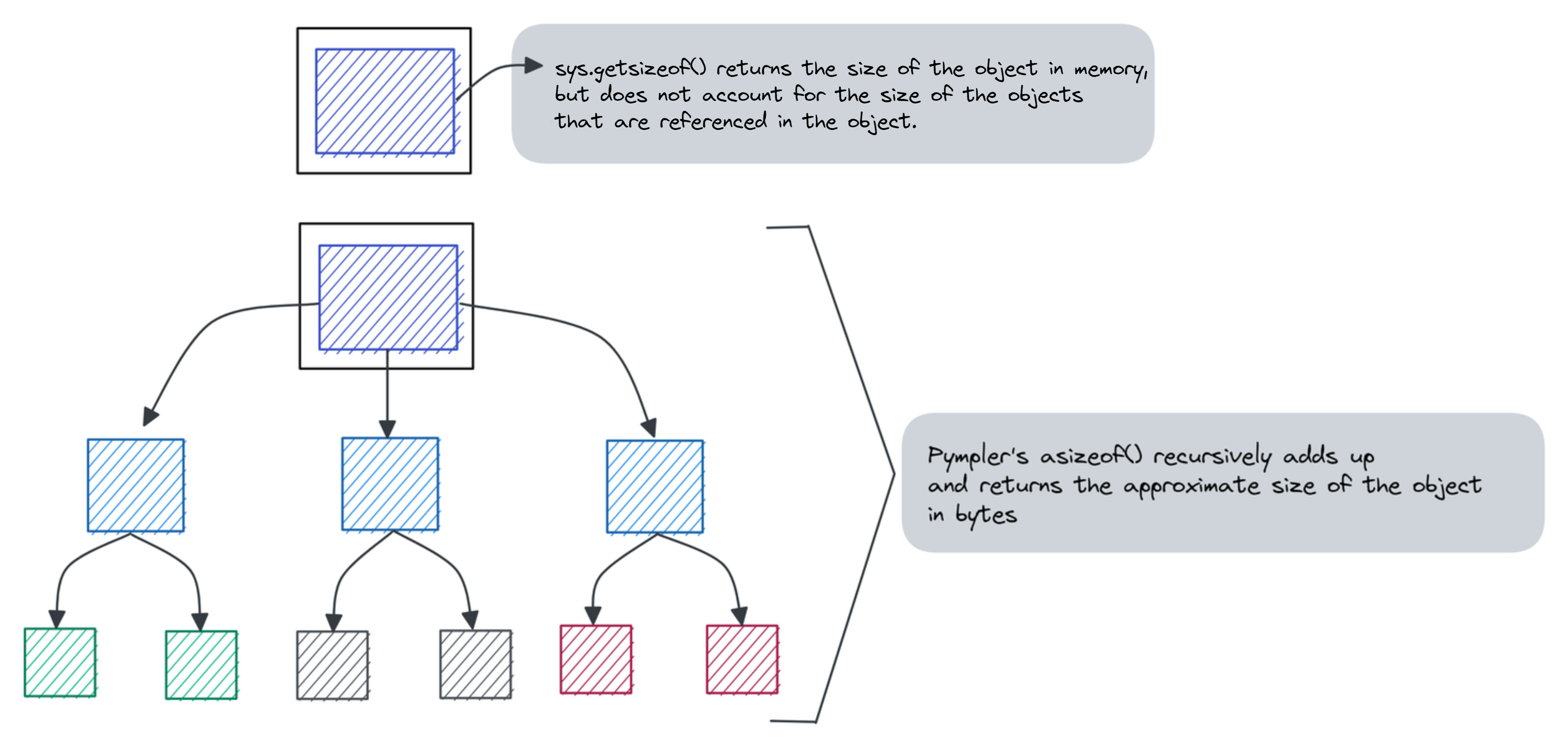
You can install pympler package using pip:
$ pip3 install pymplerLet’s create two objects jane_slots and jane of the StudentSlots and Student data classes, respectively:
jane_slots = StudentSlots('Jane','Lee','Computer Science','senior',3.99,30000)
jane = Student('Jane','Lee','Computer Science','senior',3.99,30000)We’ll use the asizeof() function from pympler’s asizeof module to get the sizes of the objects with and without slots:
from pympler.asizeof import asizeof
s1 = asizeof(jane_slots)
s2 = asizeof(jane)
print(f"Size of `jane` with slots: {s1}")
print(f"Size of `jane` without slots: {s2}")
print(f"% Savings in memory: {(s1 - s2)/s2*100:.2f}")For this example, we get 51.09% memory savings, which is substantial:
Size of `jane` with slots: 536
Size of `jane` without slots: 1096
% Savings in memory: 51.09It’d be interesting to see how the memory saving scales with increasing number of attributes in the data class.
Comparing Attribute Access Times
We have jane_slots and jane, Student objects created from data class with and without __slots__, respectively. To verify if attribute access is faster, we define a simple function get_set_del() that sets the value of a field, reads it, and deletes it.
from functools import partial
import timeit
def get_set_del(student):
student.first_name="Hello"
student.first_name
del student.first_nameWe’ll use timeit to measure the access times with and without slots. Once we get the access times, we can compute the percentage improvement in speed.
t1=min(timeit.repeat(partial(get_set_del,jane_slots)))
t2=min(timeit.repeat(partial(get_set_del,jane)))
print(f"Access time with slots: {t1:.2f}")
print(f"Access time without slots: {t2:.2f}")
print(f"% Improvement: {(t2-t1)/t2*100:.2f}")I’m running Python 3.10.8 on Ubuntu 22.04 LTS, and the results suggest that the attribute access — with slots — is about 28.71% faster.
Access time with slots: 0.08
Access time without slots: 0.11
% Improvement: 28.71Cool, the memory savings and attribute access times when using data classes with slots seem promising! Be sure to try out for a few different classes to understand performance gains.
Conclusion
And that’s a wrap! In this second (and final part) of the data classes tutorial series, we covered the __post_init__ method, how inheritance works in data classes, and performance gains using __slots__.
So did we cover everything about data classes? No. But what you’ve learned should help you hit the ground running when you start writing functional data classes. With less boilerplate code to write and promising performance gains, switching to data classes can save you hours per week.
And one last thins: As you continue to build your Python projects, you might want to consider making your build automation more efficient with Earthly. It’s a tool that can help streamline your build process and ensure consistency across different environments.
See you all soon in another tutorial. Until then, happy coding!
Earthly makes CI/CD super simple
Fast, repeatable CI/CD with an instantly familiar syntax – like Dockerfile and Makefile had a baby.
I found this StackOverFlow discussion thread super helpful to learn about
__slots__. I recommend reading through it to further your understanding of__slots__.↩︎When you set
slotstoTrue, you can no longer add instance attributes on the fly. But you can instead set__slots__manually and add a__dict__(in addition to the names of instance variables) to dynamically add fields. The memory footprint savings in this case may be lower.↩︎







