
Remote Code Execution as a Service



Earthly Compute is an internal service that customers use indirectly via Earthly Satellites and Earthly CI. Now that both Satellites and CI have been publicly announced, we have some stuff to get off their chests that we can finally share.
Compared to our previous experiences, Earthly Compute was a quirky service to build. Nevertheless, we learned some things and made some mistakes, and in this write-up, we’ll share how it went.1
Background
Imagine a service with compute-heavy workloads – maybe video encoding or handling ML inference requests. Customers’ workloads are bursty. A single request can pin many CPUs at once, and throughput matters, but there’s also a lot of idle time. This seems like a great use case for something like Kubernetes or Mesos, Right? You can spread the bursty load of N customers across N machines.

Mesos? Is anything a good use case for Mesos?

Mesos can handle workload types that K8s can’t, and I recall liking Marathon. But anyways, it’s just an example.
We anticipated this type of workload when creating the initial version of Earthly compute. However, there was one issue that made container orchestration frameworks unsuitable: the workload. Earthly compute needs to execute customer-submitted Earthfiles, which are not dissimilar to Makefiles. Anything you can do on Linux, you can do in an Earthfile. This meant – from a security point of view – we were building remote code execution as a service (RCEAS).

Earthfiles are executed inside runC for isolation, and you have to declare your environment, so it’s not exactly like running make. It’s more like ./configure && make inside a container.
RCEAS is not a good fit for Kubernetes. Container runtimes are excellent isolation layers but aren’t a sufficient security barrier. Container break-out vulns do come up and, in the worst case, would lead to nefarious customers being able to access and interfere with other customers’ builds. What we needed was proper virtualization.
What I initially wanted was Kubernetes but for managing VMs. Either firecracker, Kata or gvisor VMs. They’d all provide the isolation we need – and we will be exploring firecracker in the near future – but even without that, things turned out well.
Earthly Compute V1
Our first version used separate EC2 instances per client to properly separate clients’ compute. The first ‘customer’ of this service was dubbed Earthly Satellites. It was command line only, and you used Earthly like you usually do, except the build would happen on the satellite you programmatically spun up.
Earthly on your local. Satellites in the cloud. Get it?
Earthly, our build tool, is open source and usable by anyone. We wanted to draw some clear separation between it and our CI solution but still make transitioning to CI very smooth.
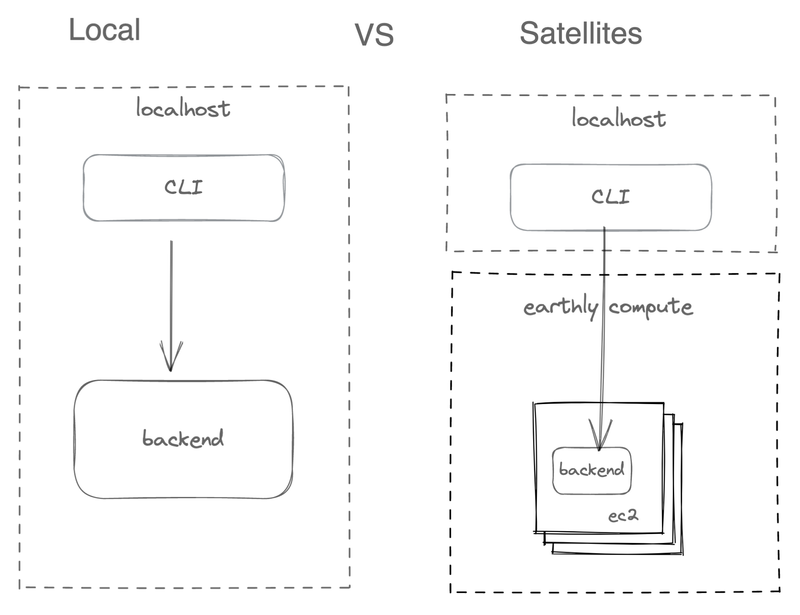
Earthly has always had a front-end CLI program and a backend build service. So when you run Earthly CLI, it talks to the backend over gRPC. This works the same in Satellites. It’s just the gRPC service is now in EC2.
To get this working, we had to programmatically spin up EC2 instances, auth build requests and route them to the correct node.
We did this with a gRPC proxy.
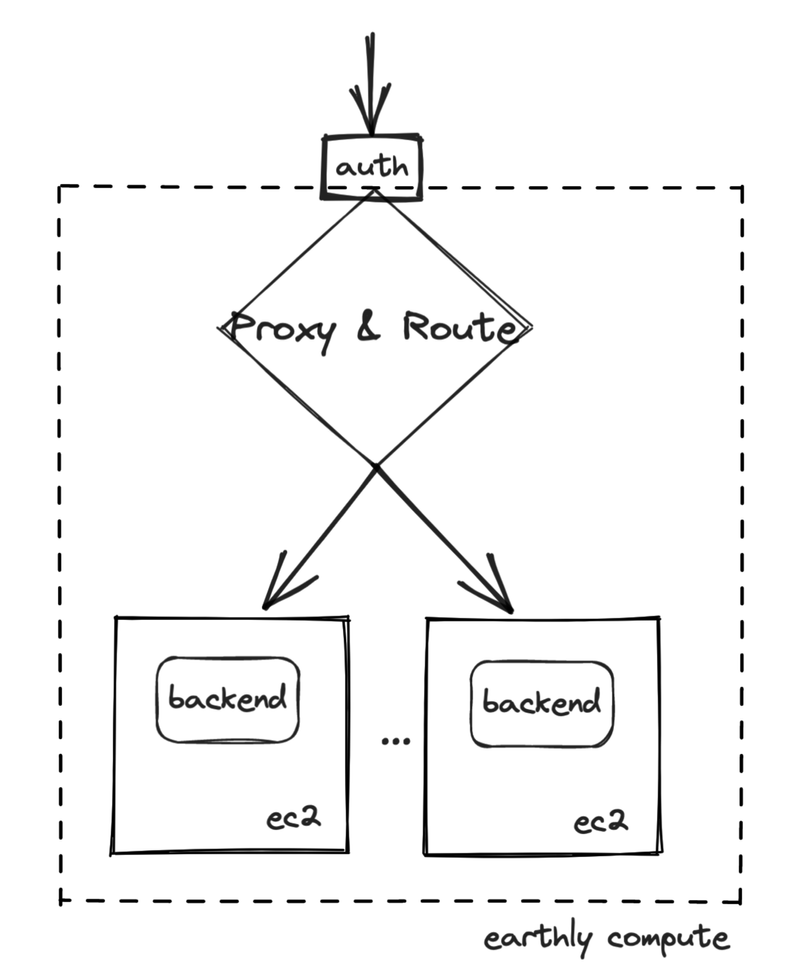
Once we built this feature, we tested it with our internal builds and then got beta volunteer companies to start testing it. Most customers saw a significant speed-up from their previous build times, but adoption was sometimes bumpy.
Turns out CI workloads vary a lot.
Disks filled up with cache faster than could be GC’d. Networking issues happened. Average builds would be fast but with tail latencies that seemed to go to infinity.
Getting the first version of Satellites working smoothly, with all kinds of different CI jobs, was an adventure.
Even before all this, Earthly supported shared remote caching. But with the kinks worked out, something else became very apparent. The disk on the satellite instance acting as a fast local cache makes a big difference.
The Earthly blog was an early user of Satellites, and it was surprising how well it worked.
Jekyll generates all these optimized images in different sizes for different browsers, and there is a ton of them. Previously I was caching them in GitHub actions, and that helped.
But when you have a ton of small files as a build output, having them cached locally on a beefy machine made a huge difference.
Yeah, ephemeral build servers sound great operations-wise: Spin one up, run your build, and destroy it when it’s finished or you need space.
But, throughput-wise, it will be faster if I have a fast machine just sitting there that already has everything up to the last commit downloaded, built, and locally cached.
V2: Sleep Time
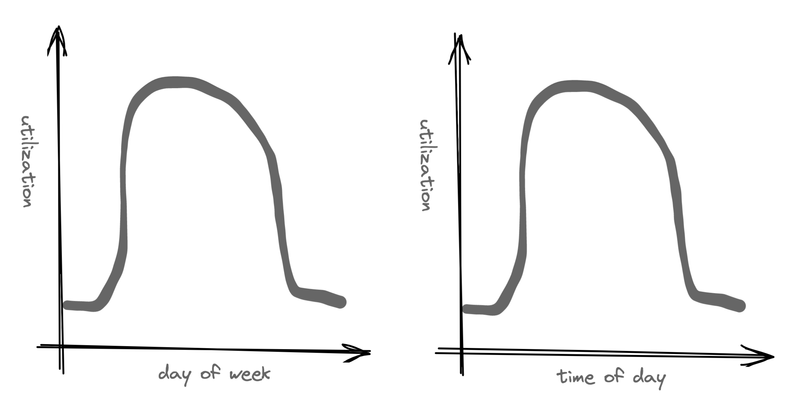
Once we had this EC2 solution and had worked out the kinks, it was time to optimize the price tag. Looking at our beta testers builds mainly happened when developers were working. And AWS bills us by the minute, so a simple solution would be to shut them down when they aren’t in use. That saves money but would add start-up latency to a build that tried to run when its backing instance was down.
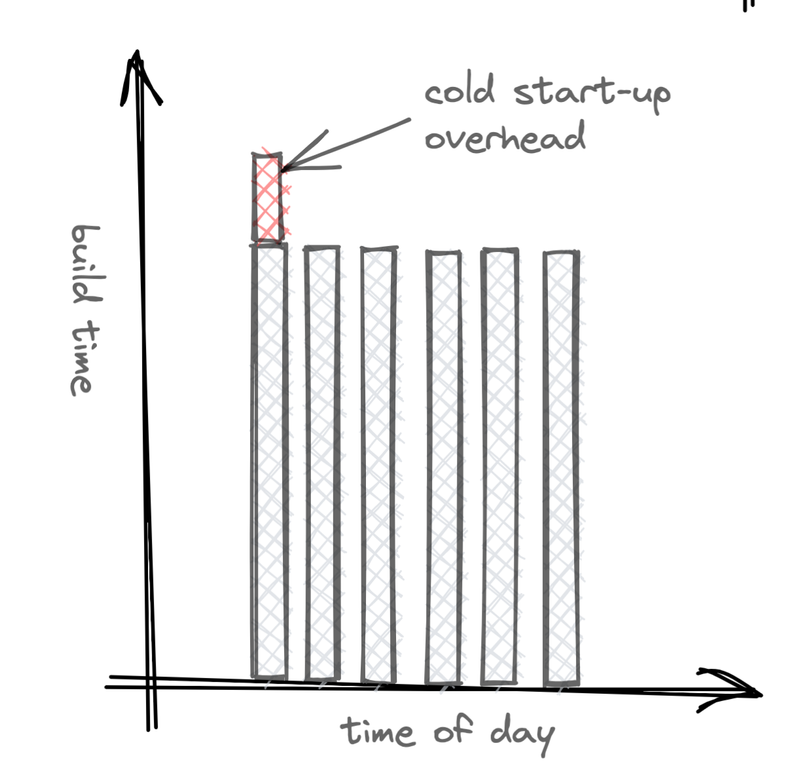
Specifically, using the RunInstances API, an Amazon Linux instance can be started and be back listening on TCP within ~10 seconds.
So the latency is minimal in theory.
It’s a lot like the EC2 instances are in an LRU cache. If they aren’t used in a while, they’re suspended, which is like cache eviction, and then they get lazily woken up on the subsequent request. That cache miss adds seconds to build time but saves hours of compute billing.
The first sleep implementation used the AWS API to shut down an instance after 30 minutes of inactivity, and when someone queued a new build for that instance, we started it back up. Hooking this sleep stuff up presents some problems though: if we sleep your build node, the gRPC request will fail. This led to the need for the router to not just route requests but wake things up.
But waking things up adds complexity. To the outside world, your satellite is always there, but inside the compute layer, we have to manage not just sleeping and waking your satellite but ensuring requests block while this happens. Also, we have to guarantee the machine only gets one sleep or wake request at a time and that it’s given time to wake up.
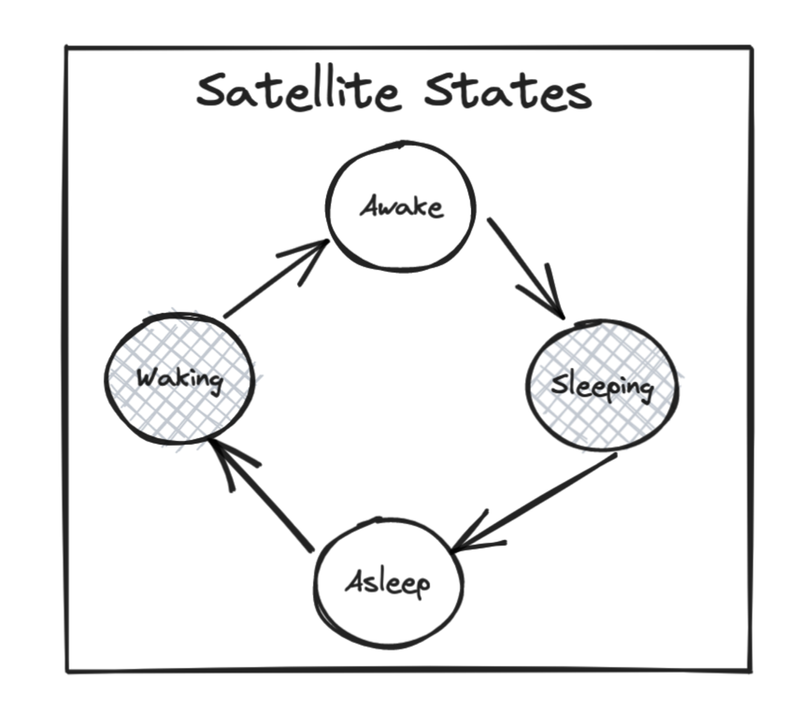
It’s kind of like a distributed state machine. There can be many different builds starting at the same time that are all trying to use the same satellite.
To make the process resilient, multiple requests to start builds need to coordinate with each other so that only one of them actually calls ‘wake’ and the rest simply queue and wait for the state change.
With the auto-sleep and coordinated wake-up inside Earthly Compute, our AWS bill got smaller, and no one noticed the start-up time.
Well, almost. Except, occasionally, that start-up time got much larger…
V3: Hibernate Time
It’s true. You can start up an EC2 instance and have it accepting TCP requests in 10-30 seconds. But our usage graphs showed that randomly some builds were taking an extra minute or more to start up. The problem was our build runner, BuildKit. Buildkit is not designed for fast start-ups. It’s designed for throughput. When it starts, it reads in parts of its cache from the disk, does some cache warmups, and possibly even some GC.
We investigated getting Buildkit to start faster and did get some improvements there, but then we had an even better idea: using hibernate instead of stop.
x86 EC2 instances support hibernate. With hibernate, the contents of memory are written to disk, and then on wake up, the disk state is written back to memory.
It’s the server version of closing your laptop lid, and it’s so much faster because nothing needs to start back up.
The only downside is the arm instances don’t support it.
And so, with faster BuildKit start-up and all our X86 instances using suspend, the service looked good. Then we ran into resource starvation issues. If a build uses 100% of the CPU long enough, the health checks fail. But Cgroups came to the rescue. We were able to limit CPU and other resources to reasonable levels.
We are limiting CPU to 95%, but it’s not just CPU that is an issue. Beta customers had builds that filled the whole disk, leaving no room to GC the cache, so we set disk limits. Customers used all the memory and swap, then got killed by OOM-Killer, so we had to limit memory.
I even had to properly set oom_score_adj, so Linux would kill the parent process and not hang the build.
We learned a lot about Linux.
Today
With all that in place, and some fine-tuning, we saved much compute time.
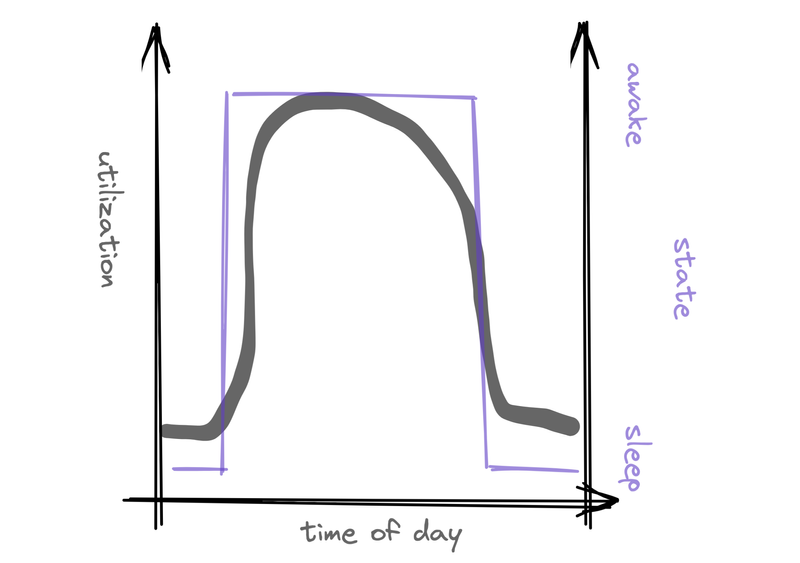
And with the service now powering both Satellites and Earthly CI, we are now offering secure and fast ‘remote execution as a service.’
It’s actually not remote code execution as a service, though.
For users, it’s just a faster CI. It’s the build runner behind a CI service. “remote code execution as a service” is just the name Corey used internally as a joke.
But – operationally – it is an arbitrary code execution service. I called it that because it’s something we have to contend with, and it scared me a little.
Speaking of which, stay tuned for the next article, which will invariably be about how we are fighting off crypto-miners 😀.
See the GA announcement for Earthly Satellites and the release announcement for Earthly CI if you’d like to learn more about the products this service powers. And stay tuned for more sharing of engineering complaints challenges in the future.
I’d like to thank Brandon and Corey for sharing the journey of building this service publicly - challenges and successes. Your openness is appreciated. - Adam↩︎






