
Advanced MongoDB Features with PyMongo

We’re Earthly. We simplify and speed up software building using containers. It can even make Python CI a breeze. Check it out.
MongoDB is a powerful and flexible NoSQL database that has become increasingly popular in recent years due to its ability to handle large amounts of data and its support for a wide range of data types. PyMongo is a Python library that provides a simple and efficient way to interact with MongoDB using the Python programming language.
This article is a follow-up to the “How to get started with PyMongo” article where we:
- Created a MongoDB database.
- Connected to the database using the PyMongo library.
- Performed CRUD operation on the database with the PyMongo library.
This tutorial assumes that you have read and understood the concepts covered in the previous article.
In this tutorial, you will learn about schema validation, data modeling, and advanced MongoDB queries.
Database Design

In the MongoDB database that you will work on in this tutorial, you will create two database collections: a book collection and an author collection.
The book collection will store information about a book, such as the title, publication_date, copies, and other relevant details. The author collection will store information about an author, such as the name, and other relevant details.
To establish a relationship between these two collections, you can create a reference between them. A reference is a field in one collection that stores the unique identifier of a document in another collection. In this case, you can add a field called authors to the book collection that stores a list of the authors who wrote the book.
With this design, you can reference a single author can be in multiple documents in the book collection, this indicates that they have written multiple books. This allows you to easily retrieve all the books written by a particular author by querying the book collection and using the authors field to filter the results.
Atlas Admin Access
Before proceeding with the tutorial, you will need to grant your MongoDB user an admin privilege in Atlas because the collMod command that you will use in this tutorial (more about the collMod command later) requires admin privilege. If you do not have an admin privilege, you will encounter an error stating “user is not allowed to perform an action”.
Follow the steps below to grant admin privileges to your MongoDB user:
Click on Database Access in your MongoDB Cluster:
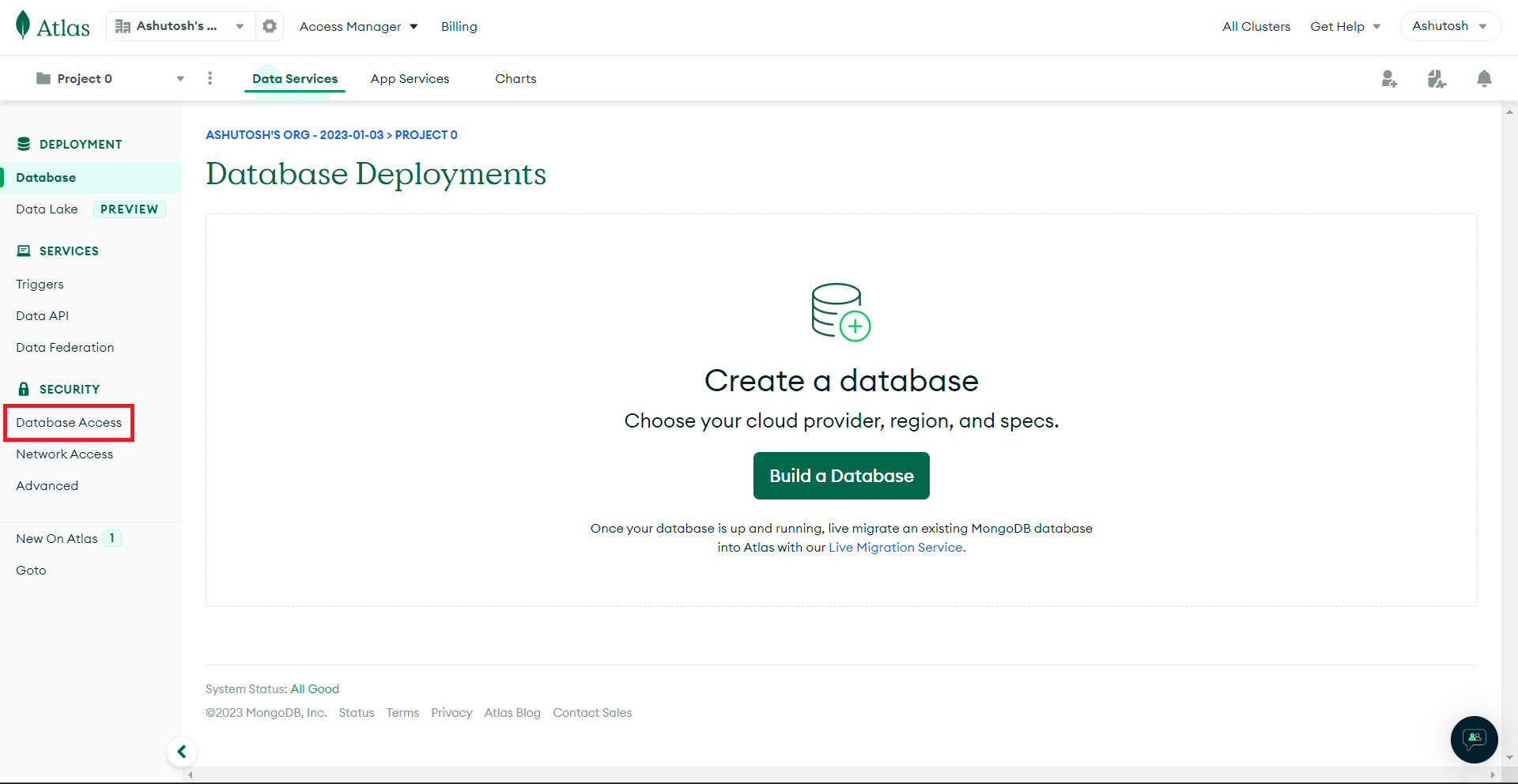
Click on the Edit button:
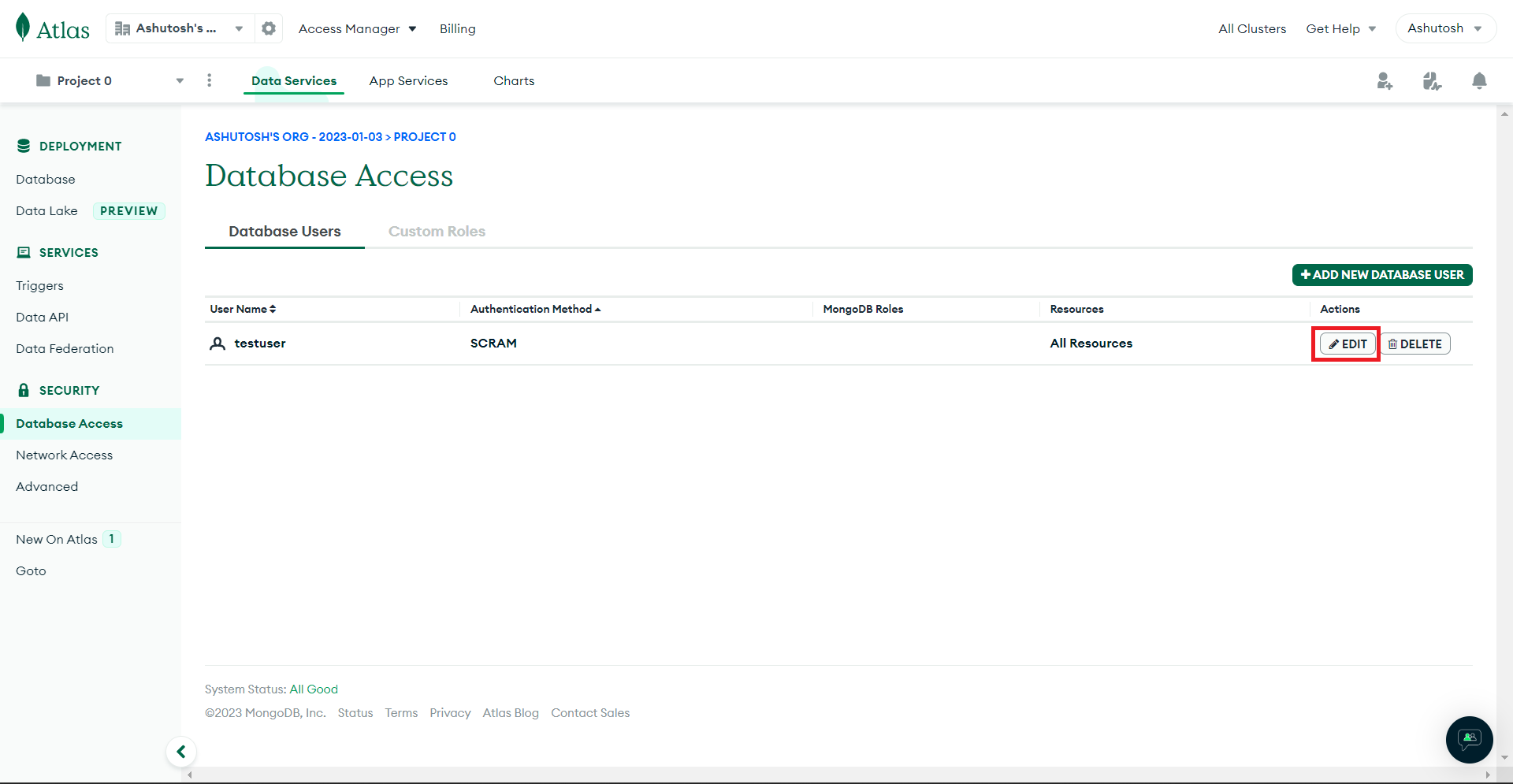
Select Atlas admin as the role in the Database User Privileges:
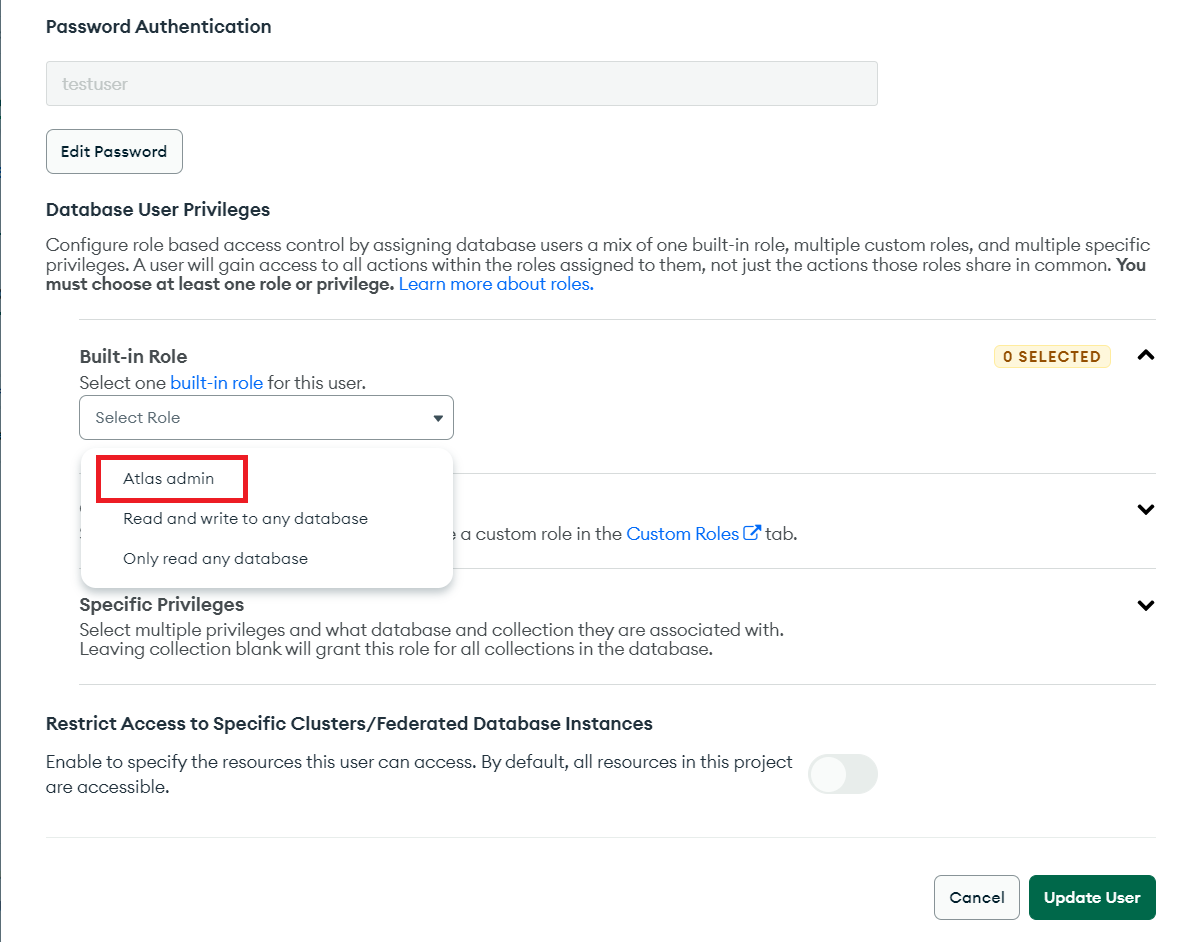
Add
&authSource=adminat the end of your MongoDB connection string:
connection_string = f"mongodb+srv://{USERNAME}:{PASSWORD}\
@cluster0.d0mjzrc.mongodb.net/?retryWrites=true&w=majority&authSource=admin"Schema Validation
MongoDB schema validation is a feature that allows you to specify the structure and data types of the documents in a collection. When you enable schema validation for a collection, MongoDB will check the structure and data types of any new documents that you insert or existing documents you update to ensure that they conform to the schema you specify. This ensures data consistency and integrity within your database. For example, if you have a book collection that requires a title field, an author field, and a publication_date field, you can use schema validation to ensure that all the database documents in the collection adhere to this structure.
To enable schema validation in MongoDB, you can use the validator option when creating or updating a collection. The validator option takes a document that specifies the fields and data types that the documents in the collection are required to have. You can learn more about Schema Validation from the official MongoDB documentation.
Here’s what you’d have in your Python file from the last tutorial where you created the library_db database:
from decouple import config
from pymongo import MongoClient
# Fetching environment variables
USERNAME = config('MONGODB_USERNAME')
PASSWORD = config('MONGODB_PASSWORD')
connection_string = f"mongodb+srv://{USERNAME}:{PASSWORD}@\
cluster0.d0mjzrc.mongodb.net/?retryWrites=true&w=majority&authSource=admin"
# Creating a connection to MongoDB
client = MongoClient(connection_string)
# Creating a new database
library_db = client.library_dbNotice the
&authSource=adminat the end of the connection string. TheauthSourcespecifies the database name associated with the user’s credentials, meaning that the user credentials are stored in theadmindatabase. Learn more aboutauthSourcein this documentation.
Creating the Book Collection Validator
You can create a book collection using the PyMongo create_collection method as shown below:
def create_book_collection():
try:
library_db.create_collection("book")
except Exception as e:
print(e)If the collection already exists, PyMongo will raise an exception. You will need to handle the exception to prevent the code from crashing. This is useful for handling cases where the collection may already exist, and you want to handle this error gracefully.
Next, you can define a validator for the book collection using the $jsonSchema operator. The $jsonSchema operator is a MongoDB operator that allows you to specify a JSON schema to validate documents in a collection. The operator is used in conjunction with the validator option when creating or updating a collection.
The $jsonSchema operator takes in a JSON Schema object which is based on the JSON Schema specification, a widely used standard for defining the structure of JSON documents.
You can define the schema in a different file and import it in the working file. But for the sake of simplicity, add the following code in the create_book_collection function after the try-except block:
book_validator = {
"$jsonSchema": {
"bsonType": "object",
"required": ["title", "authors", "publication_date", "type", \
"copies"],
"properties": {
"title": {
"bsonType": "string",
"description": "must be a string and is required"
},
"authors": {
"bsonType": "array",
"description": "must be an array and is required",
"items": {
"bsonType": "objectId",
"description": "must be an objectId and is required"
},
"minItems": 1,
},
"publication_date": {
"bsonType": "date",
"description": "must be a date and is required"
},
"type": {
"enum": ["hardcover", "paperback"],
"description": "can only be one of the enum values and \
is required"
},
"copies": {
"bsonType": "int",
"description": "must be an integer greater than 0 and \
is required",
"minimum": 0
}
}
}
}The bsonType property specifies the data type that the validation engine will expect to find in the database document. The expected type for the document itself is object, meaning that you can only add objects to it. The schema specifies that each “object” in the collection must have the following required fields:
title(string)authors(array of objectIds)publication_date(date)type(enum with values “hardcover” and “paperback”)copies(integer greater than 0)
The schema also specifies additional constraints on the data types and values of these fields, such as the minimum number of items in the authors array and the values that the database will allow for thetype field.
You can use this schema to enable schema validation on a book collection in a MongoDB database. This ensures that all the documents in the collection adhere to the structure and data types that you specified in the schema.
Next, you need to run thecollMod command on the book collection. The command is used to modify the properties of an existing collection.
Add the following code in the create_book_collection function:
library_db.command("collMod", "book", validator=book_validator)When the command is executed, the schema you specified in the book_validator object will be set as the schema validator for the book collection.
If you print the output of the above command, you will see a similar output as below:
{'ok': 1.0, '$clusterTime': {'clusterTime': Timestamp(1673361108, 3), \
'signature': {'hash': b'\x7f\xd8\xa5G\xff\xb2\xca\xb7\xc0\x9e\x14\xde\x88\xc6\x9b2\x04\xbc\xff\xce', \
'keyId': 7142151715528114178}}, 'operationTime': Timestamp(1673361108, 3)}In the output, the 'ok': 1.0 means the operation was successful.
Learn more about Database Commands.
The code now looks as shown below:
def create_book_collection():
# Creating a new collection
try:
library_db.create_collection("book")
except Exception as e:
print(e)
book_validator = {
"$jsonSchema": {
"bsonType": "object",
"required": ["title", "authors", "publication_date", \
"type", "copies"],
"properties": {
"title": {
"bsonType": "string",
"description": "must be a string and is required"
},
"authors": {
"bsonType": "array",
"description": "must be an array and is required",
"items": {
"bsonType": "objectId",
"description": "must be an objectId and is required"
},
"minItems": 1,
},
"publication_date": {
"bsonType": "date",
"description": "must be a date and is required"
},
"type": {
"enum": ["hardcover", "paperback"],
"description": "can only be one of the enum values and \
is required"
},
"copies": {
"bsonType": "int",
"description": "must be an integer greater than 0 and \
is required",
"minimum": 0
}
}
}
}
library_db.command("collMod", "book", validator=book_validator)
create_book_collection()Creating the Author Collection Validator
You can create a function to create an author collection and specify the schema validator just as you created for the book collection.
def create_author_collection():
try:
library_db.create_collection("author")
except Exception as e:
print(e)
author_validator = {
"$jsonSchema": {
"bsonType": "object",
"required": ["first_name", "last_name"],
"properties": {
"first_name": {
"bsonType": "string",
"description": "must be a string and is required"
},
"last_name": {
"bsonType": "string",
"description": "must be a string and is required"
},
"date_of_birth": {
"bsonType": "date",
"description": "must be a date"
}
}
}
}
library_db.command("collMod", "author", validator=author_validator)
create_author_collection()The above code snippet defines a function named create_author_collection that:
● Creates the author collection in the library_db database or raises an exception that you handled.
● Defines a schema validator for the documents in the author collection.
● Set the schema as the validator for the author collection with the collMod command.
When you run the code, it will create theauthor collection in the database cluster. You can verify the creation in your MongoDB Atlas.
Verifying the Validations
You can verify the validations of the collections you created using the following code:
print(f'Book Validation: {library_db.get_collection("book").options()}')
print(f'Author Validation: {library_db.get_collection("author").options()}')Output:
Book Validation: {'validator': {'$jsonSchema': {'bsonType': 'object', \
'required': ['title', 'authors', 'publication_date', 'type', 'copies'], \
'properties': {'title': {'bsonType': 'string', 'description': 'must be a \
string and is required'}, 'authors': {'bsonType': 'array', 'description': \
'must be an array and is required', 'items': {'bsonType': 'objectId', \
'description': 'must be an objectId and is required'}, 'minItems': 1}, \
'publication_date': {'bsonType': 'date', 'description': 'must be a date \
and is required'}, 'type': {'enum': ['hardcover', 'paperback'], \
'description': 'can only be one of the enum values and is required'}, \
'copies': {'bsonType': 'int', 'description': 'must be an integer \
greater than 0 and is required', 'minimum': 0}}}}, 'validationLevel': \
'strict', 'validationAction': 'error'}
Author Validation: {'validator': {'$jsonSchema': {'bsonType': \
'object', 'required': ['first_name', 'last_name'], 'properties': \
{'first_name': {'bsonType': 'string', 'description': 'must be \
a string and is required'}, 'last_name': {'bsonType': 'string', \
'description': 'must be a string and is required'}, 'date_of_birth': \
{'bsonType': 'date', 'description': 'must be a date'}}}}, \
'validationLevel': 'strict', 'validationAction': 'error'}If the validation failed to apply properly or there were no validations, you will see an empty dictionary in the output.
Bulk Insert
To insert data into the book and author collections, first insert the data into the author collection, as the documents in the book collection have a reference to the author collection. Then, insert the data into the book collection.
def insert_bulk_data():
authors = [
{
"first_name": "John",
"last_name": "Doe",
"date_of_birth": datetime(1990, 1, 20)
},
{
"first_name": "Jane",
"last_name": "Doe",
"date_of_birth": datetime(1990, 1, 1)
},
{
"first_name": "Jack",
"last_name": "Smith",
}
]
author_collection = library_db.author
author_ids = author_collection.insert_many(authors).inserted_ids
print(f"Author IDs: {author_ids}")
books = [
{
"title": "MongoDB, The Book for Beginners",
"authors": [author_ids[0], author_ids[1]],
"publication_date": datetime(2022, 12, 17),
"type": "hardcover",
"copies": 10
},
{
"title": "MongoDB, The Book for Advanced Users",
"authors": [author_ids[0], author_ids[2]],
"publication_date": datetime(2023, 1, 2),
"type": "paperback",
"copies": 5
},
{
"title": "MongoDB, The Book for Experts",
"authors": [author_ids[1], author_ids[2]],
"publication_date": datetime(2023, 1, 2),
"type": "paperback",
"copies": 5
},
{
"title": "100 Projects in Python",
"authors": [author_ids[0]],
"publication_date": datetime(2022, 1, 2),
"type": "hardcover",
"copies": 20
},
{
"title": "100 Projects in JavaScript",
"authors": [author_ids[1]],
"publication_date": datetime(2022, 1, 2),
"type": "paperback",
"copies": 15
}
]
book_collection = library_db.book
book_collection.insert_many(books)
print(f"Inserted Book Results: {inserted_book_ids}")
print(f"Inserted Book IDs: {inserted_book_ids.inserted_ids}")
insert_bulk_data()Output:
Author IDs: [ObjectId('63bd78b8d7bbbf34d7a3826a'), \
ObjectId('63bd78b8d7bbbf34d7a3826b'), \
ObjectId('63bd78b8d7bbbf34d7a3826c')]
Inserted Book Results: <pymongo.results.InsertManyResult \
object at 0x0000023DB97F7040>
Inserted Book IDs: [ObjectId('63bd78b9d7bbbf34d7a3826d'), \
ObjectId('63bd78b9d7bbbf34d7a3826e'), \
ObjectId('63bd78b9d7bbbf34d7a3826f'), \
ObjectId('63bd78b9d7bbbf34d7a38270'), ObjectId('63bd78b9d7bbbf34d7a38271')]The above code calls the insert_bulk_data function, which inserts multiple documents into the author and the book collections in the library_db database.
The insert_bulk_data function:
● Defines a list of authors and a list of books. Each element in these lists is a Python dictionary that represents a document in the author and book collections.
● Inserts the authors documents into the author collection using the insert_many method, which inserts multiple documents at once. The inserted_ids attribute of the returned InsertManyResult object is a list of the ObjectId of the inserted documents.
● Inserts the books documents into the book collection using the insert_many method. The authors field in each book document is set to a list of the ObjectIds of the corresponding author documents. This creates a reference between the author and the book collections.
Notice that all the documents follow the defined schema validation.
If you try to insert a document that fails to follow the schema, you’ll get a validation error:
book_collection = library_db.book
book_collection.insert_one({
"title": "MongoDB, The Book"
})In the above code, you didn’t pass the other required fields, and hence, the validation failed.
Output:
pymongo.errors.WriteError: Document failed validation, \
full error: {'index': 0, 'code': 121, 'errInfo': \
{'failingDocumentId': ObjectId('63b3bba1421a1d3a6001b4ad'), \
'details': {'operatorName': '$jsonSchema', 'schemaRulesNotSatisfied': \
[{'operatorName': 'required', 'specifiedAs': {'required': \
['title', 'authors', 'publication_date', 'type', 'copies']}, \
'missingProperties': ['authors', 'copies', 'publication_date', \
'type']}]}}, 'errmsg': 'Document failed validation'}Data Modeling Patterns
In MongoDB, data modeling involves designing the structure of the documents in a collection, including the data types of the fields, the relationships between collections, and the indexes used to improve the performance of queries. Effective data modeling can help you store and retrieve your data efficiently and ensure that your data is organized in a way that makes it easy to use and understand.
In the above database design, we have two collections: the book collection and the author collection, which are used to store information about books and authors, respectively. These two collections have a relationship between them, where one book document can have multiple authors, and one author can have written multiple books.
There are two main data modeling patterns that can be used to model these relationships:
Embedded pattern: In this pattern, you will embed the entire
authordocument or a subset of theauthordocument within thebookdocument. This allows you to retrieve all the information about a book and its authors in a single query, without having to perform multiple queries or join the collections.{ "_id": ObjectId("1234567890"), "title": "MongoDB, The Book for Beginners", "authors": [ { "first_name": "John", "last_name": "Doe", "date_of_birth": datetime.datetime(1990, 1, 20, 0, 0) }, { "first_name": "Jane", "last_name": "Doe", "date_of_birth": datetime.datetime(1990, 1, 1, 0, 0) } ], "publication_date": datetime.datetime(2022, 12, 17, 0, 0), "type": "hardcover", "copies": 10 }However, one of the disadvantages of this pattern is that it can take up more disk space. It can also be difficult to update the information of the authors if this information is embedded in multiple documents.
Reference pattern: In this pattern, instead of embedding the
authorinformation within thebookdocument, you will store a reference to theauthordocument in thebookdocument. This reference is a field in thebookdocument that stores the unique identifier of theauthordocument. This allows you to easily retrieve all the books written by a particular author by querying thebookcollection and using theauthorsfield to filter the results.
{
"_id": ObjectId("1234567890"),
"title": "MongoDB, The Book for Beginners",
"authors": [ObjectId("9876543211"), ObjectId("123454321")],
"publication_date": datetime.datetime(2022, 12, 17, 0, 0),
"type": "hardcover",
"copies": 10
}One of the advantages of this pattern is that it saves disk space. It is also more flexible than the embedded pattern in terms of changes. For example, in the case of an embedded pattern, if an author changes their name, you’ll have to change the author’s name in every document that references the author. However, in the case of reference pattern, you’ll only need to change the author’s name in its original document. It will be automatically reflected in other documents because they are referencing the original author document. One of the disadvantages of this pattern is that you will either need multiple database operations or need to join multiple collections to get all the related data.
Both of these patterns have their own advantages and disadvantages. The pattern to choose depends on your application’s requirements. The key concept you should keep in mind while modeling data is “store together what will be accessed together”.
Learn more about Data Modeling.
Advanced MongoDB Queries
In this section, you will learn to use advanced queries to work with your data in MongoDB.
Using Regular Expressions
MongoDB supports the use of regular expressions to search for specific patterns in string data. To use regular expressions in a MongoDB query with PyMongo, you can use the $regex operator and pass in a regular expression.
For example, searching for all books containing "MongoDB" in their title will look as shown below:
query = {"title": {"$regex": "MongoDB"}}
mongodb_books = library_db.book.find(query)
print(list(mongodb_books))Output:
[{'_id': ObjectId('63bd78b9d7bbbf34d7a3826d'),
'authors': [ObjectId('63bd78b8d7bbbf34d7a3826a'),
ObjectId('63bd78b8d7bbbf34d7a3826b')],
'copies': 10,
'publication_date': datetime.datetime(2022, 12, 17, 0, 0),
'title': 'MongoDB, The Book for Beginners',
'type': 'hardcover'},
{'_id': ObjectId('63bd78b9d7bbbf34d7a3826e'),
'authors': [ObjectId('63bd78b8d7bbbf34d7a3826a'),
ObjectId('63bd78b8d7bbbf34d7a3826c')],
'copies': 5,
'publication_date': datetime.datetime(2023, 1, 2, 0, 0),
'title': 'MongoDB, The Book for Advanced Users',
'type': 'paperback'},
{'_id': ObjectId('63bd78b9d7bbbf34d7a3826f'),
'authors': [ObjectId('63bd78b8d7bbbf34d7a3826b'),
ObjectId('63bd78b8d7bbbf34d7a3826c')],
'copies': 5,
'publication_date': datetime.datetime(2023, 1, 2, 0, 0),
'title': 'MongoDB, The Book for Experts',
'type': 'paperback'}]Using the Join Operator
To perform a join operation in MongoDB, you can use the $lookup pipeline stage. The $lookup pipeline stage performs a left outer join to an un-sharded collection in the same database to filter in documents from the joined collection for processing.
You can get all the authors with their respective documents as shown below:
pipeline = [
{
"$lookup": {
"from": "book",
"localField": "_id",
"foreignField": "authors",
"as": "books"
}
}
]
authors_with_books = library_db.author.aggregate(pipeline)
print(list(authors_with_books))This will perform a left outer join on the author and book collections. The author field in the book collection contains the _id field of the author document. It matches documents in the author collection with those in the book collection based on that authors field. The resulting documents will have a new field called books that contains an array of the books written by that author.
Output:
[{'_id': ObjectId('63bd78b8d7bbbf34d7a3826a'),
'books': [{'_id': ObjectId('63bd78b9d7bbbf34d7a3826d'),
'authors': [ObjectId('63bd78b8d7bbbf34d7a3826a'),
ObjectId('63bd78b8d7bbbf34d7a3826b')],
'copies': 10,
'publication_date': datetime.datetime(2022, 12, 17, 0, 0),
'title': 'MongoDB, The Book for Beginners',
'type': 'hardcover'},
{'_id': ObjectId('63bd78b9d7bbbf34d7a3826e'),
'authors': [ObjectId('63bd78b8d7bbbf34d7a3826a'),
ObjectId('63bd78b8d7bbbf34d7a3826c')],
'copies': 5,
'publication_date': datetime.datetime(2023, 1, 2, 0, 0),
'title': 'MongoDB, The Book for Advanced Users',
'type': 'paperback'},
{'_id': ObjectId('63bd78b9d7bbbf34d7a38270'),
'authors': [ObjectId('63bd78b8d7bbbf34d7a3826a')],
'copies': 20,
'publication_date': datetime.datetime(2022, 1, 2, 0, 0),
'title': '100 Projects in Python',
'type': 'hardcover'}],
'date_of_birth': datetime.datetime(1990, 1, 20, 0, 0),
'first_name': 'John',
'last_name': 'Doe'},
{'_id': ObjectId('63bd78b8d7bbbf34d7a3826b'),
'books': [{'_id': ObjectId('63bd78b9d7bbbf34d7a3826d'),
'authors': [ObjectId('63bd78b8d7bbbf34d7a3826a'),
ObjectId('63bd78b8d7bbbf34d7a3826b')],
'copies': 10,
'publication_date': datetime.datetime(2022, 12, 17, 0, 0),
'title': 'MongoDB, The Book for Beginners',
'type': 'hardcover'},
{'_id': ObjectId('63bd78b9d7bbbf34d7a3826f'),
'authors': [ObjectId('63bd78b8d7bbbf34d7a3826b'),
ObjectId('63bd78b8d7bbbf34d7a3826c')],
'copies': 5,
'publication_date': datetime.datetime(2023, 1, 2, 0, 0),
'title': 'MongoDB, The Book for Experts',
'type': 'paperback'},
{'_id': ObjectId('63bd78b9d7bbbf34d7a38271'),
'authors': [ObjectId('63bd78b8d7bbbf34d7a3826b')],
'copies': 15,
'publication_date': datetime.datetime(2022, 1, 2, 0, 0),
'title': '100 Projects in JavaScript',
'type': 'paperback'}],
'date_of_birth': datetime.datetime(1990, 1, 1, 0, 0),
'first_name': 'Jane',
'last_name': 'Doe'},
{'_id': ObjectId('63bd78b8d7bbbf34d7a3826c'),
'books': [{'_id': ObjectId('63bd78b9d7bbbf34d7a3826e'),
'authors': [ObjectId('63bd78b8d7bbbf34d7a3826a'),
ObjectId('63bd78b8d7bbbf34d7a3826c')],
'copies': 5,
'publication_date': datetime.datetime(2023, 1, 2, 0, 0),
'title': 'MongoDB, The Book for Advanced Users',
'type': 'paperback'},
{'_id': ObjectId('63bd78b9d7bbbf34d7a3826f'),
'authors': [ObjectId('63bd78b8d7bbbf34d7a3826b'),
ObjectId('63bd78b8d7bbbf34d7a3826c')],
'copies': 5,
'publication_date': datetime.datetime(2023, 1, 2, 0, 0),
'title': 'MongoDB, The Book for Experts',
'type': 'paperback'}],
'first_name': 'Jack',
'last_name': 'Smith'}]You can get all the authors with the number of books they have written.
The $addFields operator is used to add a new field named total_books to each document in the pipeline, the total_books field is the size of the books array.
The $project operator in MongoDB is used to reshape the documents in a collection by specifying a set of fields to include or exclude in the results.
pipeline = [
{
"$lookup": {
"from": "book",
"localField": "_id",
"foreignField": "authors",
"as": "books"
}
},
{
"$addFields": {
"total_books": {"$size": "$books"}
}
},
{
"$project": {"_id": 0, "first_name": 1, \
"last_name": 1, "total_books": 1}
}
]
authors_with_books = library_db.author.aggregate(pipeline)
print(list(authors_with_books))Output:
[{'first_name': 'John', 'last_name': 'Doe', 'total_books': 3},
{'first_name': 'Jane', 'last_name': 'Doe', 'total_books': 3},
{'first_name': 'Jack', 'last_name': 'Smith', 'total_books': 2}]The $project operator is used to select only the fields first_name, last_name, and total_books from each document in the pipeline, and exclude the _id field.
You can get the authors with more than 2 books as shown below:
To get authors with more than 2 books, you can add a match stage to the pipeline. The $match operator filters the documents to pass only the documents that match the specified condition(s) to the next pipeline stage:
pipeline = [
{
"$lookup": {
"from": "book",
"localField": "_id",
"foreignField": "authors",
"as": "books"
}
},
{
"$addFields": {
"total_books": {"$size": "$books"}
}
},
{
"$match": {"total_books": {"$gt": 2}}
},
{
"$project": {"_id": 0, "first_name": 1, \
"last_name": 1, "total_books": 1}
}
]This will filter out all authors that have less than 3 books.
Output:
[{'first_name': 'John', 'last_name': 'Doe', 'total_books': 3},
{'first_name': 'Jane', 'last_name': 'Doe', 'total_books': 3}]Using Map Operator
The $map operator is an array operator in MongoDB that applies an expression to each element in an array and returns an array with the applied results.
You can calculate how many days ago a book was written in the following way:
pipeline = [
{
"$lookup": {
"from": "book",
"localField": "_id",
"foreignField": "authors",
"as": "books"
}
},
{
"$addFields": {
"books": {
"$map": {
"input": "$books",
"as": "book",
"in": {
"title": "$$book.title",
"age_in_days": {
"$dateDiff": {
"startDate": "$$book.publication_date",
"endDate": "$$NOW",
"unit": "day"
}
}
}
}
}
}
}
]
# Execute the pipeline
authors_with_book_ages = library_db.author.aggregate(pipeline)
print(list(authors_with_book_ages))Output:
[{'_id': ObjectId('63bd78b8d7bbbf34d7a3826a'),
'books': [{'age_in_days': 24, 'title': 'MongoDB, The Book for Beginners'},
{'age_in_days': 8, 'title': 'MongoDB, \
The Book for Advanced Users'},
{'age_in_days': 373, 'title': '100 Projects in Python'}],
'date_of_birth': datetime.datetime(1990, 1, 20, 0, 0),
'first_name': 'John',
'last_name': 'Doe'},
{'_id': ObjectId('63bd78b8d7bbbf34d7a3826b'),
'books': [{'age_in_days': 24, 'title': 'MongoDB, The Book for Beginners'},
{'age_in_days': 8, 'title': 'MongoDB, The Book for Experts'},
{'age_in_days': 373, 'title': '100 Projects in JavaScript'}],
'date_of_birth': datetime.datetime(1990, 1, 1, 0, 0),
'first_name': 'Jane',
'last_name': 'Doe'},
{'_id': ObjectId('63bd78b8d7bbbf34d7a3826c'),
'books': [{'age_in_days': 8, 'title': 'MongoDB, \
The Book for Advanced Users'},
{'age_in_days': 8, 'title': 'MongoDB, The Book for Experts'}],
'first_name': 'Jack',
'last_name': 'Smith'}]In the code above:
- The
$lookupoperator performs a left outer join on the book collection and the author collection based on theauthorsarray in the book collection and the_idfield in the author collection. - The
$addFieldsoperator adds a new field calledbooksto each document in the author collection. Thebooksfield is an array of books written by that author. - The
$mapoperator iterates through each element in thebooksarray and creates a new object for each book. The object that it creates includes the title of the book and the age of the book in days. - The
$dateDiffoperator calculates the difference between the publication date of the book and the current date. - The pipeline is executed using the
aggregate()method and the result is printed to the console.
Learn more about MongoDB operators.
Conclusion
This tutorial equipped you with key MongoDB collection concepts, including schema validation for structured, consistent data storage. You’ve also mastered bulk data insertion techniques, data modeling patterns for relationships, and advanced query operations. These skills will enable you to proficiently use MongoDB to develop robust and efficient applications.
As you continue to optimize your development process, consider taking it a step further – optimize your builds with Earthly. If you enjoyed optimizing MongoDB, you’ll appreciate the efficiency and consistency Earthly brings to your build process. Check it out!
Earthly makes CI/CD super simple
Fast, repeatable CI/CD with an instantly familiar syntax – like Dockerfile and Makefile had a baby.








