What About A Plain Text Web

We’re Earthly. This article explores a Text-Mode experiment, which transforms web pages into plain text. After reading it, take a look at Earthly.
TLDR: Go to https://earthly-tools.com/text-mode?url=https://yoururl.com to get a readable, plain text version of a webpage.
Background
We have this new feature at Earthly, where you can share your local build log with others as a temporary webpage. This got me thinking about the reverse: turning a webpage into a text document.
Most of my time on the web, I’m just reading text. So why do I need complex HTML pages, CSS, and JavaScript to read the web? Why can’t I just read things as text in my terminal?
Admittedly this is a bit of a strange question. Plain text doesn’t have links, images, or video, but a lot of what I consume online would work as .txt file on an FTP server or old-school BBS, and I’d still get most of the value I’m getting today.
Text-Mode might be an improvement for the people with lousy dial-up connections who can’t even load certain pages.
A couple years ago, I took a road trip from Wisconsin to Washington and mostly stayed in rural hotels on the way. I expected the internet in rural areas too sparse to have cable internet to be slow, but I was still surprised that a large fraction of the web was inaccessible.
Despite my connection being only a bit worse than it was in the 90s, the vast majority of the web wouldn’t load
- Dan Luu on Web Bloat
So I’ve made it. Send your url to https://earthly-tools.com/text-mode?url=yoururl to get a plain text version of the page.
Here are some examples:
Examples
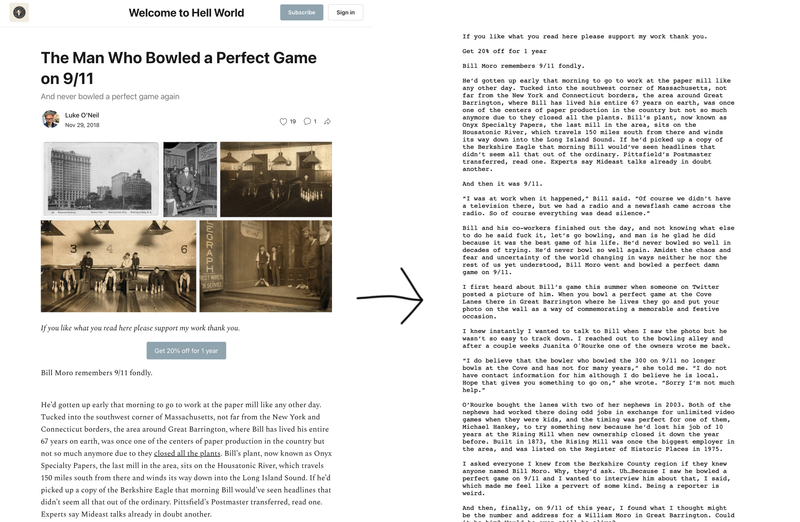
Substack
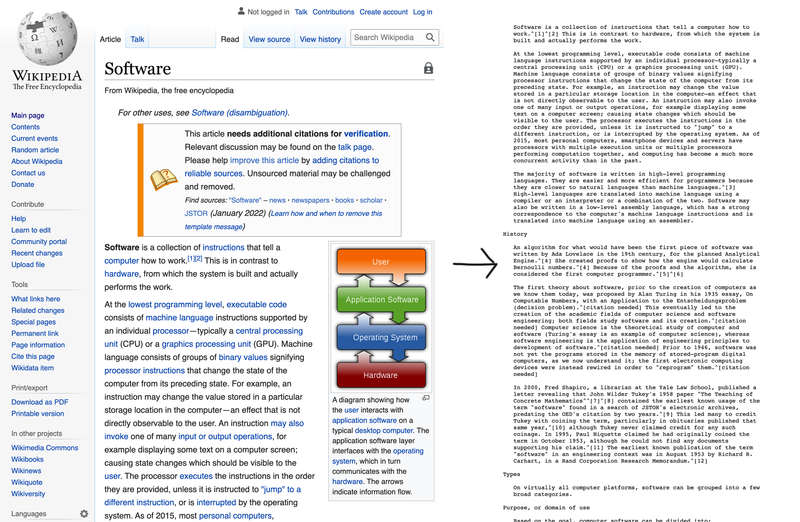
Wikipedia
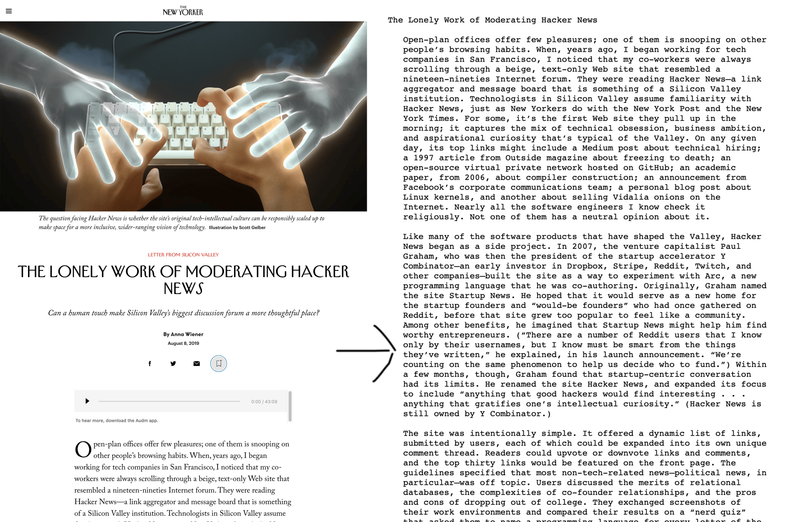
New Yorker
Reading From Terminal
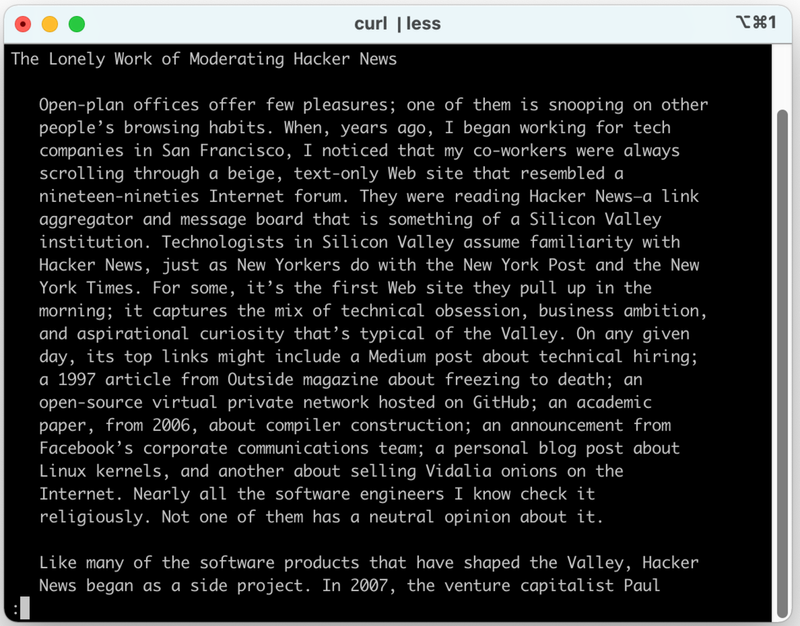
curl | less and read from your terminal
Read From Phone

How It Works
The URL is served by an AWS Lambda that uses Mozilla Readability library combined with the Lynx browser to turn html into text. This is a POC. Nothing is cached, and it’s not super fast, but it saves page bandwidth. Using it, you choose a different set of trade-offs than the modern web typically offers: fewer features but fewer round-trips and less bandwidth.
Let me know what you think.
Earthly makes CI/CD super simple
Fast, repeatable CI/CD with an instantly familiar syntax – like Dockerfile and Makefile had a baby.
Post Publish Update
On Reddit, WhappaBurger asked if this could be open-sourced. There are a couple steps for me to do to open source it (mainly putting it in its own repo and separating it from the AWS lambda code so it can be run stand-along) but for now, here is the lambda source:
'use strict';
import fs = require('fs');
const axios = require("axios").default;
import { JSDOM } from "jsdom";
import { Readability } from "@mozilla/readability";
import createDOMPurify = require("dompurify");
const DOMPurify = createDOMPurify(new JSDOM("").window);
import { ChildProcessWithoutNullStreams, spawn } from 'child_process';
import BufferList = require('bl');
exports.handler = (event: { queryStringParameters: { url: string; }; }) => {
console.log("Requesting:", event.queryStringParameters);
if (event.queryStringParameters == null || event.queryStringParameters.url === undefined || event.queryStringParameters.url === "") {
let readme = fs.readFileSync('readme.txt', 'utf8');
let response = {
statusCode: 200,
headers: {
"content-type": "text/plain; charset=utf-8"
},
body: readme
};
return (Promise.resolve(response));
} else {
const url = event.queryStringParameters.url;
return call(url)
}
};
function call(url: string) {
console.log("Getting:" + url);
return axios
.get(url)
.then((response: { data: string }) => {
console.log("Got content for:" + url );
const sanitized = DOMPurify.sanitize(response.data);
const dom = new JSDOM(sanitized, {
url: url,
});
const parsed = new Readability(dom.window.document).parse();
if (parsed == null) {
throw new Error("No content found");
} else {
console.log("Got Readability version content for:" + parsed.title + "(" + url + ")");
return spawnPromise('lynx', ['--stdin', '--nolist', '-assume_charset=utf8', '--dump'], parsed.content, parsed.title, url);
}
})
.then((response: Page) => {
console.log("Got text/plain version content for:" + response.title + "(" + response.url + ")");
return {
statusCode: 200,
headers: {
"content-type": "text/plain; charset=utf-8"
},
body: response.title + "\n\n" + response.body + "\n\n" + "Text-Mode By Earthly.dev"
};
})
.catch((error: Error) => {
return {
statusCode: 500,
headers: {
"content-type": "text/plain; charset=utf-8"
},
body: "Some error fetching the content:" + error
};
});
}
interface Page {
body: string;
title: string;
url: string;
}You have my permissions to copy and use this code.
This is the only node.js code I’ve ever written so I’m guessing it is not idiomatic. I’ll add the repo url to this article, with proper build instructions once I get that in place. ( Then you too will be able to have your own lynx-as-a-service instance. )







