
PostgreSQL in Python Using Psycopg2

We’re Earthly. We make building software simpler and faster using containerization. If you’re dealing with Python, Earthly can help simplify the build and test process. Check it out.
Are you a Python programmer learning to work with PostgreSQL? If so, this tutorial on psycopg2, the PostgreSQL connector for Python, is for you. You can connect to PostgreSQL databases and run queries—all from within your Python script—using the psycopg2 adapter.
In this tutorial, you’ll learn the basics of using psycopg2 in Python to do the following:
- Connect to a PostgreSQL database
- Run SQL queries against a database: create tables, insert, retrieve, and delete records
- Use context managers in Python to run queries
Let’s get started!
Prerequisites
To follow along with this tutorial, you need to have the following installed in your development environment:
- PostgreSQL and Python 3.6 or a later version
- Psycopg2, the Postgres connector for Python. It’s available as a PyPI package that you can install using pip:
pip3 install psycopg2📝 In this tutorial, we’ll run SQL queries to perform simple CRUD operations on a PostgreSQL database. So familiarity with SQL will be helpful but not required.
How to Connect to a PostgreSQL Database

Before You Begin
- Ensure that your PostgreSQL database server is up and running, and
- You have a database that you can connect to.
You can create a database on pgAdmin or use the command-line client psql. If you use psql at the command line, check if you have the right permissions, and run CREATE DATABASE <sample-db>;. You can optionally specify the username, host, and port; else, <sample-db> is created with the default values for these fields.
The connect() Function in Psycopg2
After you’ve installed the psycopg2 library, you can import it into your working environment. As a first step, let’s create a main.py file, import psycopg2, and connect to a PostgreSQL database.
To connect to a database, you can use the connect() function from psycopg2. The connect() function takes in the information needed to connect to the database, such as the name of the database, username, and password, as keyword arguments. It returns a connection object if the connection succeeds. You can use the connect() function as shown:
# psycopg2-tutorial/main.py
import psycopg2
db_connection = psycopg2.connect(dbname='test',
user=<username>,
password=<password>,
host='localhost',
port=5432)
print("Successfully connected to the database.")In the above code snippet:
dbnameis the name of the database that you’d like to connect to. Here, I’ve connected to thetestdatabase.userandpasswordare the username and the password required for authentication.hostis the IP address of the server on which your database is running (‘localhost’ in this case).portrefers to the port number that the server listens to for incoming connection requests to the database. The default value is 5432.
📑 Specifying the details of the database in the function call, as shown above, is a good example of how not to connect to a database.
In practice, you should store the details of the database and the credentials required to connect to it in a config file. You can then parse the config file, retrieve the required details, and use them in the call to the connect() function.
But why is this helpful? When working on a project, you may need to connect to multiple databases or connect to a database from more than one module. In such cases, if the database credentials change, you can only modify the contents of the config file without introducing breaking changes elsewhere.
Also, exposing sensitive info like passwords in source code is a security risk. So you should always store the credentials in a config file or set them as environment variables whose values you can fetch as needed.
How to Parse Config Files in Python
The configparser module, built into the Python standard library, lets you parse configuration files of the INI file format.
If TOML is your preferred config file format, you can use the built-in tomllib for parsing. To use tomllib you need to have Python 3.11 installed.
A typical config file consists of multiple sections, with each section having a set of key-value pairs. The keys and values are separated by a : or =. Here’s the general structure of a config file with one section and n key-value pairs:
[section-name]
key1=value1
key2=value2
.
.
.
keyn=valuenLet’s create the config file db_info.ini that stores the details required to connect to the PostgreSQL database. The names of the keyword arguments, dbname, user, password, host, and port, should be the keys. And the values used for these arguments in the connect() function call should be the values in the config file:
# psycopg2-tutorial/db_info.ini
[postgres-sample-db]
dbname=test
user=<username>
password=<password>
host=localhost
port=5432Parsing the Config File with ConfigParser
We’ll define helper functions in separate modules and import them inside the main.py file as needed. This will ensure that main.py contains only the code relevant to psycopg2.
Let’s create db_config.py containing the definition of get_db_info(), a function that parses the config file and returns the info we need to connect to the database.
# psycopg2-tutorial/db_config.py
from configparser import ConfigParser
def get_db_info(filename,section):
# instantiating the parser object
parser=ConfigParser()
parser.read(filename)
db_info={}
if parser.has_section(section):
# items() method returns (key,value) tuples
key_val_tuple = parser.items(section)
for item in key_val_tuple:
db_info[item[0]]=item[1] # index 0: key & index 1: value
return db_infoThe function get_db_info() takes in the names of the config file and the section as arguments. It returns the details of the database as a Python dictionary. Under the hood, it works by instantiating a ConfigParser object that reads in the config file, taps into the section, and retrieves the key-value pairs.
Now we do the following inside main.py:
- Import the
get_db_info()function fromdb_config, - Call the
get_db_info()function with the correct arguments and store the returned dictionary indb_info, and - Use
db_infoin the call to theconnect()function.
# psycopg2-tutorial/main.py
import psycopg2
from db_config import get_db_info
filename='db_info.ini'
section='postgres-sample-db'
db_info = get_db_info(filename,section)
db_connection = psycopg2.connect(**db_info)
print("Successfully connected to the database.")Handling Connection Errors
Let’s recall what we’ve done so far. We stored the details of the database in a config file, parsed it using ConfigParser, and connected to the database using the connect() function from psycopg2. However, we haven’t accounted for the errors that may arise during the connection process.

Suppose you enter an incorrect password (yeah, that happens often!). Open the config file db_info.ini, update the password to something invalid, and run the script again.
There’ll be a runtime error. Focusing on the relevant information in the traceback, you’ll see that an OperationalError exception is thrown as password authentication failed. Psycopg2 has an implementation of the OperationalError class.
Traceback (most recent call last):
...
psycopg2.OperationalError: connection to server at "localhost" (::1), \
port 5432 failed: FATAL: password authentication failed for user "postgres"What happens when you try connecting to a database that does not exist? For example, I updated the dbname field in the config file from test to test1 (the test1 database does not exist). It’s an OperationalError exception (again).
Traceback (most recent call last):
...
psycopg2.OperationalError: connection to server at "localhost" (::1), \
port 5432 failed: FATAL: database "test1" does not existYou can run the script a few more times by changing one or more fields to invalid values. And you’ll see that an OperationalError exception is thrown in all of the runs.
Therefore, such connection errors that arise due to incorrect or invalid values can all be subsumed under the OperationalError exception.
Exception Handling Using try and except
Now, let’s import the OperationalError class from psycopg2 and handle the OperationalError exception using Python’s try and except blocks.
# psycopg2-tutorial/main.py
import psycopg2
from psycopg2 import OperationalError
from db_config import get_db_info
filename='db_info.ini'
section='postgres-sample-db'
db_info = get_db_info(filename,section)
try:
db_connection = psycopg2.connect(**db_info)
print("Successfully connected to the database.")
except OperationalError:
print("Error connecting to the database :/")Let’s parse what the above code snippet does.
- If the
tryblock succeeds, theconnect()function returns a database connection instance,db_connection. - If an
OperationalErrorexception is raised during the connection process, theexceptblock is triggered, and we get notified that there was an error connecting to the database.
In essence: we try to connect to the database and run queries when there are no OperationalError exceptions.
A Note on Closing the Connection 🤨
We haven’t queried the database yet, so why close the connection? We’ll discuss this to get a high-level overview of what we’re trying to accomplish. Also, it’s easier to think coherently about the try, except, and finally blocks here.
We know how to connect to a database and handle connection errors. After connecting to the database and querying it, we should finally close the connection by calling the close() method on the connection object.
You can do this inside a finally block. The statements inside the finally block are always executed, regardless of whether or not the try block succeeds. So you may come up with the following:
from psycopg2 import OperationalError
try:
# connecting to the db
# querying the db
except OperationalError:
# print out the error message
finally:
# close the db connectionThis is almost correct, but there’s a small problem. To close a connection, it should exist. If the connection fails, then the connection object is never returned. So you’ll run into a NameError exception trying to close a connection that does not even exist.
To account for this, let’s set db_connection to None initially and close the connection only if it exists: if db_connection: is equivalent to if db_connection is not None:.
Putting it all together, here’s our main.py file:
# psycopg2-tutorial/main.py
import psycopg2
from psycopg2 import OperationalError
from db_config import get_db_info
filename='db_info.ini'
section='postgres-sample-db'
db_info = get_db_info(filename,section)
db_connection = None
try:
db_connection = psycopg2.connect(**db_info)
print("Successfully connected to the database.")
except OperationalError:
print("Error connecting to the database :/")
finally:
if db_connection:
db_connection.close()
print("Closed connection.")How To Query the Database
So far, we’ve learned to connect to the database and handle connection errors. Can we start querying the database yet?
The Cursor Object
There’s one more step before you can start running queries: creating a database cursor.
Cursors are analogous to file handlers. They let you query databases and fetch results just the way file handlers let you perform I/O operations on files. Once you have a cursor object, you can call methods on it to query the database and fetch the results of the query.
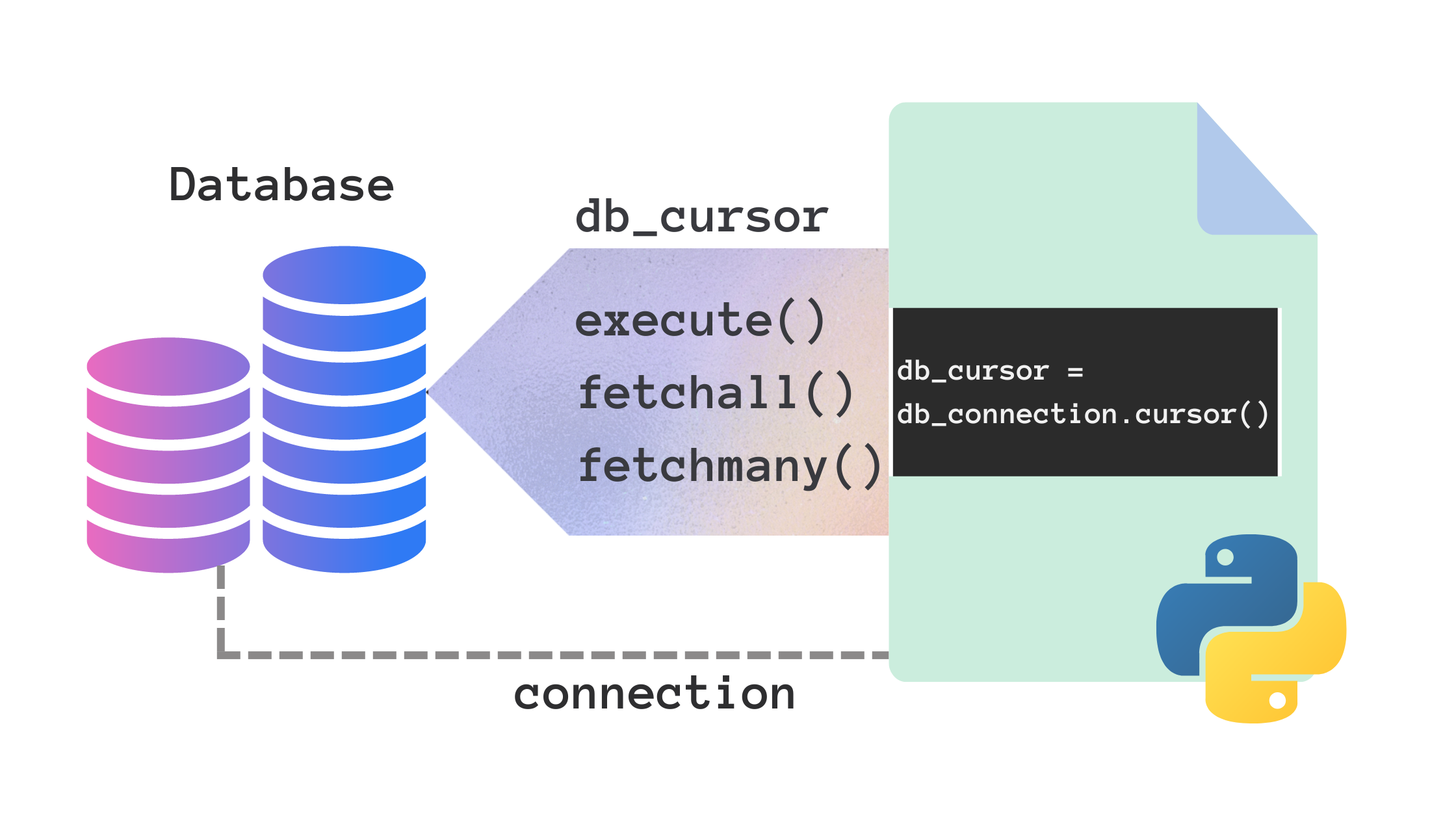
To create a cursor object, you can call the cursor() method on the connection object.
db_cursor = db_connection.cursor()⚠️ For clarity, I’ll present the SQL queries and the results as short snippets. But remember, everything we’re trying to run is inside the try block.
In the test database, let’s create a table, people. Each record in the table has the fields: name, city, and profession. The SQL query is defined in the string, create_table.
To execute the query, call the execute() method on the cursor object, db_cursor, and pass in the query string, create_table.
create_table = '''CREATE TABLE people(
id SERIAL PRIMARY KEY,
name varchar(50) NOT NULL,
city varchar(40),
profession varchar(60));'''
db_cursor.execute(create_table)After creating the table, let’s insert a record: Jane Lee who works as a Rust programmer in the fictional city of Rustmore.
insert_record = "INSERT INTO people (name,city,profession) \
VALUES (%s, %s, %s);"
insert_value = ('Jane Lee','Rustmore','Rust programmer')
db_cursor.execute(insert_record, insert_value)Specifying placeholders in the query string and passing in the values as a tuple helps mitigate SQL injection attacks.
Committing Transactions
Now run main.py. The script will run without errors. However, if you look up the database, you’ll not be able to find the people table with Jane Lee’s record. Why? Well, for the changes to persist in the database, you’ll have to commit the transaction.
To do so you can either call the commit() method on the connection object or set the autocommit attribute of the connection object to True.
db_connection.autocommit = TrueRe-run main.py.The changes we’ve made will now persist in the test database.
Inserting Records Into a Table
In the test database, we now have a table named people containing only one record - not very interesting. We need to insert more records into the table. I can spend the rest of the day coming up with names and fictional cities. Or I can generate synthetic data using Faker. You can install Faker using pip: pip install Faker.
The fake_data.py file contains the generate_fake_data() function that’ll return a list of (name, city, job) tuples. After instantiating a Faker object, I’ve set the seed for reproducibility. Without the seed, you’ll get a different set of records every time you run the script.
# psycopg2-tutorial/fake_data.py
from faker import Faker
fake = Faker()
Faker.seed(42)
def generate_fake_data(num):
records = []
for i in range(num):
name, city, job = fake.name(), fake.city(), fake.job()
records.append((name,city,job))
return recordsInside the main.py file, import generate_fake_data from the fake_data module. Let’s use the generate_fake_data() function to generate 100 more records that we can insert into the people table.
Here, records is a tuple of records. We can loop through it and insert the records into the table by calling the execute() method on db_cursor.
from fake_data import generate_fake_data
records = tuple(generate_fake_data(100)) #cast into a tuple for immutability
insert_record = "INSERT INTO people (name,city,profession)\
VALUES (%s, %s, %s);"
for record in records:
db_cursor.execute(insert_record,record)Instead of looping through the records tuple and using the execute() method for inserting each record, you can call executemany() on the cursor object. Using db_cursor.executemany(insert_record, records) yields the same results and is not faster than looping.
How to Retrieve Data from Tables
Next, let’s read data from the people table. We’ll run a simple select query to read all the records from the table.
Executing the select query, SELECT * FROM people; returns all the records in the table. To fetch the results of the query, you can call a few fetch methods on the cursor object. These methods return records from the result as tuples:
Fetch the Next Record with fetchone()
Calling the fetchone() method on db_cursor fetches the next record in the result.
db_cursor.execute("SELECT * FROM people;")
print(db_cursor.fetchone())As this is the first time we’re fetching the record, it fetches the first record.
(1, 'Jane Lee', 'Rustmore', 'Rust programmer')Fetch the Next n Records with fetchmany()
The fetchmany() method takes in the number of records to fetch (n) and fetches the next n records from the result.
for record in db_cursor.fetchmany(10):
print(record)As we’ve mentioned 10 in the fetchmany() method call, we get the next 10 records: records in rows 2 to 11 in the people table.
(2, 'Allison Hill', 'East Jill', 'Sports administrator')
(3, 'Javier Johnson', 'East William', 'Aid worker')
(4, 'Michelle Miles', 'Robinsonshire', 'Health physicist')
(5, 'Abigail Shaffer', 'Petersonberg', 'Engineer, structural')
(6, 'Gabrielle Davis', 'West Melanieview', 'Armed forces logistics/ \
support/administrative officer')
(7, 'Kimberly Dudley', 'Millerport', 'Water engineer')
(8, 'Heidi Lee', 'North Donnaport', 'Cartographer')
(9, 'Sharon James', 'Reidstad', 'Designer, textile')
(10, 'Daniel Adams', 'New Cynthiaside', 'Financial risk analyst')
(11, 'James Mayo', 'Lake Mark', 'Banker')Fetch All the Remaining Rows with fetchall()
Calling the fetchall() method on the cursor object returns all the remaining records in the result.
for record in db_cursor.fetchall():
print(record)We’ve already fetched the first 11 records in the result. So fetchall() fetches all the remaining records.
# output (truncated)
(12, 'Andrew Stewart', 'Carlshire', 'International aid/development worker')
(13, 'Jonathan Wilkerson', 'Thomasberg', 'Fine artist')
(14, 'Kimberly Burgess', 'Hurstfurt', 'Medical illustrator')
.
.
.
(98, 'David Grant', 'Obrienbury', 'Scientist, research (medical)')
(99, 'Terry Evans', 'Torreston', 'Travel agency manager')
(100, 'Annette Farmer', 'West Donna', 'Designer, graphic')
(101, 'Juan Moore', 'Hayesfort', 'Horticulturist, amenity')Updating and Deleting Records

From the cities in the table, I’d like to get the list of all cities that occur more than once.
get_count ='''SELECT city, COUNT(*)
FROM people
GROUP BY city HAVING COUNT(*)>1;'''
db_cursor.execute(get_count)
print(db_cursor.fetchall())We see that ‘Johnsonmouth’ is the only city that appears more than once.
# Output
[('Johnsonmouth', 2)]
Let’s update both the occurrences of ‘Johnsonmouth’ to another fictional city, say, ‘Mathville’.
update_query = "UPDATE people SET city=%s WHERE city=%s"
values = ('Mathville','Johnsonmouth')
db_cursor.execute(update_query,values)Now let’s delete the records where the city is ‘Mathville’.
delete_record = "DELETE FROM people WHERE city=%s;"
record = ('Mathville',) # pass in as a tuple
db_cursor.execute(delete_record,record)With that, we’ve run a basic set of queries to insert, retrieve, update, and delete records. So what do we do next? We’ve already accounted for closing the database connection (finally) after running the queries.
It’s a good practice to also close the database cursor. To do this, you can call the close() method on the cursor object. But this has to be inside the finally block too, before closing the database connection. This is because if the connection object does not exist, the cursor doesn’t exist either!
If needed, look up the main.py file to make sure you’ve understood it all.
Simplifying Querying Using Context Managers
So far we’ve implemented exception handling for errors that arise when trying to connect to a database. We then ran SQL queries to create a table and insert records, retrieve data from the table, and update and delete records. In all of the above, the queries ran without errors and returned the desired results. ✅
In practice, however, some queries may not run as expected! We may run into errors: from syntax errors in the query string to errors arising from attempting invalid transactions.
For example: retrieving, updating, and deleting records make sense only when there is a table with records. Psycopg2 provides several exception classes such as DatabaseError and ProgrammingError that are triggered when the SQL queries fail to run successfully.
In summary: you’re not only trying to connect to the database and run a set of queries. Rather, for each of the queries, you try to run the query (inside a try block) and catch any exception (inside the except block).
Suppose you need to run n queries. If you implement error handling for each of the n queries, your script will look like this:
# all imports
from psycopg2 import OperationalError
try:
# connecting to the db
try:
# running query #1
except <ErrorType1>:
# roll back changes
try:
# running query #2
except <ErrorType2>:
# roll back changes
...
except OperationalError:
# print out the error message
finally:
# close the db connectionImplementing such error handling for each of the n queries can be difficult. And here’s where context managers can help.
Connection and Cursor Objects as Context Managers
In Python, context managers can be used to control the execution of a block of statements and the with statement can be used to create an execution context.
In general, context managers mitigate resource leakage and help in efficient resource handling. They do this by setting up and tearing down resources when the execution enters and exits the context, respectively.
The connection and cursor objects we’ve used so far are both context managers. You can use them in with statements using the following general syntax:
# psycopg2-tutorial/main2.py
try:
with psycopg2.connect(**db_info) as db_connection:
print("Successfully connected to the database.")
with db_connection.cursor() as db_cursor:
# run queries
except OperationalError:
# print out the error message
finally:
# close the db connectionIn the above snippet:
- The outer
withstatement wraps a block that executes with the database connection instance as the context manager. - The inner
withstatement wraps a set of queries that run with the database cursor as the context manager.
But how does this help?
When you use the connection object as a context manager:
- All successful transactions are automatically committed when the execution exits the outer
withblock. Note that the outerwithblock also wraps the creation of the cursor context manager to run the queries. So the set of queries represents a single transaction. If you need to run several hundred queries, you can create multiple connection context managers, each wrapping a database transaction. - If there are exceptions due to one or more failing queries, changes are rolled back. Without the context manager, you’ll have to call the
rollback()method on the connection object to do this. - When the cursor object exits a
withblock, it is automatically closed. So you don’t have to close the cursor.
The finally block is still there because the connection is not automatically closed when the execution exits the block. So you still have to close the connection.
The version of the code using context managers can be found in the main2.py file.
Working with Psycopg2: A Quick Review

Let’s review all that we’ve learned in this tutorial:
- To connect to databases, psycopg2 provides the
connect()convenience function. Theconnect()function takes in the details of the database—as keyword arguments—and returns a connection object if there are no errors. - You can create a database cursor by calling the
cursor()method on the connection object. - To run database queries, call the
execute()method on the cursor object. Specify the SQL query as a string, use placeholders for values, and pass in the values as tuples. To run multiple queries, you can useexecutemany(), but there are no known performance improvements. - Fetch the results of the query by calling one of the fetch methods:
fetchone(),fetchmany(), orfetchall()on the connection object. - You can call the
commit()androllback()methods on the connection object to commit transactions to the database and roll back changes if there’s an error, respectively. - When you run queries using the database connection as a context manager, successful transactions are automatically committed to the database. And changes are rolled back in the event of errors.
Conclusion
In this tutorial, you’ve learned the basics of querying PostgreSQL databases using psycopg2, including connection establishment, running queries, and exception handling. Now, you can expand your knowledge by adding more tables to your database, defining table relationships, and querying data from multiple tables.
And as you continue to build and expand your Python applications, you might encounter the need for consistent builds across different environments. For this, don’t forget to check out Earthly, a tool designed to ensure reproducibility and efficiency in your build process.
Earthly makes CI/CD super simple
Fast, repeatable CI/CD with an instantly familiar syntax – like Dockerfile and Makefile had a baby.







