
What Are Python Data Classes?

We’re Earthly. We make building software simpler and faster with containerization. Earthly can help manage and automate your Python project’s build process. Check it out.
In Python, classes let you group data and behavior together by defining attributes and methods, respectively. Typically, a class contains both attributes and a set of methods that add functionality. But what if you have a class that stores a lot of attributes with almost no functionality? Do you still need to use regular classes, or is there a better alternative?
Data classes, first introduced in Python 3.7, provide a convenient way of defining and managing such data-oriented classes (who would’ve guessed!).
If you already have a Python class that exposes a lot of methods, you don’t need a data class. However, if you’re interested in learning about this new feature to manage your data-oriented classes better, then this tutorial is for you.
You’ll learn the basics of data classes and how they’re different from regular Python classes. In addition, you’ll learn how data classes support type hints, default values beyond basic data types, immutability, and more.
Let’s get started!
📑 Before You Begin
To follow along, you need Python 3.7 or a later version installed in your preferred development environment. You can find the code examples used here in this GitHub repository.
This tutorial assumes you’re familiar with the working of Python classes and objects.
Python Classes and Boilerplate Code
You’ll first create a regular Python class. In doing so, you’ll realize how much boilerplate code you need to write to get a minimal working class. You’ll then rewrite the existing Python class as a data class to understand how data classes can help you escape the monotony of boilerplate code.
As our goal is to understand and use data classes — and not to write fancy classes — let’s create a simple class such as a Student or an Employee class.
So which class do we pick: Student or Employee?

I’ll choose Student class for now. Let’s get coding!
The __init__ Method
Let’s create a Student class with the attributes: name, roll_no, major, and year. To initialize instances of the Student class by passing in values for these attributes in the constructor, you can define the __init__ method:
# main.py
class Student:
def __init__(self, name, roll_no, major, year):
self.name = name
self.roll_no = roll_no
self.major = major
self.year = yearNow that you’ve created the Student class, start a Python REPL, import the Student class, and create a student object jane:
>>> from main import Student
>>> jane = Student('Jane','CS1234','Computer Science','junior')You inspect this object jane at the REPL:
>>> jane
<main.Student object at 0x007EE628>As seen, the default representation returned <main.Student object at 0x007EE628> is not very helpful; it does not contain any information on the attributes of the instance jane. If you need a helpful string representation of the object, you should implement the __repr__ method.
Adding a Helpful __repr__
Let’s add a __repr__ method that returns a string containing the values of the instance attributes:
def __repr__(self):
return f"Student: {self.name} {self.roll_no} {self.major} {self.year}"After adding the __repr__, the Student class should look like this:
# main.py
class Student:
def __init__(self, name, roll_no, major, year):
self.name = name
self.roll_no = roll_no
self.major = major
self.year = year
def __repr__(self):
return f"Student: {self.name} {self.roll_no} {self.major} {self.year}"Now go back to the REPL and look at the __repr__ for jane:
>>> jane
Student: Jane CS1234 Computer Science juniorThat’s much better!
But remember, you added the __repr__ method. So it’s only as helpful as you choose to make it. You can as well write a __repr__ that only returns the string “Student object”. Clearly, such a __repr__ is not more helpful than the default <main.Student object at 0x007EE628> (just saying!).
Next, create another instance of the Student class also_jane with the same values for the instance attributes:
>>> also_jane = Student('Jane','CS1234','Computer Science','junior')You can verify the equality of the various attributes of jane and also_jane, like so:
>>> jane.name == also_jane.name
True
>>> jane.roll_no == also_jane.roll_no
True
>>> jane.major == also_jane.major
True
>>> jane.year == also_jane.year
TrueBut what happens when you try to compare jane and also_jane?
>>> jane == also_jane
FalseWell, jane == also_jane returns False. Why?

By default, the == operator compares the IDs of the two objects. And comparison of objects in terms of attributes doesn’t make sense until you implement the __eq__ method. Okay, let’s do that!
Implementing the __eq__ Method
For now, we know the following:
- Comparison is valid only between two objects belonging to the same class.
- The values of the various instance variables of the two objects should be equal.
Let’s define the __eq__ method to compare any two instances of two instances of the Student class:
def __eq__(self, another):
if self.__class__ == another.__class__:
return (self.name, self.roll_no, self.major, self.year) == (
another.name,
another.roll_no,
another.major,
another.year,
)
else:
return "InvalidComparison"Instead of the “InvalidComparison” string, you can also return NotImplemented. If you do so, when you try to compare two objects of different classes, you’ll be notified that the __eq__ method for such comparisons has not been implemented.
When you try to check if jane == also_jane after adding the __eq__ method, you’ll see that it evaluates to True as expected:
>>> jane == also_jane
TrueTo create the Student class with four attributes, a helpful string representation, and support for object comparison, we have the following in main.py:
# main.py
class Student:
def __init__(self, name, roll_no, major, year):
self.name = name
self.roll_no = roll_no
self.major = major
self.year = year
def __repr__(self):
return f"Student: {self.name} {self.roll_no} {self.major} {self.year}"
def __eq__(self, another):
if self.__class__ == another.__class__:
return (self.name, self.roll_no, self.major, self.year) == (
another.name,
another.roll_no,
another.major,
another.year,
)
else:
return "InvalidComparison"Did we work extra hard here? No, we didn’t.
(Almost) all of this is boilerplate code that you’ll write whenever you create a Python class.
Now suppose you need to add the GPA for each student, remove the name attribute and add two new attributes: first_name and last_name, the list of classes each student has taken, and a bunch more.
What should you do?
- You need to first update the
__init__method. Cool. - How’ll you remember the newly added attributes if you don’t add them to the
__repr__? Okay, so you’ll go and modify the__repr__. - Oh wait, you should update the
__eq__method, too.
Clearly, it’s not super fun anymore!

And as you keep modifying the class, you’ll likely forget to update one of these. No, I’m not challenging you!
Now let’s rewrite the Student class as a data class (and see if it’ll make things easier for us!). You may delete all the existing code in main.py.
How to Create Data Classes in Python
To create a data class, you can use the @dataclass decorator from Python’s built-in dataclasses module. You can specify the name of the class and list the fields along with their type annotations as shown:
from dataclasses import dataclass
@dataclass
class Student:
name: str
roll_no: str
major: str
year: str
gpa: floatAt first look, this version of the Student class is easy to read and the type hints indicate the expected data types for each field. There’s no __init__ method or any of the other methods that we added for the regular class. That’s it! Your Student data class is ready and you can proceed to instantiate objects of this data class.
Now, let’s run through the same steps that we did for the regular Student class.
Import the Student data class and instantiate the student object jane:
>>> from main import Student
>>> jane = Student('Jane','CS1234','Computer Science','junior',3.98)We see that we get a helpful string representation—without implementing a __repr__():
>>> jane
Student(name='Jane', roll_no='CS1234', major='Computer Science', year='junior',↩
gpa=3.98)What about comparison of objects? Let’s instantiate another also_jane and try checking if jane == also_jane as before:
>>> also_jane = Student('Jane','CS1234','Computer Science','junior',3.98)
>>> jane == also_jane
TrueWe see that the comparison returns True (as expected). But we did not write the __eq__ method either.
Where Did __init__ and Other Methods Come From?
To reiterate, we did not write even the class constructor __init__ method; we only specified the fields and the expected data types as type hints in the data class definition.
So where did the __init__, __repr__, and __eq__ methods come from?

Well, with data classes, you get a default implementation of these methods.
You can use built-in functionality from the inspect module to get all the member functions implemented for the Student data class:
# main.py
from inspect import getmembers,isfunction
from pprint import pprint
...
pprint(getmembers(Student,isfunction))[('__eq__', <function __create_fn__.<locals>.__eq__ at 0x014F6A48>),↩
('__init__', <function __create_fn__.<locals>.__init__ at 0x014F6970>),↩
('__repr__', <function __create_fn__.<locals>.__repr__ at 0x014F6A00>)]To sum up: Python data classes have implementations of the __init__, __repr__, and __eq__ methods.
Create Data Classes With make_dataclass
To create a data class, you can also use the make_dataclass constructor from the dataclasses module:
from dataclasses import make_dataclass
Student = make_dataclass('Student',['name','roll_no','major','year','gpa'])However, I prefer using the @dataclass decorator; the code is a lot easier to read and maintain, especially when there are many fields.
Type Hints and Default Values in Python Data Classes
We’ve specified type hints for all the fields in the data class. However, Python is a dynamically typed language, so it does not enforce types at runtime.
In main.py, let’s create an instance of the Student data class with invalid types for one or more fields:
from dataclasses import dataclass
@dataclass
class Student:
name: str
roll_no: str
major: str
year: str
gpa: float
julia = Student('Julia',0.5,'Statistics','sophomore','who cares!')Let’s zoom into julia = Student('Julia',0.5,'Statistics','sophomore','who cares!'):
- The
roll_nofield is expected to be astr, but I’ve set it to 0.5, which is offloatdata type. - The
gpafield should be afloat, but I’ve set it to thestr‘who cares!’.
If you (re)run main.py, you’ll not run into any errors. And if you look at the object julia at the REPL, you’ll see that roll_no and gpa have been assigned values 0.5 and ‘who cares!’, respectively; they’re not flagged for invalid data type.
>>> julia
Student(name='Julia', roll_no=0.5, major='Statistics', year='sophomore',↩
gpa='who cares!')So are type hints useless still helpful?
How Do Type Hints Help?
When you add type hints, the IDE or code editor can be configured to provide hints to help you use the right data types for the fields.
I’m using VS Code. As you can tell, I set the roll_no field to 0.5 even when I was hinted to use a str:
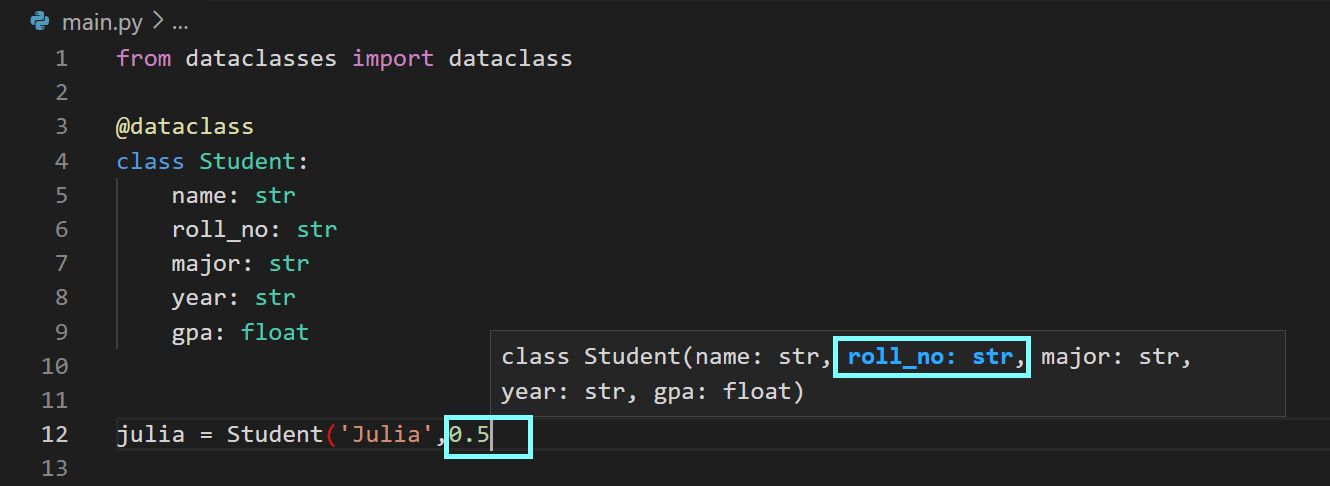
Similarly, I set the gpa field to ‘who cares!’ while knowing that gpa should be a float:
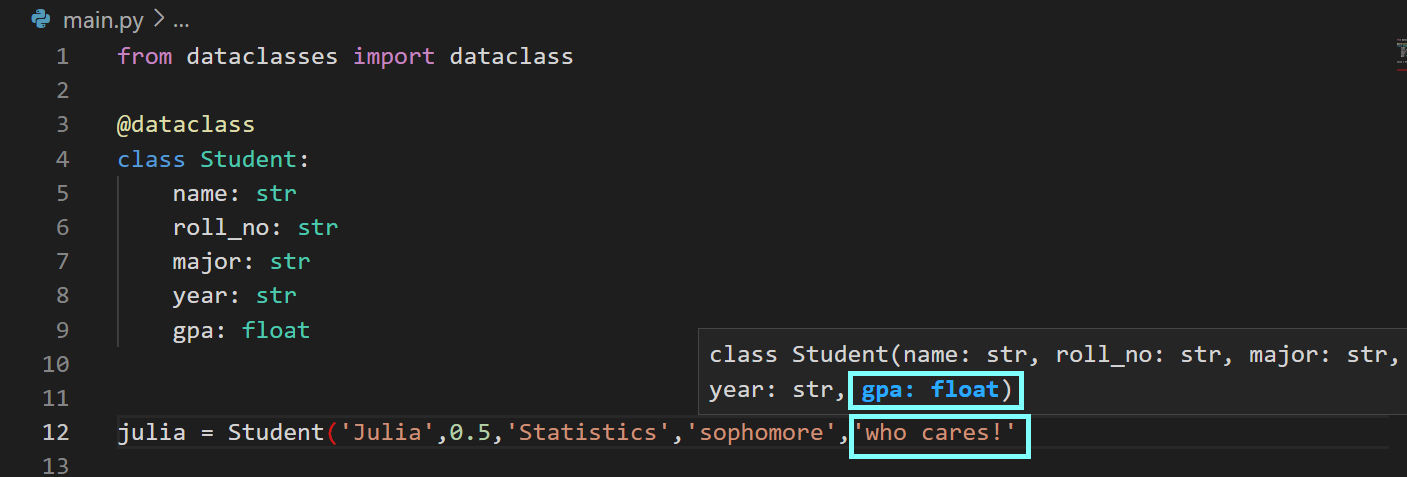
But why did I do that? Well, only to let you know that the type hints have no effect at runtime. But without the type hints, you wouldn’t know if you’re unintentionally using an incorrect data type.
Enforcing Type Checks
If you’d like to enforce types and get errors for mismatched data types, you can use a static type checker like mypy. You can install mypy using pip:
$ pip3 install mypyAfter you’ve installed mypy, you run type checks by running mypy script_name at the terminal:
$ mypy main.pyIn main.py, we have the instantiation of julia on line 11. mypy flags both Argument 2 (0.5 for roll_no) and Argument 5 (‘who cares!’ for gpa) for incompatible type:
main.py:11: error: Argument 2 to "Student" has incompatible type "float";↩
expected "str" [arg-type]
main.py:11: error: Argument 5 to "Student" has incompatible type "str";↩
expected "float" [arg-type]
Found 2 errors in 1 file (checked 1 source file)Setting Default Values for Data Class Attributes
In a regular Python class, you can provide default values for fields in the __init__() method definition. Doing so, you can make certain fields optional when instantiating objects.
Data classes give this flexibility, too. However, you should be aware of caveats such as setting mutable defaults for fields.
⚠️ The Curious Case of Mutable Default Arguments in Python

Consider the following function add_to_reading_list:
>>> def add_to_reading_list(item,this_list=[]):
... if item not in this_list:
... this_list.append(item)
... return this_list
...It takes in one required positional argument item and optionally a list. When you provide both the item and the list in the function call, the function works as expected, returning a list where item is appended to the end of the list:
>>> books = ['Deep Work']
>>> new_book = 'Hyperfocus'
>>> add_to_reading_list(new_book,books)
['Deep Work', 'Hyperfocus']If you don’t have a reading list, you’re adding an item to an empty list. So the function add_to_reading_list should return a list containing one item, namely, the item, yes? Well, that’s the behavior you’d expect.
However, default arguments are bound to the function—only once—at the time of defining the function.
Therefore, when you don’t pass in the list in the function call, you’ll see that the same list is modified in each function call. And a new empty list is not created for each function call that does not contain the list argument:
>>> add_to_reading_list('Mindset')
['Mindset']
>>> add_to_reading_list('Grit')
['Mindset', 'Grit']
>>> add_to_reading_list('Flow')
['Mindset', 'Grit', 'Flow']❗ This is why you should avoid using mutable defaults in Python.
Let’s add a classes field, a list of classes that a student has signed up for. If a student hasn’t signed up for classes as yet, classes should be initialized to an empty list. But setting classes to the literal [], as shown here, won’t work.
# main.py
from dataclasses import dataclass
@dataclass
class Student:
name: str
roll_no: str
major: str
year: str
gpa: float
classes: list = []Luckily, data classes do not allow you to define mutable defaults such as lists and dictionaries. And you’ll get a ValueError:
Traceback (most recent call last):
File "main.py", line 3, in <module>
class Student:
…
ValueError: mutable default <class 'list'> for field classes is not allowed:↩
use default_factoryThe above traceback provides helpful information on what needs to be fixed and how you can fix it:
- The problem: Mutable default
- The solution: Use
default_factory
The field() function in the dataclasses module lets you set default values, exclude certain fields from comparison, string representation, and more. One of the options the field() function takes is default_factory, which is any Python callable that’s called every time a new instance is created.
So we can set default_factory to list. I’ve also set compare = False to exclude the classses field from comparison:
# main.py
from dataclasses import dataclass,field
@dataclass
class Student:
name: str
roll_no: str
major: str
year: str
gpa: float
classes: list = field(default_factory=list,compare=False)Now that we’ve set default_factory to the callable list, a new empty list is created—every time an instance of Student data class is created—to set the default value for the classes field.
We pass in the classes list when instantiating julia and do not pass in for jane:
# main.py
...
julia = Student('Julia',0.5,'Statistics','sophomore','who cares!',['Statistics↩
101','Graph theory','Real analysis'])
print(julia)
jane = Student('Jane','CS1234','Computer Science','junior',3.98)
print(jane)In the output, we see that the provided and default (empty) lists are used for julia and jane, respectively:
Student(name='Julia', roll_no=0.5, major='Statistics', year='sophomore',↩
gpa='who cares!', classes=['Statistics 101', 'Graph theory', 'Real analysis'])
Student(name='Jane', roll_no='CS1234', major='Computer Science', year='junior',↩
gpa=3.98, classes=[])⚠️ Specify Default Fields After Non-Default Fields
As with arguments in a function call, data classes should include the fields without default values first, followed by the ones with default values.
Here’s an example. Coordinate3D is a data class that stores the location of a point (x,y,z) in 3D space:
from dataclasses import dataclass
@dataclass
class Coordinate3D:
x: float
y: float
z: floatSuppose you’d like the point to be the origin when none of the coordinates x, y, and z are mentioned when creating an instance. For this to happen, we set 0.0 as the default value of all the three coordinates x, y, and z:
from dataclasses import dataclass
@dataclass
class Coordinate3D:
x: float = 0.0
y: float = 0.0
z: float = 0.0
origin = Coordinate3D()
print(origin)And it works as expected; origin is (0.0,0.0,0.0):
Coordinate3D(x=0.0, y=0.0, z=0.0)Suppose we want the point to lie in the YZ-plane (where x = 0) when the x coordinate is not specified. We don’t need defaults for y and z, but now x takes a default value of 0.0:
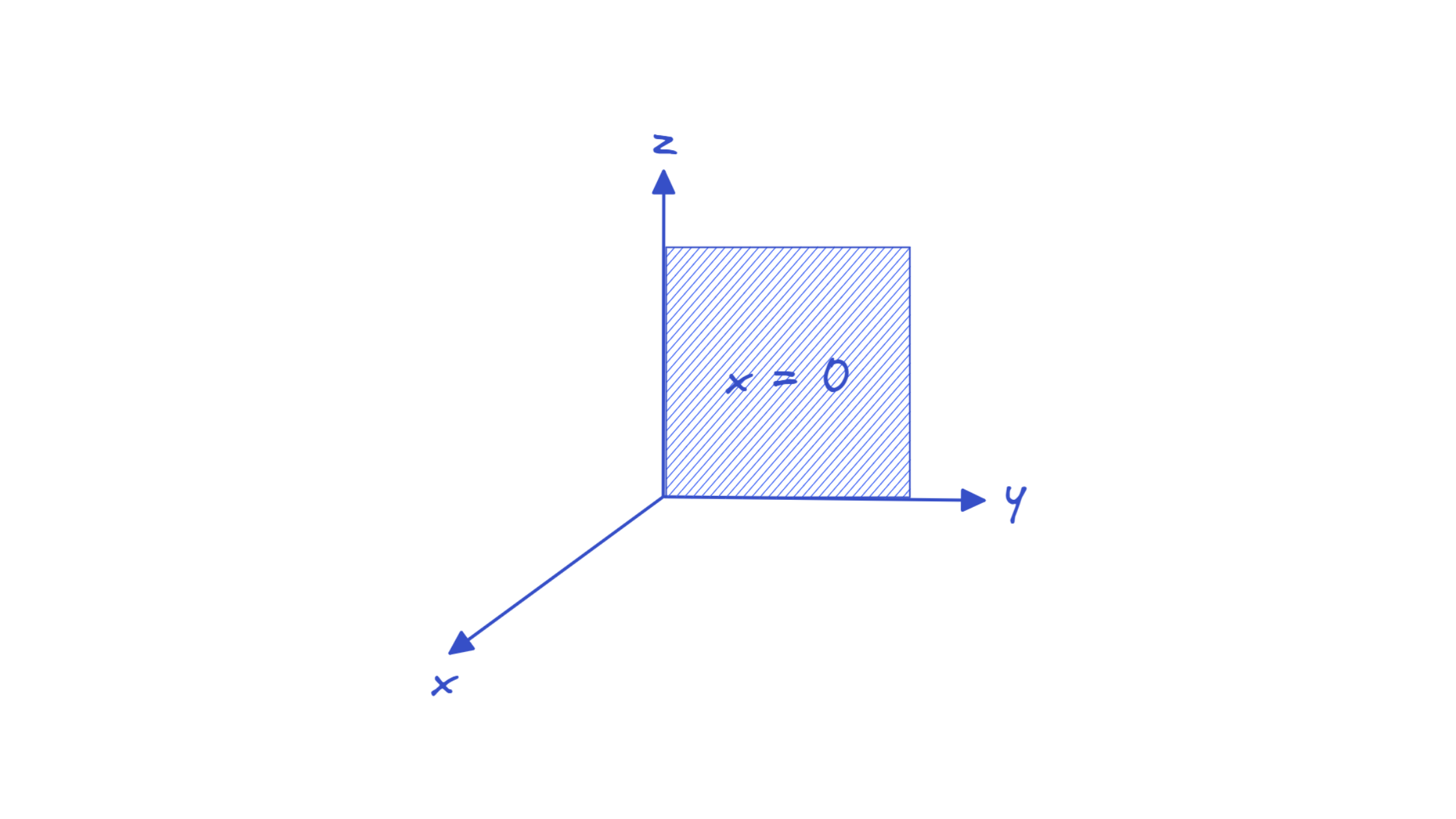
If you do the following, you’ll run into an error:
from dataclasses import dataclass
@dataclass
class Coordinate3D:
x: float = 0.0
y: float
z: float
origin = Coordinate3D()
print(origin)The error is due to y, a non-default field, following x, a field with default value:
Traceback (most recent call last):
File "main.py", line 4, in <module>
class Coordinate3D:
...
TypeError: non-default argument 'y' follows default argumentTo fix the error, simply move x as the last field in the class definition:
from dataclasses import dataclass
@dataclass
class Coordinate3D:
y: float
z: float
x: float = 0.0
point_yz = Coordinate3D(1.5,3)
print(point_yz)Now we don’t run into errors and the default value of 0.0 has been used for x:
Coordinate3D(y=1.5, z=3, x=0.0)Are Immutable Data Classes Helpful?
By default, all data class instances are mutable. Meaning you can modify the values of one or more fields after the instance is initialized.
Let’s update the gpa field of julia to 3.33 (a valid GPA this time):
# main.py
...
julia.gpa = 3.33
print(julia)The gpa field is now set to 3.33:
Student(name='Julia', roll_no=0.5, major='Statistics', year='sophomore',↩
gpa=3.33, classes=['Statistics 101', 'Graph theory', 'Real analysis'])However, it can sometimes be helpful to have immutable instances:
- It prevents accidental modification of one or more instance fields.
- Immutable instances can be hashed by default. Therefore, this is helpful if you’d like to use the instance fields as keys of a dictionary or later dump it into a JSON string.
To make instances immutable, set the frozen parameter in the @dataclass decorator to True.
# main.py
from dataclasses import dataclass,field
...
@dataclass(frozen=True)
class Student:
name: str
roll_no: str
major: str
year: str
gpa: float
classes: list = field(default_factory=list)
...
julia = Student('Julia',0.5,'Statistics','sophomore','who cares!',↩
['Statistics 101','Graph theory','Real analysis'])
...
julia.gpa = 3.39
print(julia)If you now try to update the gpa field as shown, you’ll run into a FrozenInstanceError exception:
Traceback (most recent call last):
File "main.py", line 18, in <module>
julia.gpa = 3.39
File "<string>", line 4, in __setattr__
dataclasses.FrozenInstanceError: cannot assign to field 'gpa'Defining Methods in a Python Data Class
Python data classes are classes, too. So you can define methods. Let’s add a simple method some_method() that prints out a statement:
# main.py
from dataclasses import dataclass,field
@dataclass()
class Student:
name: str
roll_no: str
major: str
year: str
gpa: float
classes: list = field(default_factory=list)
def some_method(self):
return f"I'm an instance method in {self.__class__.__name__} data class; here for some reason. :)"
...
julia = Student('Julia',0.5,'Statistics','sophomore','who cares!',↩
['Statistics 101','Graph theory','Real analysis'])
...
print(julia.some_method())You can now access some_method() by calling it on any instance of the Student data class. Here, we’ve called it on julia:
I'm an instance method in Student data class; here for some reason. :)If you try to inspect the member functions of the Student class (again):
# main.py
...
pprint(getmembers(Student,isfunction))You’ll see that some_method() has also been included in the list:
[('__eq__', <function __create_fn__.<locals>.__eq__ at 0x019B6B20>),
('__init__', <function __create_fn__.<locals>.__init__ at 0x019B69B8>),
('__repr__', <function __create_fn__.<locals>.__repr__ at 0x019B68E0>),
('some_method', <function Student.some_method at 0x019B6928>)]🔖Data classes don’t provide an implementation of the __str__ method (falls back to __repr__ which is always implemented for a data class). If you’d like, you can add a __str__ for users of the class instead of some_method().
Though you can add methods to the data class, if you find yourself adding too many methods, you should consider rewriting the data class as a regular Python class instead.
Conclusion
This tutorial provided insights into Python data classes, including their creation, setting default values, relevance of type hints, and immutable instances. You are now ready to refactor data-oriented Python classes into data classes.
The next piece expands on inheritance and performance optimizations in Python 3.10. Keep coding!
If you enjoyed streamlining your Python classes, you might want to streamline your builds next - check out Earthly. It’s a tool that can help you automate and optimize your build processes, much like how data classes can optimize your Python code.
Earthly makes CI/CD super simple
Fast, repeatable CI/CD with an instantly familiar syntax – like Dockerfile and Makefile had a baby.







