
How to Use Python’s Subprocess Module

We’re Earthly. We make building software simpler and therefore faster. If you’re interested in a simple and containerized approach to CI that works well with Python and everything else then check us out.
Python ships with built-in modules such as os and sys that provide some functionality to interact with the underlying operating system. However, it may sometimes be more convenient to run system programs from within a Python script. Python’s subprocess module provides ready-to-use functionality to run external commands, capture and process outputs, redirect output to files and I/O streams, and much more!
This guide will help you get started with the subprocess module in Python. By the end of this tutorial, you’ll have learned how to:
- Run Bash commands inside Python scripts
- Analyze what happens when an external command fails
- Pipe the output of one subprocess to the input of another subprocess
- Change the environment in which a subprocess runs
Let’s begin!
Python Subprocess Module: The Basics
Prerequisites: To follow along with this tutorial, you should have Python 3.7 or a later version installed on your machine.
⚠️ If you’re on a Windows machine, we recommend using Git Bash or installing the Windows Subsystem for Linux (WSL) to code along. If you prefer using other code editors or IDEs on Windows, you should run the Windows equivalents of some of the Bash commands used in this tutorial.
The subprocess module is built into the Python standard library, so you can import it into your working environment:
import subprocessDownload the code and follow along
How Does Subprocess Execution Occur in Python?
After importing the subprocess module, you can call the run() function with the syntax: subprocess.run(command) to run an external command. This call to the run() function invokes a subprocess.
When a subprocess is invoked, the following actions occur under the hood:
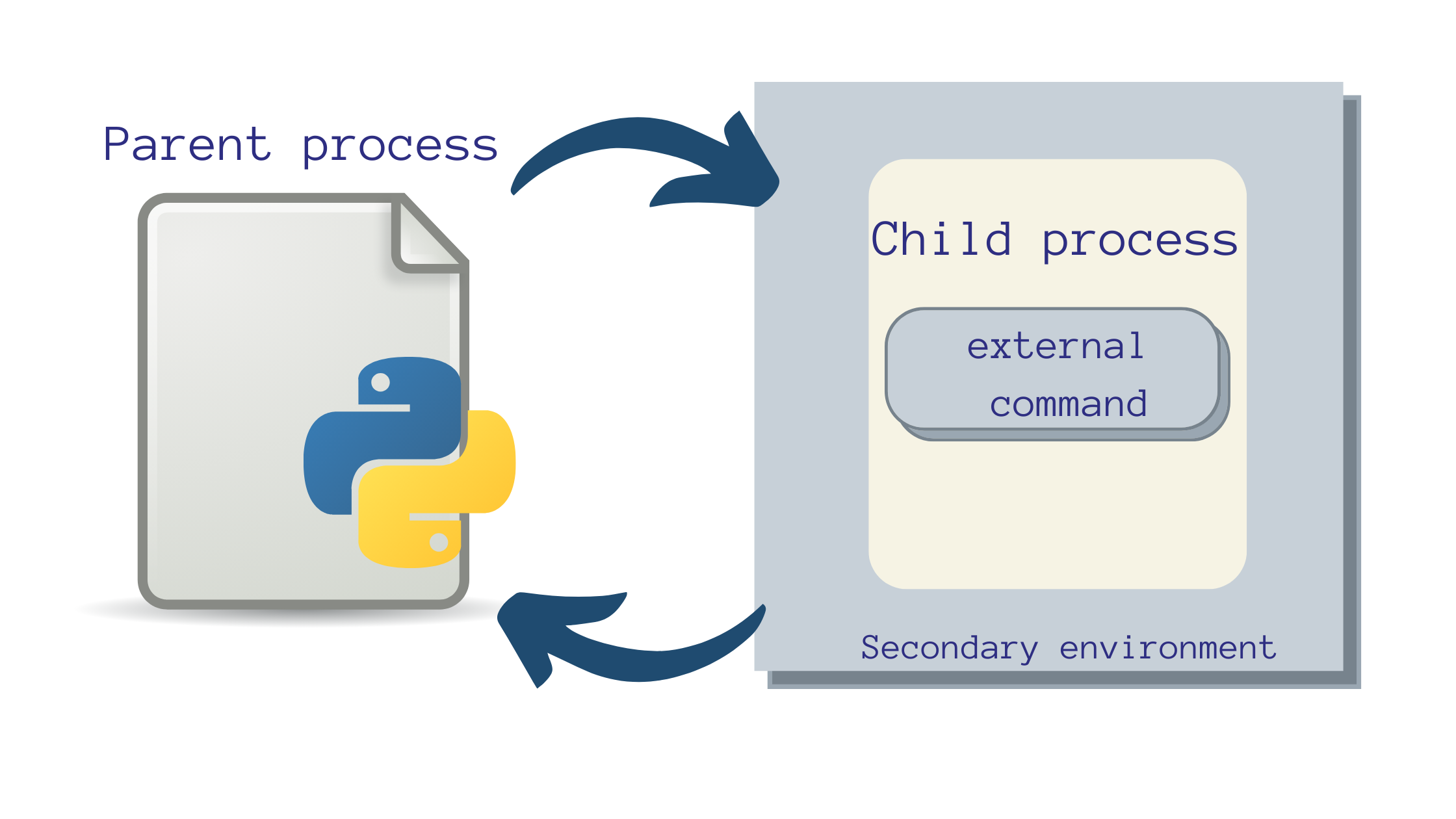
- The Python script inside which you’re running the external command is the parent process and the subprocess is the child process.
- Upon starting a subprocess, the control is transferred from the parent process to the child process.
- The child process executes the external command inside a secondary environment.
- After the child process finishes executing, the control returns to the parent process.
How to Run a Subprocess With subprocess.run()
Calling the subprocess.run() function with an external command or program as the argument prints out the output of the command onto the console. The function call also returns a CompletedProcess object which has a set of useful attributes.
As our first subprocess, let’s run the ls command that lists the contents of the working directory:
process_1 = subprocess.run("ls")
print(process_1)
print(process_1.args)
print(process_1.returncode)
print(process_1.stdout)
py_logging main.py py_unit_testing string_manipulation
CompletedProcess(args='ls', returncode=0)
ls
0
NoneIn the above output:
- The contents of the working directory are printed onto the console.
- The
argsattribute contains the arguments passed to therun()function. - The
returncodeattribute indicates whether the command ran successfully; A return code of zero indicates successful execution. - If the output of the command is captured, the
stdoutattribute contains the output; if we do not capture the output,stdoutisNone.
Subprocess Popen Constructor
In the subprocess module, the Popen class handles the creation and management of subprocesses. However, the run() function is recommended for invoking subprocesses and suffices for most common use cases.
Running Bash Commands With Arguments
To run Bash commands with arguments, you can specify the name of the command followed by the arguments that it takes. The name of the command and its arguments should be passed in as a list of strings.
We’ll now run the ls command to list the contents of the py_logging directory.
process_2 = subprocess.run(["ls","py_logging"])
print(process_2)
print(process_2.args)
print(process_2.returncode)
print(process_2.stdout)
custom_logger.py logger.py
CompletedProcess(args=['ls', 'py_logging'], returncode=0)
['ls', 'py_logging']
0
NoneYou can also specify the command as a long string and call Python’s split() method on it. By default, the split() method splits the string on all occurrences of whitespace and returns a list of strings. This list of strings can be used in the call to the run() function.
command = ...
command_list = command.split()To parse more complex commands—where whitespace is not the correct separator to split on—use shlex.split() that splits the command string using a shell-like syntax.
import shlex
command = ...
shlex.split(command)Let’s take an example:
Suppose you’d like to create a directory named ‘Foo Bar’. The code cells below show how the command string is split when we use the split() method and shlex.split().
>>> command_str = "mkdir 'Foo Bar'"
>>> command_str.split()
['mkdir', "'Foo", "Bar'"]As seen, the split() method splits command_str on all whitespaces. When run as a subprocess, the above command will create two directories, 'Foo and Bar', which is not what we want!
>>> import shlex
>>> shlex.split(command_str)
['mkdir', 'Foo Bar']Using shlex.split() returns the command list ['mkdir', 'Foo Bar']. Running this command list as a subprocess creates the ‘Foo Bar’ directory.
When you set the shell parameter to True, you can pass in the command as a single string—without splitting it into a list of strings.
process_3 = subprocess.run("ls py_logging",shell=True)
print(process_3)
print(process_3.args)
print(process_3.stdout)custom_logger.py logger.py
CompletedProcess(args='ls py_logging', returncode=0)
ls py_logging
None⚠️ If you set shell = True, an instance of the underlying shell is used to run the command. Because this is susceptible to shell injection attacks, avoid setting shell = True to run commands that take in user inputs.
How to Capture and Redirect Subprocess Outputs
Running subprocess.run(command) prints the output of the command onto the console, and the stdout attribute is None by default if we don’t capture the output. When you run Bash commands such as chmod to change file permissions or the sleep command, you don’t need to process the output. However, you may sometimes need to capture the outputs and use them in next steps in your program.

To capture the output of a command for further processing, you can set the capture_output argument to True when calling the run() function.
process_4 = subprocess.run("ls",capture_output=True)
print(process_4.stdout)Note that the output of process_4 is not printed onto the console anymore. The stdout attribute of the CompletedProcess object process_4 contains the output as a string of bytes.
b'py_logging\nmain.py\npy_unit_testing\nstring_manipulation\n'You can call the decode() method on the value of stdout to access the output as a normal Python string.
process_4 = subprocess.run("ls",capture_output=True)
print(process_4.stdout.decode())py_logging
py_subprocess.py
py_unit_testing
string_manipulationIf you set text to True, the output is captured as a Python string, thereby eliminating the need for decoding the stdout value.
process_5 = subprocess.run("ls",capture_output=True,text=True)
print(process_5.stdout)py_logging
py_subprocess.py
py_unit_testing
string_manipulation📋 A Note on Subprocess Pipe
Under the hood, setting capture_output to True redirects both the output and the errors to subprocess.PIPE. Therefore, you can also set stdout to subprocess.PIPE when calling the run() function.
process_6 = subprocess.run("ls",stdout=subprocess.PIPE,text=True)
print(process_6.stdout)py_logging
main.py
py_unit_testing
string_manipulationHow to Redirect Subprocess Output to a File
You can redirect the output of a subprocess to a text file by setting the stdout attribute to a valid file object. In this example, the contents of the working directory, including the contents.txt file are listed in the contents.txt file.
with open('contents.txt','w') as f_obj:
subprocess.run("ls",stdout=f_obj,text=True)What Happens When a System Program Fails?
In the examples we’ve coded thus far, the external programs ran successfully. In practice, we’ll run into errors if the external programs do not exist in our development environment or are called with invalid arguments. For example, trying to run a git commit as an external command (subprocess) when I don’t have Git installed.

The CompletedProcess object’s returncode attribute tells whether or not the execution of the external command was successful. A non-zero returncode indicates an error in running the command. The stderr attribute contains information on the error.
When we try to list the contents of a directory that doesn’t exist, the returncode of the CompletedProcess object process_7 is 2 (non-zero) and its stderr attribute contains the output as a string of bytes.
process_7 = subprocess.run(["ls","non-existent-directory"],\
capture_output=True)
print(process_7.returncode)
print(process_7.stderr)2
b"ls: cannot access 'non-existent-directory': No such file or directory\n"You can also capture errors in the stderr attribute by explicitly setting the stderr argument to subprocess.PIPE when calling the run() function.
process_8 = subprocess.run(["ls","non-existent-directory"],\
stderr=subprocess.PIPE)
print(process_8.stderr)
b"ls: cannot access 'non-existent-directory': No such file or directory\n"To check if the external command ran successfully, here’s a summary of methods we’ve learned so far:
- Check the
returncodeattribute of theCompletedProcessobject. A non-zero return code indicates that there was an error running the external command. - Access the
stderrattribute of theCompletedProcessobject. The error message instderrhas diagnostic information on what went wrong when the external command was run. - If you anticipate that an external command may fail, you can explicitly set the
stderrattribute tosubprocess.PIPEto redirect errors tostderr.
In all of the above methods, Python does not throw an error when the external command fails. However, it might help to get an error message when running the Python script if the external command fails to run successfully. For this, you can set the optional check parameter to True in the run() function call. If the external command fails to run, Python throws a CalledProcessErrorexception.
process_9 = subprocess.run(["ls","non-existent-directory"],\
capture_output=True,check=True)
Traceback (most recent call last):
File "main.py", line 38, in <module>
process_9 = subprocess.run(["ls","non-existent-directory"],\
capture_output=True,check=True)
File "/usr/lib/python3.8/subprocess.py", line 516, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command '['ls', \
'non-existent-directory']' returned non-zero exit status 2.How to Raise a TimeoutExpired Exception

We’ve learned that when a subprocess is invoked, the control is transferred from the parent process (Python script) to the child process that runs the command.
The control returns to the parent process only after the child process finishes execution which can sometimes be challenging. For example, the subprocess may involve pinging a URL when you’re working offline. In this case, the parent process waits for transfer of control from the child process; but the child process never finishes its execution.
To address this, you can set a timeout value (in seconds) when invoking a subprocess. If the subprocess does not finish executing within the value specified by the timeout argument, a TimeoutExpired exception is raised.
In this example, the Bash command sleep 10 requires 10 seconds to finish but setting timeout to 2 seconds raises the TimeoutExpired exception.
process10 = subprocess.run(["sleep","10"],capture_output=True,\
check=True,timeout=2)
Traceback (most recent call last):
File "main.py", line 40, in <module>
process_10 = subprocess.run(["sleep","10"],capture_output=True,\
check=True,timeout=2)
File "/usr/lib/python3.8/subprocess.py", line 495, in run
stdout, stderr = process.communicate(input, timeout=timeout)
File "/usr/lib/python3.8/subprocess.py", line 1028, in communicate
stdout, stderr = self._communicate(input, endtime, timeout)
File "/usr/lib/python3.8/subprocess.py", line 1869, in _communicate
self._check_timeout(endtime, orig_timeout, stdout, stderr)
File "/usr/lib/python3.8/subprocess.py", line 1072, in _check_timeout
raise TimeoutExpired(
subprocess.TimeoutExpired: Command '['sleep', '10']' timed \
out after 2 secondsThe above traceback for the TimeoutExpired exception is difficult to parse. We can use Python’s try and except statements to handle the TimeoutExpired exception.
The general syntax to use try-except statements is as follows:
try:
# doing this
except ThisError:
# do this when ThisError occursWhen the TimeoutExpired exception occurs, we now get a simple error message instead of the hard-to-parse traceback.
try:
process10 = subprocess.run(["sleep","10"],capture_output=True,\
check=True,timeout=2)
except subprocess.TimeoutExpired:
print("subprocess timed out")
subprocess timed out⏰ The TimeoutExpired Exception Doesn’t Kill the Child Process
The TimeoutExpired exception raised—when a subprocess fails to complete executing within a specified duration—does not implicitly kill the child process. If there are many such subprocesses in a Python script, it would help to kill the child processes after they’ve timed out.
For this, we need to use the Popen constructor to run the external command. The timeout value is passed to the communicate() method when called on the subprocess object. This method returns the stdout and stderr values as a tuple. When the TimeoutExpiredexception is raised upon timeout, the child process is killed and the communication is deemed complete.
p1 = subprocess.Popen(["sleep","10"])
try:
std_out,std_err = p1.communicate(timeout=1)
except subprocess.TimeoutExpired:
p1.kill()
std_out,std_err = p1.communicate()How to Pipe Subprocess Outputs to Inputs of Subprocesses
You may sometimes need to chain commands such that the output of one process is the input to the next command in the chain. We know that we can capture the output of a command in the stdout attribute. The run() function provides an optional input parameter which you can set to the stdout of another subprocess. This way, you can pipe subprocess outputs to the input of another subprocess.
Consider the following example, where we’d like to run each of the commands as a subprocess. The output of the first subprocess is the input to the second.
- Run the
catcommand to display the contents of a text file. - Search through the file’s contents for the occurrence of a specific string using the
grepcommand.
process1 = subprocess.run(["cat","sample.txt"],capture_output=True,\
text=True)
process2 = subprocess.run(["grep","-n","Python"],capture_output=True,\
text=True,input=process1.stdout)
print(process_2.stdout)
3:with Python programming is to
4:start a Python REPL and work your way through simple exercises!How to Change the Environment of a Subprocess

You can change the environment in which a subprocess runs by setting the env parameter to a modified environment. The secondary environment in which a subprocess runs is inherited from the environment of the parent process. This is the default behavior and the env parameter is set to its default value None. To change this default execution environment, you should set the env parameter to the modified environment variable dictionary, when calling the run() function.
In Python, the environ() function in the os module returns the environment variables dictionary. Instead of modifying the underlying environment variables directly, you can create a copy of the dictionary and update one or more environment variables.
In the following example, we update the PATH environment variable by adding a new directory and set the env parameter to new_env.
import os
new_env = os.environ.copy()
new_env["PATH"] = os.pathsep.join(["/testapp/",new_env["PATH"]])
process_now = subprocess.run(["ls"],env=new_env)Conclusion
I hope this tutorial helped you understand how to use Python’s subprocess module. Here’s a summary of what you’ve learned.
- To run an external command within a Python script, use
subprocess.run(command), wherecommandis a string or a list of strings (when running commands with arguments). Therun()function returns aCompletedProcessobject. - You can set
capture_output = Trueto capture the output as a string of bytes in thestdoutattribute, which you can decode by calling thedecode()method. Settingtext = Trueeliminates the decoding step. You can redirect output to files by setting thestdoutargument to a valid file object. - When an external program fails to run, the
returncodeis non-zero and the error information is available in thestderrattribute of theCompletedProcessobject. - Setting the
checkparameter toTrueraises aCalledProcessErrorwhen the external command fails. You can optionally set thetimeoutparameter to raise aTimeoutExpiredexception when the subprocess fails to complete execution within a specified time-frame. - To change the environment in which a subprocess runs, set the
envparameter to the modified environment. You can update one or more environment variables by creating a copy of the environment variables dictionary.
If you need to run external programs within the Python application, try to run them as subprocesses. You can also leverage Python’s threading capabilities to run subprocesses concurrently.
And if you are looking for a more repeatable way to build Python, take a look at Earthly. Better Dependency Management in Python is a great introduction to using Earthly with Python.
Earthly makes CI/CD super simple
Fast, repeatable CI/CD with an instantly familiar syntax – like Dockerfile and Makefile had a baby.







