
Postgres Database Replication in Django

We’re Earthly. We make building software simpler and faster using containerization. Earthly can make Django easier to build and deploy. Give it a try.
Introduction
One of the common web application architectures is the 3-tier application architecture.
A 3-tier application consists of the presentation tier where data is presented to the users, The web tier which contains the business logic, and the data tier where data is stored.
The data tier consists of a database and other application services that aid the read/to write access to that database.
When this database goes offline, the whole web architecture goes down as there is no component to manage data.
The following images illustrate the scenario:
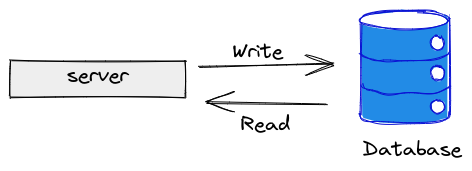
The above image shows the web layer and the data layer in the architecture. When the database server is online, it will serve both read and write operations and the whole architecture remain functional.
Once the single database server goes down as illustrated below, The whole architecture goes down as there are no other means to read or write data from the presentation layer:
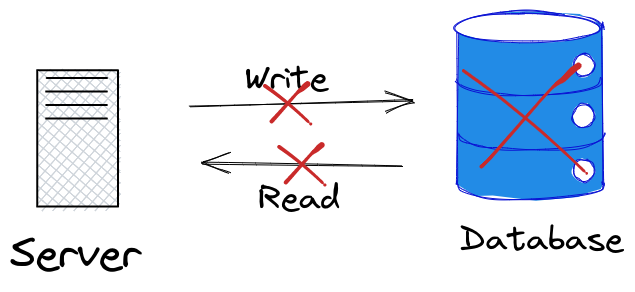
One of the approaches that could mitigate such a flaw in this architecture is Database Replication.
Database Replication
Database Replication is an approach where multiple instances of a database are configured for a server, such that data written to one database is replicated and stored in other database instances as well.
The data is replicated from the Primary database to the Standby or Secondary databases. The standby database could either be a Hot Standby Database or a Warm Standby database depending on whether it accepts connection before the primary database goes down or not.
The image below shows the configuration of a single primary and Secondary Database:
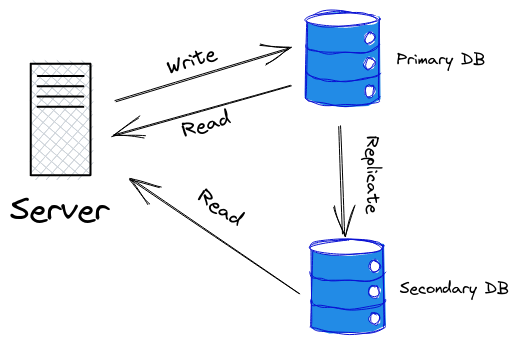
When data is written to the Primary DB, it is replicated to the Secondary DB so that all data available in the primary database are also available for reading in the Secondary DB. The Secondary DB can accept connections from the web server and serve database read operations alongside the Primary DB while the write operations are exclusively carried out on the Primary DB.
In a situation where we have an application with heavy read operations, The Secondary DB can serve the read operations in parallel alongside the Primary DB which will protect the Primary DB from being overloaded and consequently reduce the query latency.
Such a standby database server that can accept connections and serves read-only operations is called a Hot standby server.
With this configuration, the Secondary DB can continue to serve read operations from the data that has been replicated to it even when the Primary DB goes down as shown below:
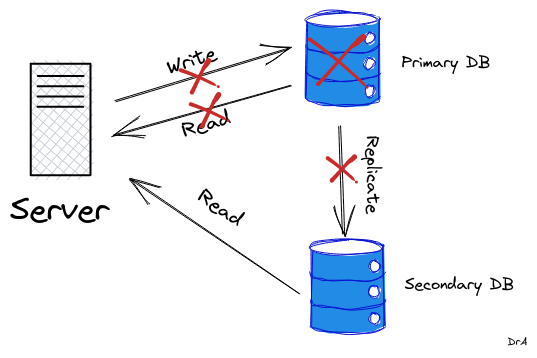
This will make](/blog/using-cmake) sure our application does not go down totally when the primary database goes down because the secondary database will still be available to serve read operations.
In more sophisticated configurations, one of the secondary databases can be promoted as a primary database to serve both read and write operations.
Objectives
In this tutorial, We will configure Database replication by setting up a Primary database and a Hot Standby database in Postgresql. These two instances of the database will be a container of Postgresql docker image.
We will connect these two databases to a Django application. Afterward, we will create a Django database router to route queries to these databases.
Prerequisite
To follow up with this tutorial, it will be beneficial if you are familiar with:
- The command line
- Docker and its commands
- Django
However, if you are not familiar with the above, this is quite an interesting topic that you would gain one thing or the other, so stay around.
Setting Up the Primary Database
Most of the files we will need to configure for the Postgresql database replication require that you have access to the root user.
Use the command below to switch to the root user:
$ sudo -iSince we will need two instances of Postgresql on our machine, we will make use of docker.
If you have Postgresql installed on your machine, start by stopping any instance of Postgresql service running on it:
$ sudo service postgresql stopPull an official Postgresql docker image with version 12 or higher:
$ docker pull postgres-12-alpineCreate the primary database instance from the Postgresql image:
$ docker run --name primary_db -p 5432:5432 -e \
POSTGRES_USER=postgres -e POSTGRES_PASSWORD=postgres -v \
/tmp/lib/postgres:/var/lib/postgresql/data -d postgres:12-alpineThe command above:
- Creates a
Postgresqlcontainer instance namedprimary_dbwith userpostgresand passwordpostgres. - Maps the port
5432of your machine to the port5432of the docker container - Creates the configuration files that will be used by the docker Postgresql container from the Postgresql configuration files on your machine and persist the data that will be generated.
The above command will also name the database
postgreswhich we will later use as the value for theNAMEkey in the database configuration when connecting to Django.
Start the Postgresql interactive environment on localhost and port 5432 as user postgres that we created for the primary_db container:
$ psql -h 127.0.0.1 -U postgres -p 5432use postgres as the password
Create a user with a username of replica and password replica with Replication privilege:
postgres= CREATE USER replica REPLICATION LOGIN\
ENCRYPTED PASSWORD 'replica';You should get the output shown below:
CREATE ROLEThe secondary database will connect to the primary database with the replica user.
We need to grant this user a REPLICATION privilege because the database role that can be used for replication connection must have a REPLICATION privilege or must be a superuser.
Quit the Postgresql terminal:
postgres=# \qAdd the following to the end of the pg_hba.conf file in the /tmp/lib/postgres/ directory
You can add it by opening the file or using the echo command as shown below:
echo 'host replication replica 0.0.0.0/0 trust' \
>> /tmp/lib/postgres/pg_hba.confThis allows a replication connection to this primary database from a standby database that authenticates with the replica user that we created earlier.
You can open the file to see the content of the file:
nano /tmp/lib/postgres/pg_hba.conf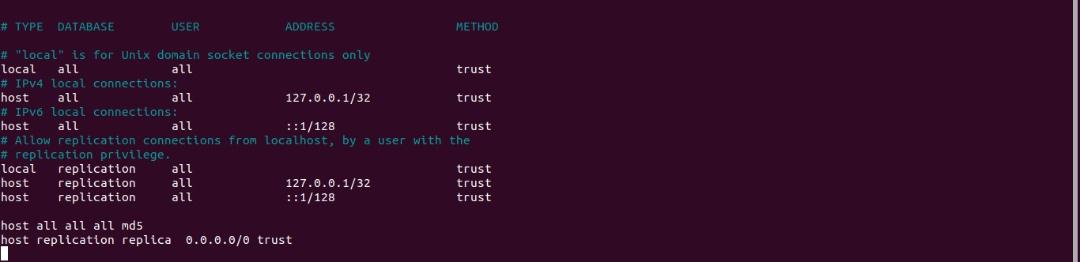
CAUTION: Configuring the system for local “trust” authentication allows any local user to connect as any PostgreSQL user, including the database superuser. If you do not trust all your local users, use another authentication method.
Open the postgresql.conf file:
nano /tmp/lib/postgres/postgresql.confUpdate and un-comment the following configuration:
In the WRITE-AHEAD-LOG section:
wal_level = replicaThis parameter allows writing enough data to support replication, including running read-only operations on a standby server.
In the REPLICATION section:
max_wal_senders = 3 #How many secondaries can connect The max_wal_senders configuration specifies the maximum number of parallel connections that the standby servers can send. A value of 0 means no replication is allowed.
This configuration determines how many standby servers can connect to the primary database.
Note that this configuration is only applicable to the primary server.
Restart the primary_db container after saving the postgresql.conf file:
$ docker restart primary_db Make a full binary copy of the Postgresql directory:
pg_basebackup -h 127.0.0.1 -p 5432 -D \
/tmp/postgressecondary -U replica -P -vThe -P argument shows the progress and -v for verbose.
You should get the output below:

We will build the standby database on this backup file.
Configure the Secondary Database
Open the postgresql.conf file in the /tmp/postgressecondary/ directory:
nano /tmp/postgressecondary/postgresql.confAdd the following in the standby server subsection of the Replication section of the file:
primary_conninfo = 'host=db port=5432 user=replica password=replica'
hot_standby = onThe primary_conninfo specifies a connection parameter that the standby server will use to connect to the primary server.
The user and password we passed are for the replica user we created in the primary_db earlier.
The port is the port the primary_db container is running on.
The db will be an alias for the primary_db. We will add the alias while creating the docker container for the secondary database.
The hot_standby configuration allows running queries on the standby server.
In the same postressecondary directory, create a standby.signal file:
$ mkdir standby.signalThe presence of the standby.signal file ( even though empty ) will enable the standby server to start in standby mode.
Create the secondary database container by running another instance of the PostgreSQL container:
docker run --name secondary_db -e POSTGRES_USER=postgres \
-e POSTGRES_PASSWORD=postgres -v \
/tmp/postgressecondary:/var/lib/postgresql/data \
--link primary_db:db -p 5433:5432 -it postgres:12-alpineThe command above:
- Create a Postgresql container named
secondary_dbwith userpostgresand passwordpostgres( A user postgres and password postgres will be created for the database alongside the other parameters that you specified for the user). - Map the port
5433of your machine to the port5432of the docker container since theprimary_dbcontainer is mapped to port5432 - Allows the
secondary_dbcontainer to share resources with theprimary_dbcontainer via the links flag anddbis an alias for the link name. - Share a volume between the container and the Postgresql files on your machine and persist the data generated in the
postgressecondarydirectory created by thepg_basebackupcommand
The database’s name will default to postgres like the primary_db container.
You should get the following output:
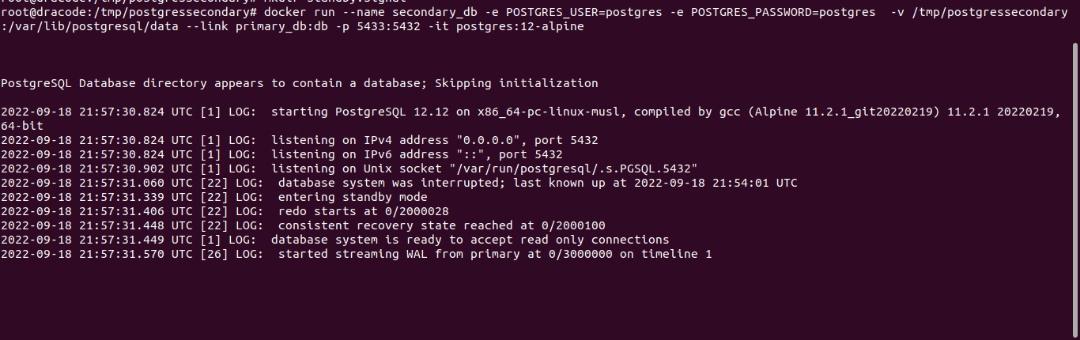
As shown in the image above, The database is ready to accept read connections.
Open the PostgreSQL terminal for the primary_db and check the PostgreSQL replication statistics:
$ psql -h 127.0.0.1 -U postgres -p 5432postgres=# SELECT * FROM pg_stat_replication;You should get the output below:
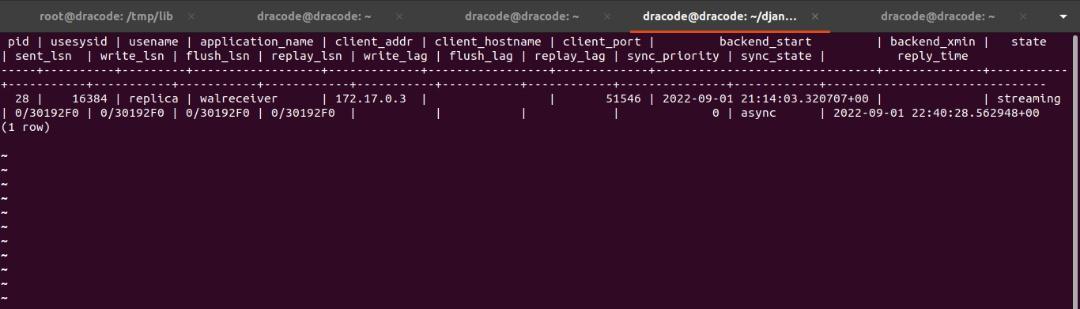
For a detailed description of this output, you can check pg_stat_replication.
We need to create a replication slot that will ensure that the primary server does not remove the records of changes in data ( that are stored in a file called Write Ahead Log or WAL files ) written to it until the standby server receives it.
The replication slot is needed to keep these WAL files available even when the standby server is offline or disconnected.
If the standby server goes down, the primary server can keep track of how much the standby lags and preserve the WAL files it requires until the standby server comes back online. The WAL files are then synchronized and replayed back on the standby server. This will ensure that the standby server doesn’t miss any data written to the primary database while it was offline.
To create this replication slot:
Stop the secondary_db container:
$ docker stop secondary_dbOpen the postgrestql.conf file of the secondary_db and add the following in the standby server subsection of the Replication section:
$ nano /tmp/postgressecondary/postgresql.confprimary_slot_name = 'standby_replication_slot'We need to create a physical replication slot on the primary_db with the same name as the value of the primary_slot_name configuration.
Open the PostgreSQL terminal for the primary_db container as the postgres user and add the following:
$ psql -h 127.0.0.1 -U postgres -p 5432SELECT * FROM pg_create_physical_replication_slot \
('standby_replication_slot');You can restart the primary_db and start the secondary_db container:
$ docker restart primary_db
$ docker start secondary_db Confirm the two containers started:
$ docker ps You should get an output as shown below:

In case any of them is not up, you can check the container logs to troubleshoot:
$ docker logs <contianer_name>To confirm that the replication slot is active:
Open the PostgreSQL terminal as the postgres user for the primary_db:
$ psql -h 127.0.0.1 -U postgres -p 5432Enter the command below:
SELECT * FROM pg_replication_slots;You should see the output below:

Confirming Replication
To confirm if data in the primary_db are replicated to the secondary_db, we will create a table in the primary_db and we will add some data. Afterward, we will retrieve this data from the secondary_db.
Open the PostgreSQL of the primary_db as user postgres:
psql -h 127.0.0.1 -U postgres -p 5432Create a database table called test with id and value fields :
CREATE TABLE test ("id" int4 NOT NULL, "value" varchar(255), \
PRIMARY KEY ("id"));You should get an output of CREATE TABLE
Insert 10 random numbers in the test database table:
INSERT INTO test SELECT generate_series(1,10), random();You should get an output of INSERT 0 10
View the content of the table:
SELECT * FROM test;You should have an output as shown below:
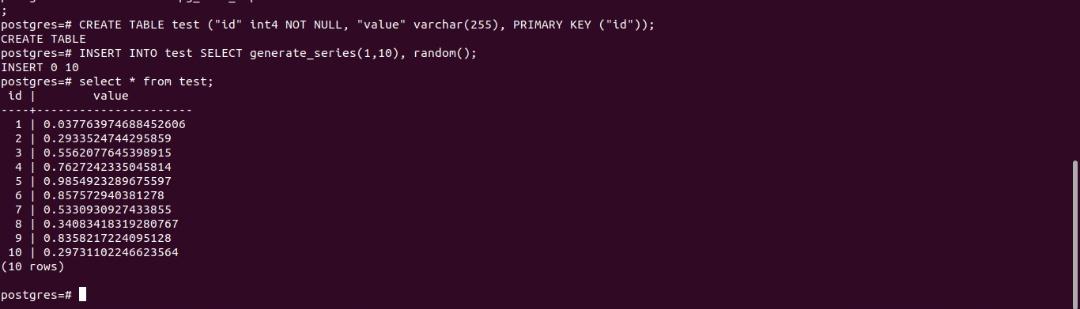
You can now retrieve this same data on the secondary_db because it would have replicated to it.
Open the PostgreSQL terminal for the secondary_db as user postgres:
Note that the secondary_db is running on port 5433
psql -h 127.0.0.1 -U postgres -p 5433Retrieve all the data for the test table:
SELECT * FROM test;You should get an output as shown below:
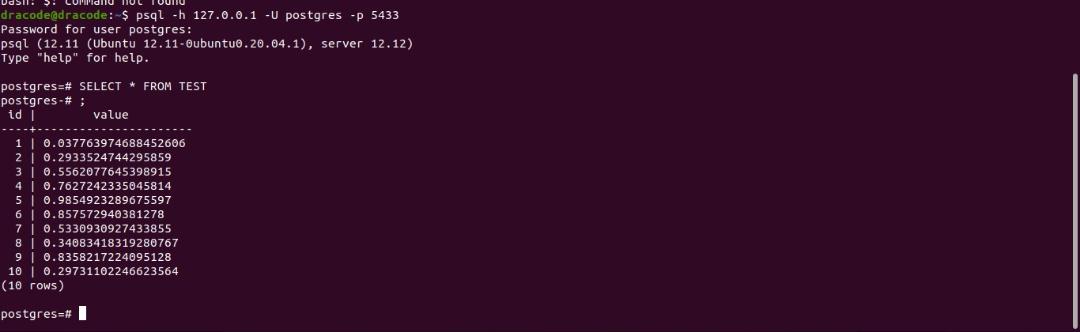
This shows that the replication configuration is successful.
If you try a write operation on this database you will get an error as shown below:

Connect With Django
To connect these two databases to a Django Application, You can set up a minimal Django application or use one of your existing Django applications.
For this purpose, I will use a Django Application I created for this purpose called DJReplica.
Creating the Model
I am just going to create a simple database model with the common data types as fields.
Add the model below in the models.py file:
from django.db import models
# Create your models here.
class ReplicationModel(models.Model):
name = models.CharField(max_length=10)
count = models.IntegerField()
is_available = models.BooleanField(default=True)
average = models.FloatField()
date_created = models.DateTimeField(auto_now_add=True)Connecting the Two Databases
Now that we have a model, let us connect the two databases to the application:
Open the settings.py and add the following configuration:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'postgres',
'USER': 'postgres',
'PASSWORD': 'postgres',
'HOST': '127.0.0.1',
'PORT': '5432',
},
'replica':{
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'postgres',
'USER': 'postgres',
'PASSWORD': 'postgres',
'HOST': '127.0.0.1',
'PORT': '5433',
}
}The first database configuration which is the default connects to the primary_db container as user postgres and it runs on the localhost at port 5432. The default database name created by docker is postgres.
The replica configuration connects to the secondary_db container which runs on localhost on port 5433.
Configuring the Router
Now that we have connected the two databases to the Django application, we need to set up a database router that tells our Django application how to route queries to these databases.
A database router is a python class that provides an abstraction on how to manage multiple databases. It provides about 4 methods which include: db_for_read which returns the database to use for Read operations. db_for_write specifies the database to use for Write operations. allow_relation returns a boolean value that determines if a relation should be allowed between two objects. allow_migrate returns True if migration should be allowed to a specific database.
However, not all these four methods need to be specified in our router class.
For more detailed information about these four methods, you can check the official Django documentation on managing multiple databases
To setup this router:
Create a python file In your project configuration directory:
I will name my file dbrouter.py
├── asgi.py
├── dbrouter.py
├── __init__.py
├── settings.py
├── urls.py
└── wsgi.pyAdd the router class in the dbrouter.py file:
from random import choice
from django.db.utils import OperationalError
from django.db import connections
class ReadWriteRouter:
"""
A router that route query to different database based on.
"""
def db_for_read(self, model, **hints):
"""
Route read to either the default or replica.
"""
db_list = ["replica", "default"]
db_choice = choice(db_list)
try:
# Check if the chosen database is online
db_conn = connections[db_choice]
db_conn.cursor()
except OperationalError:
print(f"{db_choice} is down !")
#Retrieve the other database
#if the chosen database is down
db_list.remove(db_choice)
db_choice = db_list[0]
print(f"Switching to {db_choice} for READ Query")
print(f"performing READ query on {db_choice}")
return db_choice
def db_for_write(self, model, **hints):
print(f"WRITE OPERATION using default")
return "default"In the simple ReadWriteRouter class we created above:
In the db_for_read method, we randomly return the replica or the default database. This will allow us to balance the read query between the two databases (A better algorithm could be used to select the database to read, but this will suffice for this tutorial).
However, we must put a check in place to know if the database chosen randomly is available to accept connections before returning it. I added the print functions to log the status of the database and to have an idea about which database was returned.
The db_for_write returns the default database as it’s the only database that allows write operations.
Now that we have our router class, we need to tell Django to use this router class by installing it in the DATABASE_ROUTERS in the settings.py file.
The DATABASE_ROUTERS configuration specifies a list path to router class names that tells Django how to route database queries.
Open the setting.py and add the following:
DATABASE_ROUTERS=[
"DJReplica.dbrouter.ReadWriteRouter"
]You can now create migrations for the model class we created earlier and migrate.
Open up a terminal and run the following commands:
$ python manage.py makemigrations
$ python manage.py migrateYou should have the output below:
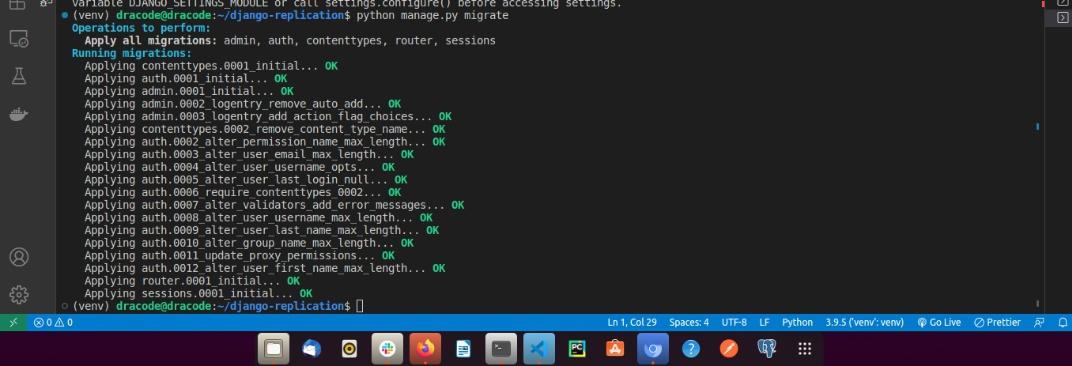
Even though the migration will be performed on the default database, the database table that will be created on the default database will replicate to the replica database.
You can check if the tables are created for the primary_db and the secondary_db in the Postgresql terminal as shown below:
Open the postgresql terminal for the secondary_db running on port 5433 as a postgres user:
$ psql -h 127.0.0.1 -U postgres -p 5433Show all tables:
postgres=# \dtYou should get an output as shown below:
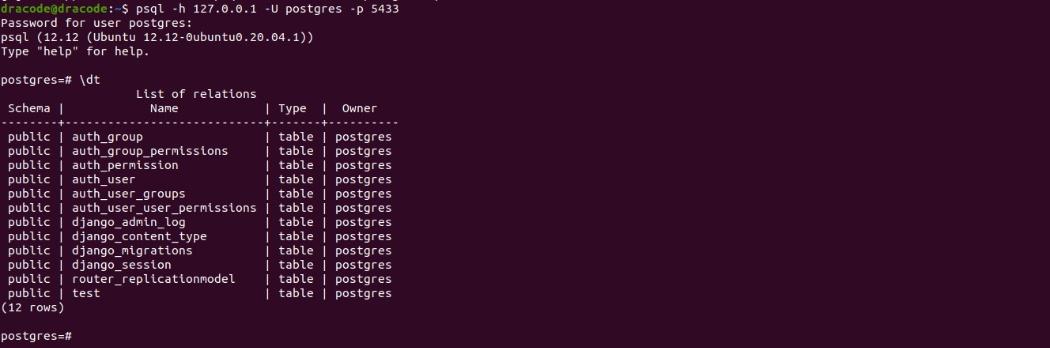
Open the postgresql terminal for the primary_db running on port 5432 as a postgres user:
$ psql -h 127.0.0.1 -U postgres -p 5432Show all tables:
postgres=# \dtYou should get an output as shown above also.
This shows the data has been replicated to the secondary database from the primary database.
Open up the Django shell so that we can run queries:
$ python manage.py shellImport the model and run a write database query:
>>> from router.models import ReplicationModel
>>> ReplicationModel.objects.create(
name="test",
count = 1,
is_available = True,average=2.0)You should get an output as shown below:
WRITE OPERATION using default
<ReplicationModel: ReplicationModel object (1)>Perform a READ operation like retrieving all the model instances:
>>> ReplicationModel.objects.all()Either of the two databases should be returned. You can try this multiple times until both databases have been returned at least once as shown in the image below:
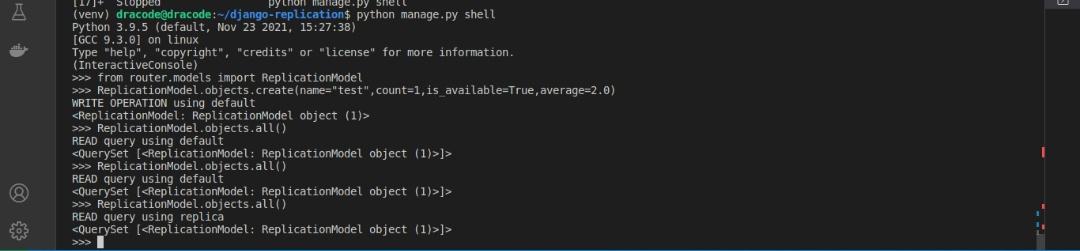
If you try a WRITE operation by explicitly specifying the replica, you should get an error as shown below:
>>> ReplicationModel.objects.using("replica").create(
name="test",count=1,is_available=True,average=2.0)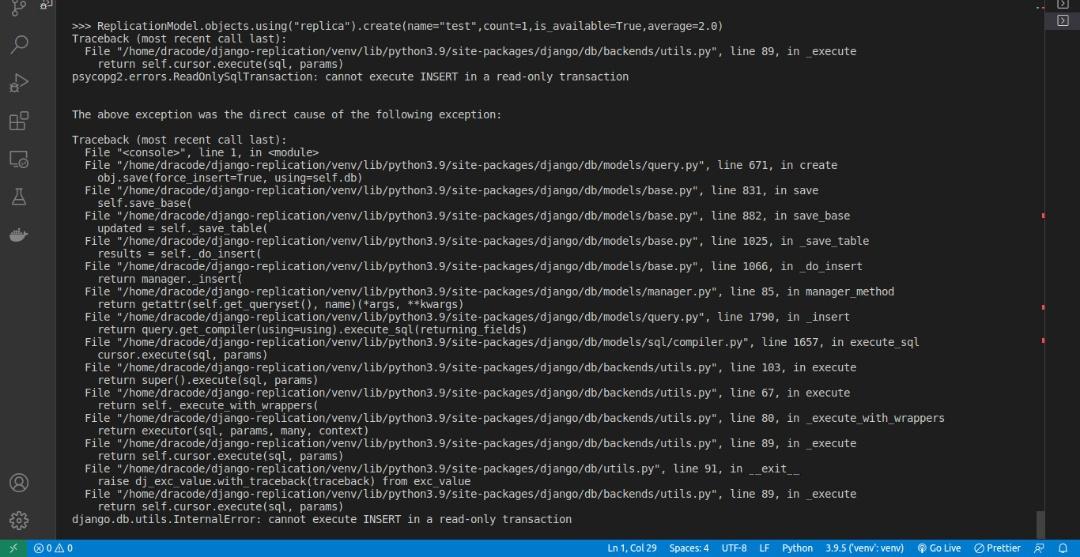
Stop the primary database container and run a Read query on the database:
In the terminal console:
$ docker stop primary_dbIn the Shell console:
>>> ReplicationModel.objects.all()You should get the output below anytime the router returns thedefault database:
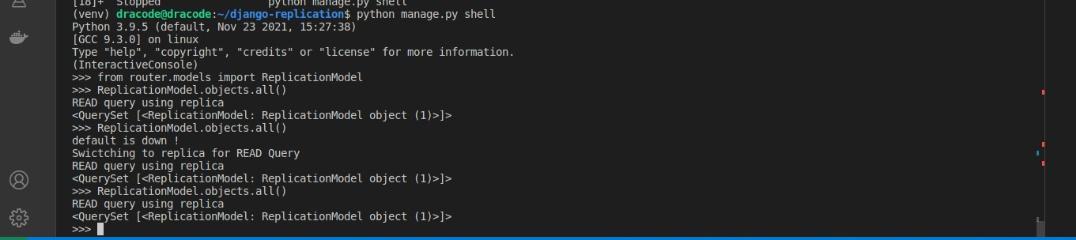
As you would notice, when the default database was initially returned, we got a message that the primary was down and the replica was returned. This will ensure that the replica database can continue to serve our application till the default database is back online.
Conclusion
In this tutorial, we were able to configure two Postgresql databases for data replication and connect the two databases to a Django application that routes the queries to the appropriate database.
There is still a lot a long way to go forward from here. Using the same secondary_db configuration we could configure more replicas and connect them to the primary database. We could also configure one of the replicas to take over the role of the primary database and serve write operations when the primary database goes down.
References
Check out Postgresql’s documentation on Replication Configuration and Django’s guide on managing multiple databases for more details.
And after you’ve set up your Django database replication, you might want to consider optimizing your build process too. For that, you can check out Earthly, a tool that offers some cool build automation features.
Earthly makes CI/CD super simple
Fast, repeatable CI/CD with an instantly familiar syntax – like Dockerfile and Makefile had a baby.







