
A Developer’s Guide to Kubernetes Services

We’re Earthly. We make building software simpler and therefore faster. This article is about when to reach for Kubernetes services. If you are looking for a simpler approach to building services then check us out.
Kubernetes is a tool for managing containerized applications, designed to make it easy to deploy and scale applications. It is designed to work with a variety of container technologies like Docker and containerd. In a Kubernetes cluster, your application runs in a Pod. In Kubernetes, Pods are ephemeral; they are temporary resources which are created and destroyed as needed .
When pods need to interact with other resources in a Kubernetes cluster, they can use the IP addresses provided by the cluster. However, this approach has the drawback of requiring developers to manually configure the IP addresses for each pod. Because Pods are temporary resources in a cluster, it is practically impossible to configure IP tables whenever a new Pod is created or destroyed. As a result, it is challenging for Pods to communicate with one another using IP addresses.
To solve this problem, Kubernetes has a resource called Service, which gives the Pod a stable IP address to solve this communication issue—making interaction with other Pods considerably more reliable. Services provide a way to expose applications running on a Kubernetes cluster to the outside world. They also allow for load balancing and for routing traffic to the correct application instance. Services can be exposed using a variety of methods, such as a load balancer or an Ingress resource.
In this guide, you’ll learn about Services and its types in Kubernetes, and how to define them using YAML files. By the end of the article, you’ll have a good understanding of Services in Kubernetes.
An Overview of ReplicaSets in Kubernetes
We’ll use ReplicaSets in this tutorial. ReplicaSets are Pod Controllers in Kubernetes, they are used to make the pods fault tolerant by making it easy for them to easily scale up and down. Replicaset ensures that a specific number of Pods(replicas) keep running in the cluster. To make a ReplicaSet, create a new file my-replicaset.yml and populate it with the following configuration:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: my-replicaset
spec:
replicas: 3
selector:
matchLabels:
app: my-pod
template:
metadata:
labels:
app: my-pod
spec:
containers:
- name: my-server
image: nginx
ports:
- containerPort: 80Let’s go through the contents of the above YAML file:
The first line,
apiVersion: apps/v1, specifies the version of the Kubernetes API that should be used to interpret this YAML file.The second line,
kind: ReplicaSet, specifies the type of object that this YAML file describes. In this case, it specifies that the file describes a ReplicaSet object.The
metadatasection provides metadata about the ReplicaSet object. Here, it specifies that the ReplicaSet should be named “my-replicaset”.The
specsection specifies the details of the ReplicaSet. Here, the ReplicaSet should manage three replicas of the pod, and that the pod should be selected based on the “app” label being set to “my-pod”.The
templatesection specifies the details of the pod that the ReplicaSet will manage. The pod should have theapp: my-podlabel and it should contain a container namedmy-serverbased on thenginximage.The
containerPortfield in thespecsection specifies the port from which the pod can be reached from inside the cluster.
To create the ReplicaSet, open your terminal and run kubectl create -f my-replicaset.yml. Running this command should produce the following output.
replicaset.apps/my-replicaset createdTypes of Services in Kubernetes

Kubernetes offers four primary service types that are each beneficial for a certain task. The following services are covered in more detail below:
- ClusterIP Service
- Headless Service
- NodePort Service
- Load Balancer Service
ClusterIP Services
A ClusterIP service is a type of service that can be used to expose instances of pods running on the Kubernetes cluster. Each pod has a single IP address that is used by the ClusterIP service to route traffic to and from that pod. A ClusterIP Service is the default service; if you don’t specify the type attribute in the YAML file, then Kubernetes will create a ClusterIP service automatically.
To create a ClusterIP service, create a YAML file and add the following configuration:
apiVersion: v1
kind: Service
metadata:
name: rs-service
spec:
ports:
- protocol: TCP
port: 80
targetPort: 80
selector:
app: my-podLet’s parse the contents of the YAML file:
apiVersiondefines the version to be used. The API version must support this kind of resource.kindspecifies the resource type you’re creating in k8s.metadatais another mandatory field which provides the resource’s fundamental details. In this example, you only enter the resource’s name, but you may also include labels and annotations.- The final mandatory part,
spec, describes the requirements for the resources. Each resource has unique specifications. spec.ports.portspecifies the port which should be made an endpoint in the cluster; port can take any arbitrary value.spec.ports.targetPortidentifies the port that the Pod opens.spec.selectorhelps the Service to identify the Pods to which the request should be forwarded to. The Service will send requests to only those Pods which have a label ofapp: my-pod.
To create a new service resource, type kubectl create -f rs-svc.yml into your console with the rs-svc.yml file containing the above configuration. Kubernetes creates an endpoint resource when the service is created that lists all the endpoints to which requests should be directed.
$ kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 192.168.49.2:8443 105d
rs-service 172.17.0.5:80,172.17.0.6:80,172.17.0.7:80 111sIn the above example, you have three endpoints which correspond to the number of Pods in the ReplicaSet. Note that these endpoints are internal to the cluster. This means only the service can access the Pod using these endpoints but the end user cannot.
You can check detailed information about the Service by running kubectl describe -f rs-svc.yml, which produces the following output:
Name: rs-service
Namespace: default
Labels: <none>
Annotations: <none>
Selector: app=my-pod
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.103.78.229
IPs: 10.103.78.229
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 172.17.0.5:80,172.17.0.6:80,172.17.0.7:80
Session Affinity: None
Events: <none>In the above output, you can see all the Events, IPs, Type, and Selector at one place. This is helpful when you have to examine your Service thoroughly.
To check all the current services running in your cluster type kubectl get svc:
$ kubectl get svc
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes 10.111.240.1 <none> 443/TCP 30d
rs-service 10.96.206.29 <none> 80/TCP 6mIn the above output, you can see that External IP is set to none which means the current service can only be used from inside the cluster. The ClusterIP service is only accessible to other Pods and other resources inside the cluster. You’ll soon learn how to expose a service externally.
You can delete the newly created service using kubectl delete -f rs-svc.yml command which returns the confirmation that the service has been deleted.
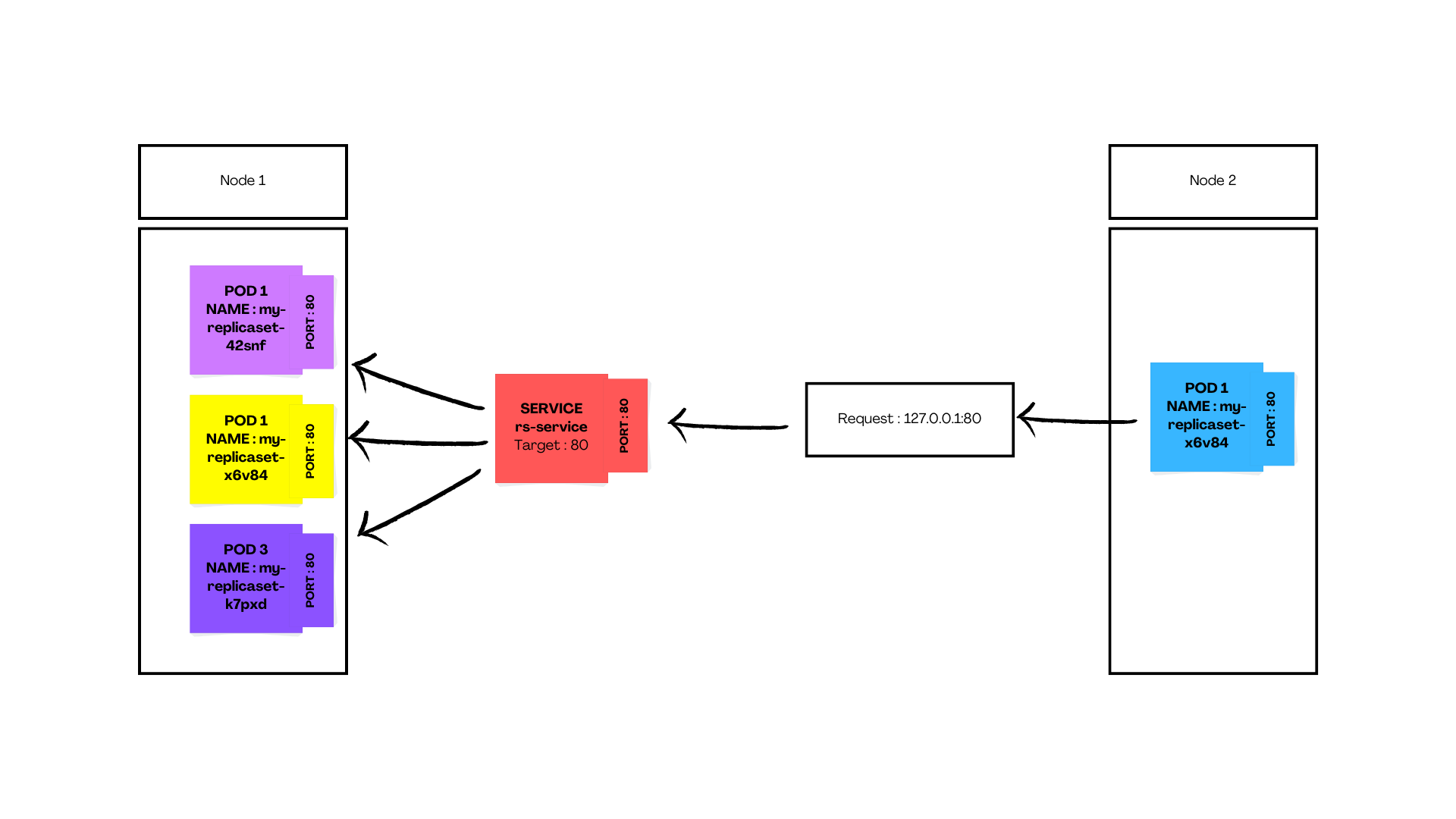
In the above illustration, every request at IP:<PORT> from inside the cluster is directed to the service resource which then redirects to the <TARGET_PORT> (in this case 80) of the Pods with matching labels.
When Do We Use ClusterIP Services?
Here are some common use cases for ClusterIP services in Kubernetes:
- Load balancing traffic to a group of identical pods
- Exposing a service to other services within the cluster
- Providing a stable IP address and DNS name for a set of pods that can be used by other services within the cluster
- Providing a single entry point for accessing multiple services within the cluster
Multiport Services
ClusterIP services can also be used to make a Pod listen to more than one port. This configuration is known as multiport services. In Kubernetes, a multiport service is a type of service that exposes multiple ports for external access. This is useful when a single application or container exposes multiple services or APIs on different ports.
By creating a multiport service, you can map these different ports to a single service and make them accessible using a single IP address and DNS name. This simplifies the process of accessing the services and allows you to easily scale them up or down as needed.
To define a multiport service create a YAML file, mul-svc.yml and add the following configuration:
apiVersion: v1
kind: Service
metadata:
name: rs-service
spec:
ports:
- name: server-main
protocol: TCP
port: 80
targetPort: 80
- name: server-logs
protocol: TCP
port: 25
targetPort: 25
selector:
app: my-podIn the above configuration, you can see that multiple ports are defined in the spec.ports field. This field contains an array of objects, each of which defines the port number, protocol, and target port for a specific service. Note that defining the name field is required for each port you define in multiport services. To create the Service from the above file, run the following command in your terminal:
kubectl create -f mul-svc.ymlAfter running the above command, your application can be communicated to both port 80 and 25 using multiport service. Multiport services provide a convenient way to access multiple services from a single application or container, while cluster IP services require you to create a separate service for each port you want to expose. This is useful when a single application or container exposes multiple services or APIs on different ports.
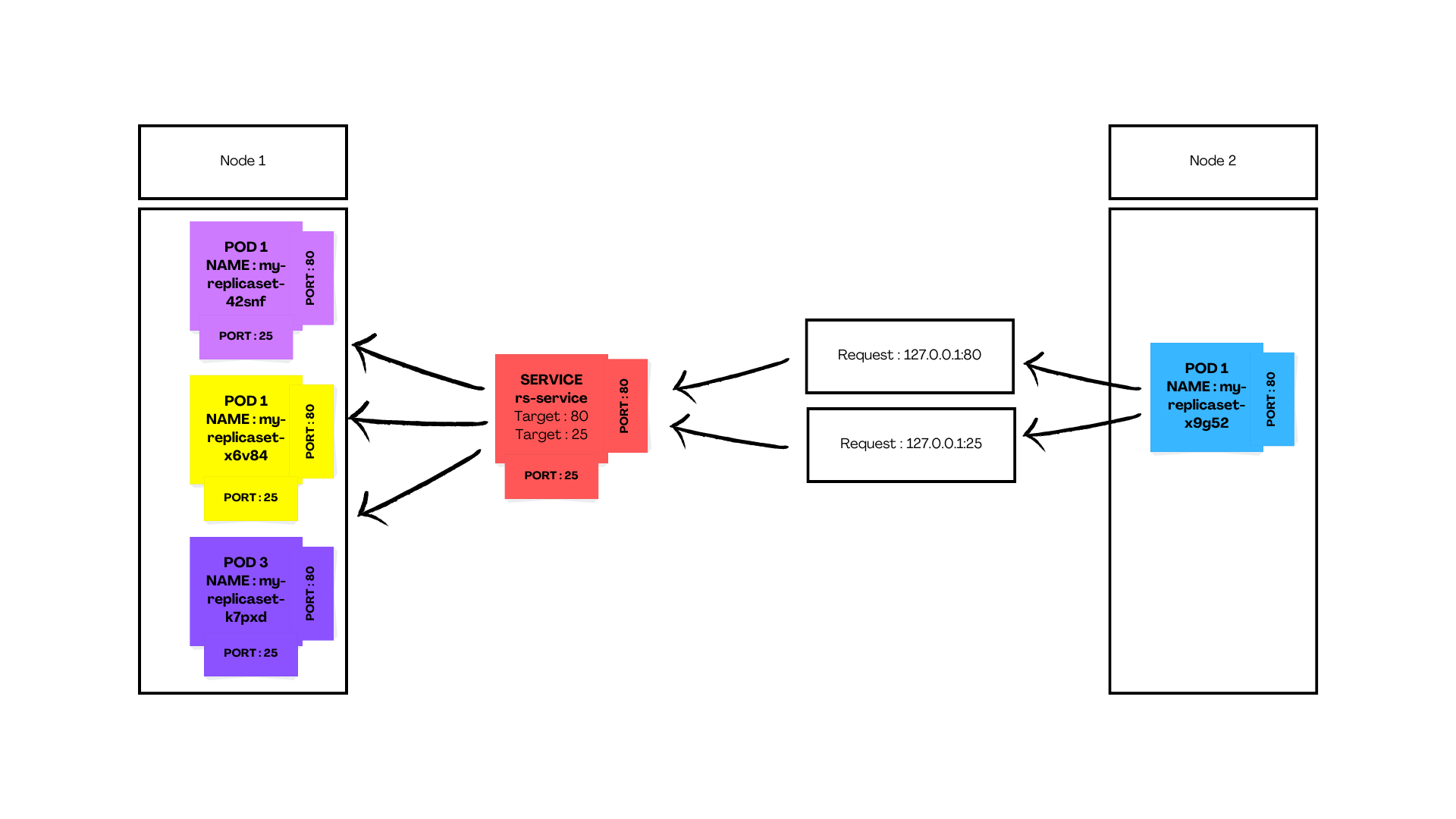
In the above illustration, you can see that the requests for both Port 80 and Port 25 are routed through the same service to the Pods.
Headless Services
You’ve learned that the ClusterIP Service randomly routes requests to any one of the Pods inside the Cluster. The Headless Service operates differently; rather than issuing requests at random, it facilitates direct communication between a specific Pod and other Pods. Headless service accomplishes this by setting the ClusterIP of the Pod to None and then performing a DNS lookup which provides the Pod’s IP instead of Service IP. This means that the service does not have a stable IP address that can be used to access it from outside the cluster.
When you need to access stateful applications such as databases, a headless service is employed. Accessing random Pods in a stateful application could lead to data inconsistencies, which is undesirable in a system.
These services are typically used when you want to access the individual pods within a service directly, rather than accessing the service as a whole through a load balancer. Headless Service is created by setting the ClusterIP field to None in the Service YAML file (here, a new file, rs-svc-headless.yml, is created).
apiVersion: v1
kind: Service
metadata:
name: rs-service-headless
spec:
clusterIP: None
ports:
- protocol: TCP
port: 80
targetPort: 80
selector:
app: my-podNote that we’ve set the newly added spec.clusterIP field to None. After creating this service using kubectl create -f rs-svc-headless.yml, run the following command in your terminal.
$ kubectl get svcRunning the above command gives the following output:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 117d
rs-service ClusterIP 10.103.78.229 <none> 80/TCP 3m51s
rs-service-headless ClusterIP None <none> 80/TCP 82sAs seen in the output, Kubernetes did not allocate the CLUSTER-IP as specified in the YAML file, hence it is None. In most cases, this type of configuration is used in conjunction with ClusterIP Service to handle load balancing and normal communication between the Pods.
Headless services are often used with pods which maintain a consistent state and store data across multiple pods. In order to maintain this state of a service and its associated data, Stateful Pods need to be accessed directly and consistently. By using a headless service, you can access the individual pods within the service directly, without going through a load balancer. This allows you to maintain the state of the service and ensure that the data is consistent across all the pods.
You can also get detailed information about the service by running the following command:
$ kubectl describe -f rs-svc-headless.ymlHere’s the output:
Name: rs-service-headless
Namespace: default
Labels: <none>
Annotations: <none>
Selector: app=my-pod
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: None
IPs: None
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 172.17.0.5:80,172.17.0.6:80,172.17.0.7:80
Session Affinity: None
Events: <none>In the above output, you can see that IP and IPs field is set to None since Headless Service does not provide any IP to the pod, but does a DNS lookup on the endpoints.
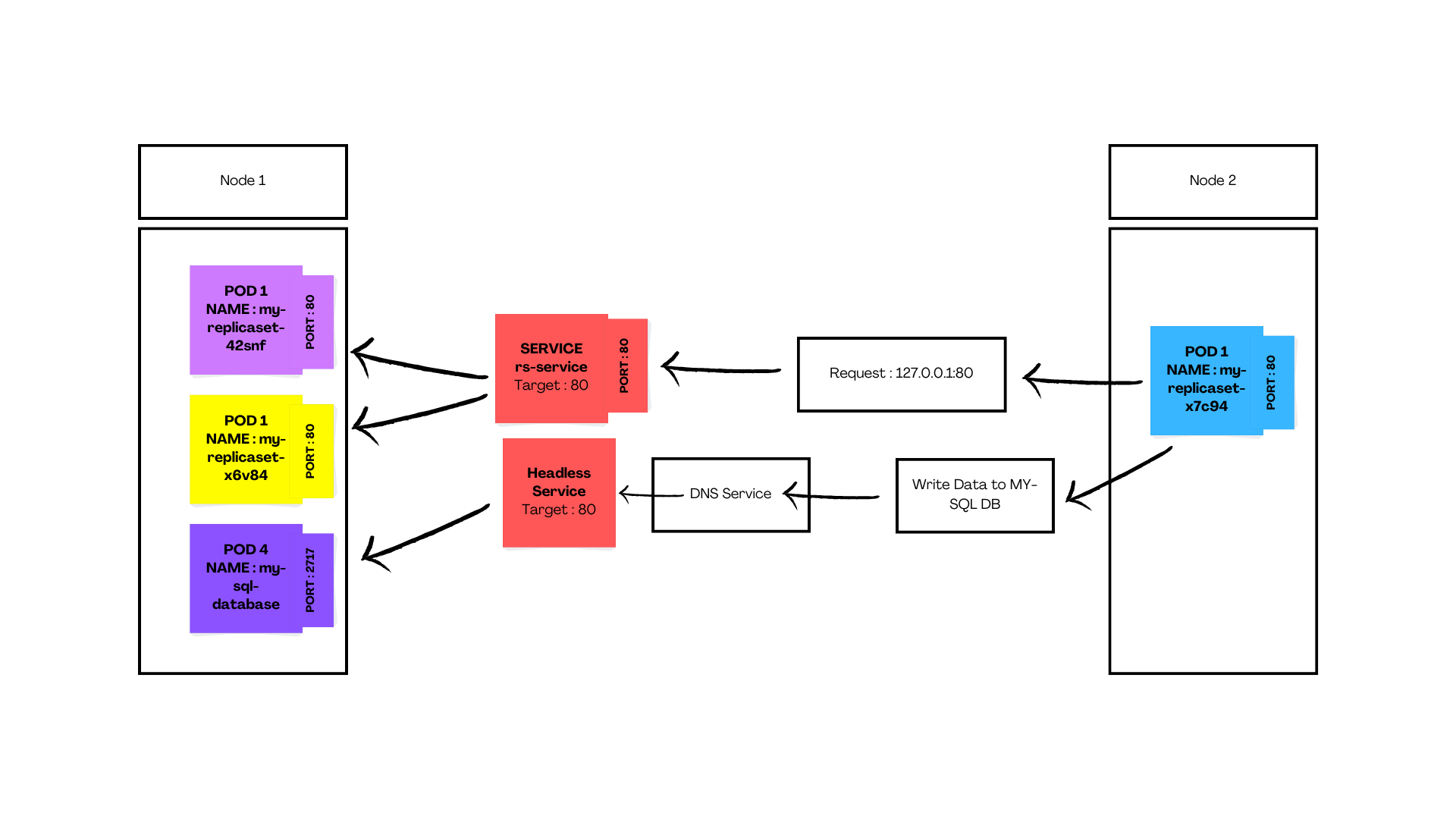
The above image shows how the request to write data to the database (stateful pod) goes through a DNS lookup and then to the database. This is done to maintain consistency between the replicas of the databases.
NodePort Services
A NodePort service in Kubernetes is an extension of the ClusterIP service type. A NodePort service is similar to a ClusterIP service in that it allows the pods within a cluster to communicate with each other. However, a NodePort service also exposes the service on a specific port on each node in the cluster. Each pod has one or more ports (for example, 8080) which are used by this type of service as the external IP addresses used by clients connecting to it.
Note that exposing ports using NodePort Service type is not considered secure. This is because it allows anyone with access to the IP address of a node in the cluster to access the resources that are running on that node. This can be a security risk because it allows unauthorized users to potentially access and manipulate the services and their associated data.
To create a NodePort service, create a new file, rs-np-svc.yml, and populate it with the following configuration.
apiVersion: v1
kind: Service
metadata:
name: rs-service-nodeport
spec:
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 30256
selector:
app: my-podIn the above file you can see that the type field specifies the service type as NodePort, the nodePort field exposes port 30256 for the external use. Note that nodePort can take on any value in the range between 30000 and 32767. The port field is used for the ClusterIP service as the Service automatically creates a ClusterIP service to load balance requests among the Pods.
Now create the above service by running kubectl create -frs-np-svc.yml`. To check if the Service has been created, run the following command in your terminal:
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 117d
rs-service ClusterIP 10.103.78.229 <none> 80/TCP 7m25s
rs-service-headless ClusterIP None <none> 80/TCP 4m56s
rs-service-nodeport NodePort 10.105.4.133 <none> 80:30256/TCP 28sIn the above output you can see that the new Nodeport Service is created by the Kubernetes. You can also run the following command to get detailed information about the Service:
$ kubectl describe -f rs-np-svc.ymlName: rs-service-nodeport
Namespace: default
Labels: <none>
Annotations: <none>
Selector: app=my-pod
Type: NodePort
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.105.4.133
IPs: 10.105.4.133
Port: <unset> 80/TCP
TargetPort: 80/TCP
NodePort: <unset> 30256/TCP
Endpoints: 172.17.0.5:80,172.17.0.6:80,172.17.0.7:80
Session Affinity: None
External Traffic Policy: Cluster
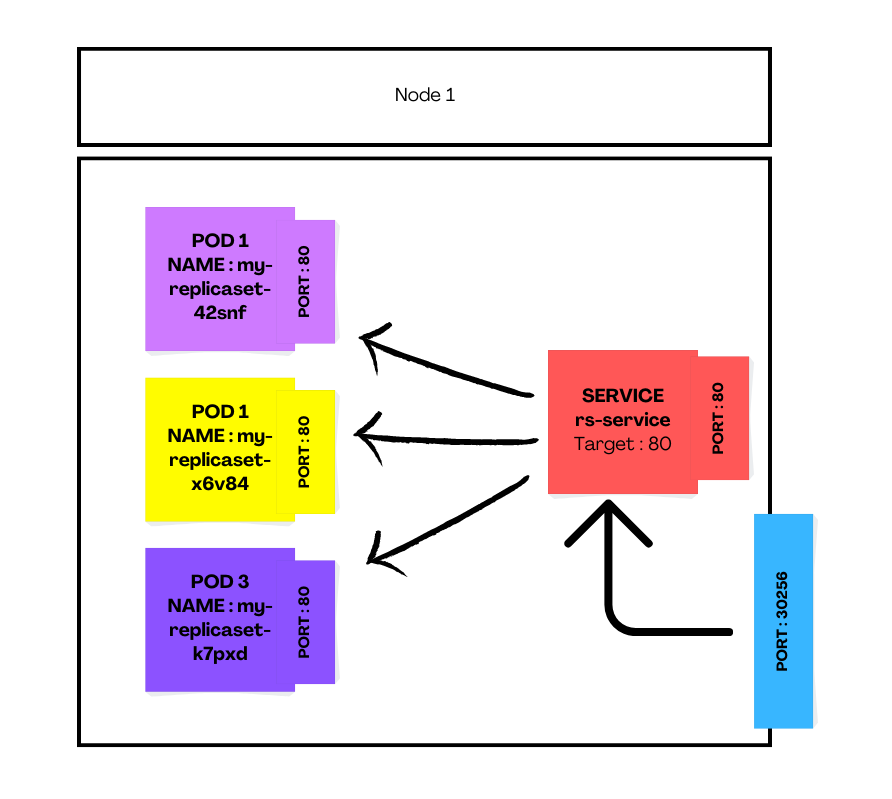
Events: <none>The working of NodePort service is summarized below. You can see that the Node in the cluster opens the desired port (as specified in spec.ports.nodePort) which redirects all the requests to the internal service which then redirects them to the Pods.
LoadBalancer Services
Load balancer services in Kubernetes are a type of service that exposes a service to external traffic using a load balancer. A load balancer is a network appliance that distributes incoming traffic among multiple servers or nodes in a cluster. This can improve the performance, reliability, and scalability of your services by distributing the workload among multiple instances, and allowing you to easily add or remove nodes as needed.
Additionally, LoadBalancer services automatically detect and route traffic away from unhealthy pods. This helps ensure that the service remains available and responsive, even in times of failures and disruptions.
To create a LoadBalancer Service, create a new file svc-load.yml and add the following to the manifest file:
apiVersion: v1
kind: Service
metadata:
name: rs-service-loadbalancer
spec:
type: LoadBalancer
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 30056
selector:
app: my-podIn the above file, you can see that spec.type is set as LoadBalancer, and every other configuration is the same as the Nodeport service you defined earlier.
This is because the LoadBalancer service is an extension of NodePort Service. Like a NodePort service, a LoadBalancer service exposes a resource on a specific port on each node in the cluster. However, a LoadBalancer service also creates a load balancer with a stable IP address and DNS name that can be used to access the service from outside the cluster. When LoadBalancer services are created Kubernetes automatically creates a NodePort service to work in conjunction with the LoadBalancer service.
Now create the above service by running the below command:
kubectl create -f svc-load.ymlAfter running the above command you can see that the LoadBalancer service was created using the command kubectl get svc, which produces the following output:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 126d
rs-service ClusterIP 10.103.78.229 <none> 80/TCP 8d
rs-service-headless ClusterIP None <none> 80/TCP 8d
rs-service-loadbalancer LoadBalancer 10.110.210.241 145.168.25.58 80:30056/TCP 60sIn the above output you can see that the LoadBalancer Service also exposed your application using EXTERNAL-IP. Note that using LoadBalancer Service requires cloud providers like AWS or GCP. Also, minikube does not support LoadBalancer so using this service in minikube will show <pending> in the EXTERNAL-IP section.
Overall, load balancer services are helpful when exposing services to external traffic. 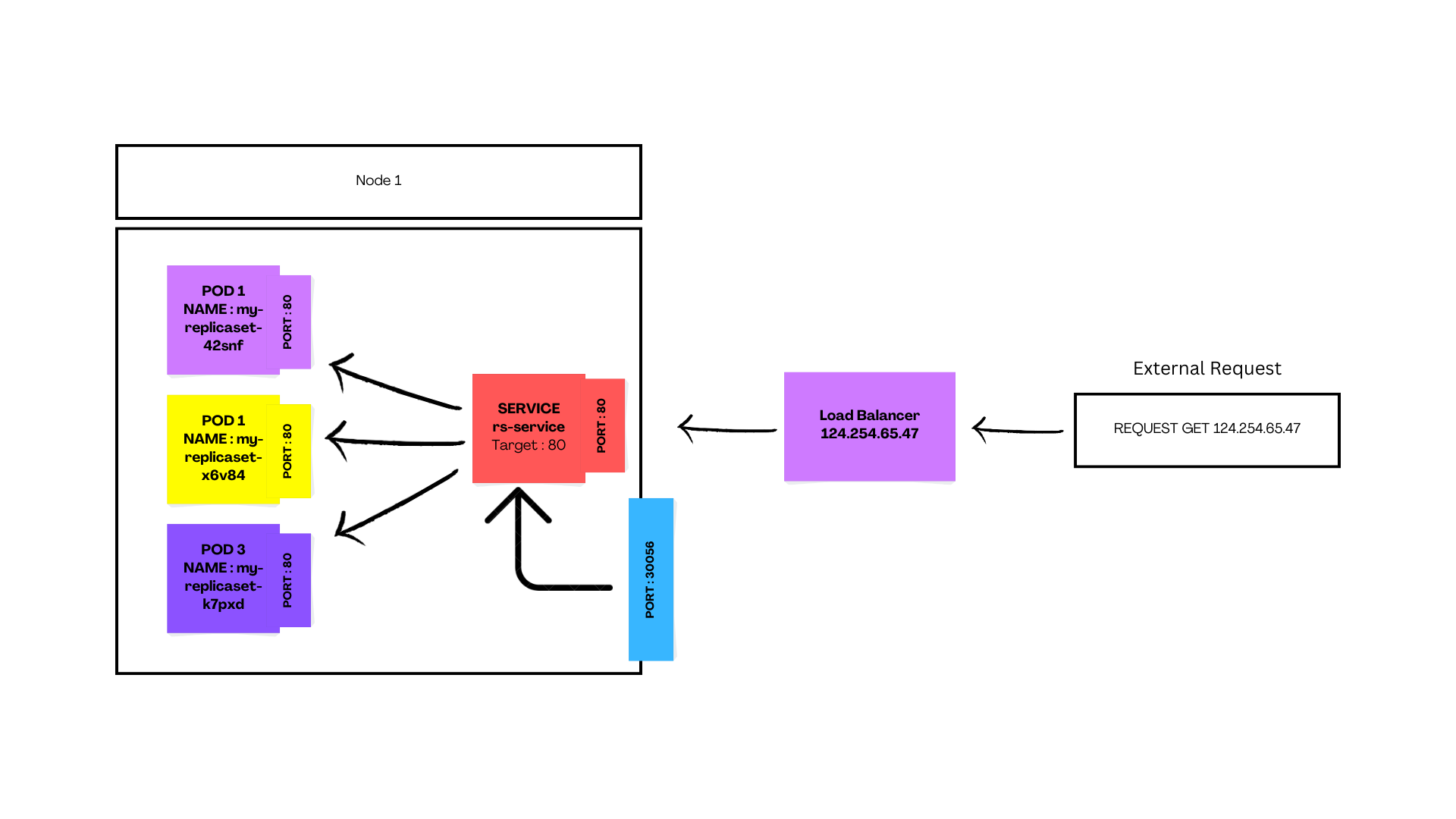
In the above image, you can see that the external request to the cluster goes through the LoadBalancer service which then redirects it to the nodePort—and then chooses a random Pod—after taking into account the current load on each Pod that listens to targetPort.
Configuring Services - What You Should Know
If services in Kubernetes are not configured properly, we may run into problems such as:
- The containers within the pod may not be able to communicate with each other or with other pods in the cluster.
- Pods may not be able to access the resources they need, such as memory, CPU, or storage.
- Your application may not be able to reach the outside world, which can prevent it from accessing external services or being accessed by users.
- The overall performance of the Kubernetes cluster may be degraded, which can affect the availability and reliability of the applications running on it.
It’s important to be careful when setting up services in Kubernetes because they act as the gateway to your application. If they are not configured properly, they could disrupt communication between pods and harm your system.
Conclusion
Services in Kubernetes provide a steady network endpoint for a specific set of pods, simplifying inter-application communication. This article gave insights into creating and using such services, focusing on the most common types; ClusterIP, Headless, NodePort, and Load Balancer Services. Understanding and correctly configuring these services is crucial in Kubernetes, ensuring effective cluster communication.
If you’re looking to further simplify your build processes, you might want to give Earthly a try. It’s efficient and super easy to use, and could be the next step in optimizing your Kubernetes workflow.
Earthly makes CI/CD super simple
Fast, repeatable CI/CD with an instantly familiar syntax – like Dockerfile and Makefile had a baby.








