
Linux Text Processing Command

We’re Earthly. We make building software simpler and therefore faster using containerization. Earthly might help streamline your text processing pipeline and make your projects easier to manage. Check it out.
Text processing in Linux involves manipulating text data to extract meaningful information or to transform it into a desired output. This is particularly useful because in Linux, everything is treated as a file, including text data. By mastering Linux text processing commands, you can complete tasks more efficiently, saving time and effort in your daily workflow.
These commands are especially useful in several scenarios, such as when working with log files during debugging, in CI/CD pipelines, or when handling large amounts of data.
This tutorial aims to introduce you to the concept of Linux text processing, highlight its benefits, and provide an overview of the commonly used text processing commands. You will also learn about their use cases and how they can help automate tedious tasks, making them more manageable in a matter of seconds.
A Brief Overview Of STDIN, STDOUT & STDERR

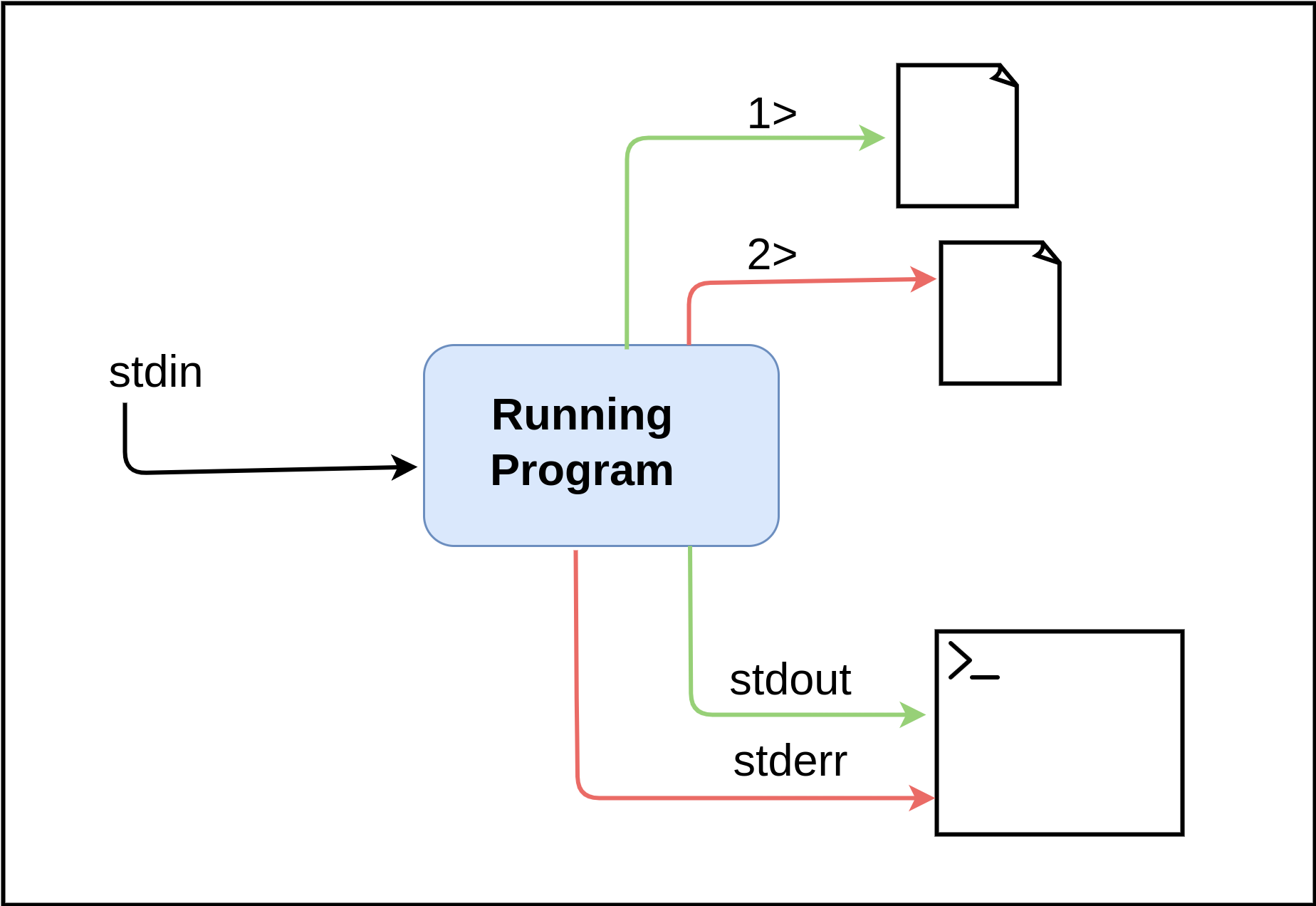
Standard input (stdin), standard output (stdout), and standard error (stderr) are the three standard streams that allow users to interact with commands and scripts in Linux. Understanding how to use these streams is crucial for efficiently working with Linux commands and scripts. Without a clear understanding of stdin, stdout, and stderr, it can be challenging to effectively manage command output.
This section introduces you to the different standard streams in Unix world. You will be able to visualize how text streams are connected to one another.
Stdin - short for Standard input, It’s the way you give input to a program. For example:
grep something file.txtThe command above reads the content of the file, search for a pattern, then prints the result of the search in your shell. In this case, the content of file.txt is stdin.
Stdout - Short for Standard output, It’s an output stream that a program writes its output data. It can be the terminal or a file on the system (if you’ve enough privileges).
Stderr - Short for Standard error, It’s an output stream that the program writes error to. Similar to standard output, you can redirect the output error message to a file using 2> operator.
Here’s a small diagram describing the above concepts:
Pipes & Redirection
Pipes and redirections are used when you want to combine two or more commands together. For example, the first command can write a stream of output to a file, and the second command can operate on that file.
Pipes
In Unix systems, pipe is used to make a connection between two commands. With pipe, the output of one command acts as the input to the other command:
$ echo "Hello World" | tr [a-z] [A-Z] Output:
HELLO WORLDIn the above command we have taken the output of the first command and then passed it through the tr command which capitalized all the letters.
Let’s take another example of installing docker on our system with the easy endpoint that Docker provide:
curl -L https://get.docker.com | sh The first command will give you the script that will be passed to the sh command that will install docker on your system.
Redirection
Most commonly, when we interact with Unix-like systems, the keyboard is the standard input and the terminal is the standard output. However, the file can also be the standard input or output. We can read from a file and use it as the input for a command. Similarly, We can also write the output of a command to a file. This is called redirection.
The following operators are used for redirection operations:
The > operator is used to redirect the output of a command to a file:
curl -L https://GitHub.com/earthly/earthly/raw/main/README.md > README.mdThe above command read the content of the README.md file of the earthly repository and write its content to a README.md file on your local system.
The >> operator is used to append the output of a command to the end of an existing file or write to a new file.
For example, If you’ve a file already in your local system and you want to add new content to the end of file then you can use the >> operator:
$ cat numbers.txt
one
twoSay, you want to append “three” to this file. You can use the >> operator in this case:
echo "three" >> numbers.txtIf you use only the > then it will replace the content of the file with “three”.
The < operator is used to read from a file and then act on it. For example:
wc -l < numbers.txt > lines.txtThe above command takes the input of the wc line count command from the numbers.txt file and redirects the line count to a file called lines.txt
The 2> operator is used to redirect error messages to a particular file. This is useful when you’re executing a command or a script on your system and want to capture the error if something goes wrong:
$ kubectl apply -f namespace.yaml 2> error.txtOutput:
F0209 19:27:54.306725 84448 cred.go:123] print credential \
failed with error: Failed to retrieve access token:: failure \
while executing gcloud, with args [config config-helper --format=json]: \
exit status 1
Unable to connect to the server: getting credentials: \
exec: executable gke-gcloud-auth-plugin failed with exit code 1This will save your error message in the error.txt file. If you use the > operator, you will not get anything in error.txt file.
Similar to the >> operator we discussed earlier, the 2>> operator is used for appending error messages.
Regular Expressions
At its most fundamental level, regular expressions (regex) are used to search for a pattern in a file or directory. It employs wildcards, such as * and +, to perform different types of text-based searches. Regex are especially important because often, you may not remember the exact keyword or phrase that you want to search. In such cases, you can use regex and recall a portion of the content to search and locate the desired information.
Modern shells such as bash, zsh, and fish support regular expressions, making regular expressions a valuable tool for manipulating and searching text data.
Suppose, you have a directory which contains some Go programming language files as well as some markdown files, and you want to filter the files by the type so that you can perform an operation on files of the same type. You can make use of regex patterns in this case.
For example, you can select and run a Go command like go fmt on all the Go files in the current directory, as shown below:
ls *.go | go fmtThe above regex pattern *.go means all the files that end with .go. The command will list all the files that end with .go and run the go fmt command on them.
Similar to the above command, you can do a lot of regexes based searching when operating with files.
Below are some other examples of using regex with other commands.
Say you want to search for a pattern, let’s say all the words that contain either k8s or kubernetes in a file called blog.md:
$ grep k*s blog.mdThe k*s uses the wild card character (*) which means that any character(s) can appear between the “k” and “s” in the searched string.
Thus, the command will return all the lines in the “blog.md” file that contain words with “k” and “s” as the first and last characters, respectively, with any number of characters in between. This includes words like “k8s”, “kubernetes”.
However, the pattern k*s is not an exact match for “k8s” or “kubernetes”. It will also match words like “kafka-streams”, “keyspaces”.
Another example of using regex pattern is when you want to find all the examples in a blog post. For this purpose, you can invoke the following command:
$ grep ^example blog.mdThis will search for all the word that starts with example in the document.
Basic Linux Text Processing Commands

The following include some of the common text processing commands in Linux.
The cut Command
The cut command is used to cut out sections from each line of files and write the result to standard output. You can use it to extract a specific column from a file and print the column to the standard output.
For example, you can use the cut command alongside the gh utility —which is the command line tool for interacting with GitHub— to list the gist id of your GitHub gist. You can install the GitHub command line tool by following the GitHub CLI installation guide.
You can get all the gist that you’ve created so far in your GitHub account by executing the following command:
$ gh gist listOutput:
8d1526fc09b5fc671994dbc0d4c7f8d7 alacritty.yml \
1 file secret about 3 hours ago
5f15a60452277a5c7deb0c6b15a5a3f2 init.lua \
1 file secret about 1 day ago
508bcea1782e7aed3b03f30fe053823a after.txt \
1 file secret less than a minute agoThe output above is divided into 5 columns and three rows. The first alphanumeric long string is the ID of the gist followed by name of the file, number of files a gist contains, the visibility and the time at which it was created.
You can use the following command to list only the IDs of the gist:
$ gh gist list | cut -f 1Output:
8d1526fc09b5fc671994dbc0d4c7f8d7
5f15a60452277a5c7deb0c6b15a5a3f2
508bcea1782e7aed3b03f30fe053823aIn the command above, the gh gist list lists your gists and the cut -f 1 extracts the first field (i.e., the ID) from each line of the output. The fields are separated by whitespace.
The -f option is used to specify which fields to extract, and 1 specifies the first field.
You can also use the cut command to get a specific column from a CSV file. For example, if you have a CSV file that has the following content.
$ cat demo.csvOutput:
name,age,language,hobby
john,21,golang,painting
jane,22,python,singing
jack,25,java,reading
jill,23,python,cooking
option with tee command to append the output.
You can get the name field with the following command:
$ cut -d ',' -f 1 demo.csvOutput:
name
john
jane
jack
jillThe -d option stands for delimiter, and here the delimiter is a comma.
The cutcommand also supports selection of a range of fields. You can select from the second to the fourth field as shown below:
$ cut -d ',' -f 2-3 demo.csvOutput:
age,language,hobby
21,golang,painting
22,python,singing
25,java,reading
23,python,cookingPlease note that ranges are inclusive in the above case and indexing starts with 1.
The sortCommand
The sort command is used to arrange lines in a text files in a specific order. By default, the sort command sorts the content of a file in ascending order.
For example, if you have a file that has the following content:
$ cat names.txtOutput:
peter
ben
johnYou can sort the content of this file by executing the following command:
$ sort names.txtOutput:
ben
john
peterYou can sort the content in descending order with the -r flag as shown below:
$ sort -r names.txtOutput:
peter
john
benThere are other useful flags that you can use with the sort command. Some of the common flags include -f to ignore-case and the -o flag to write the output to a particular file.
The tac Command
The tac command prints the content of your file in the reverse order. If you’re familiar with the cat command, the tac command just returns the reverse of the output of the cat command.
For example, if you have a numbers.txt file with the following content:
$ cat numbers.txtOutput:
one
two
three
four
fiveWhen you execute tac numbers.txt, it reverses the order of the content of the file as shown below:
$ tac numbers.txtOutput:
five
four
three
two
oneA common use case of the tac command is in reading the content of log files. For example, here is the content of the log of a kube-apiserver pod using the tac command:
tac 0.log Output:
2023-01-19T23:05:26.344576202-05:00 stderr F I0120 \
04:05:26.344479 1 controller.go:615] quota admission \
added evaluator for: replicasets.apps
2023-01-19T23:05:26.344256311-05:00 stderr F I0120 \
04:05:26.344122 1 controller.go:615] quota admission \
added evaluator for: controllerrevisions.apps
2023-01-19T23:05:14.15522692-05:00 stderr F I0120 \
04:05:14.155028 1 controller.go:615] quota admission \
added evaluator for: daemonsets.appsThe tac command reverses the content of the log file. This shows the latest logs first.
The uniq Command
The uniq command is used to report or omit repeated lines. This command only print unique lines.
Suppose you have a file that has the following content with repeated lines:
$ cat names.txtOutput:
john
jane
john
jane
johnYou can filter out the repeated line by using the uniq command:
$ uniq names.txtOutput:
john
jane
john
jane
johnThe uniq command will remove only the adjacent repeated lines. In this case, there are no adjacent repeated lines, so the output will be the same as the input.
To remove all repeated lines from the file, you can use the -u option with the sort command like this:
$ sort names.txt | uniq -uThis will sort the file contents and then remove all non-unique lines. The output will be empty because all lines in the original file were repeated.
The uniq command considers a line to be duplicate if they are adjacent to each other.
To understand the uniq command better, let’s change the content of the above file. Let’s create a temp.txt file and add the following content in it:
$ cat temp.txtOutput:
jane
jane
john
john
john When can execute the uniq command on this new file:
$ uniq temp.txt Output:
jane
johnSince the file had repeated lines, the uniq command only removed the adjacent repeated lines and left the unique lines intact.
You can also use -c flag to count the number of occurrence of each line:
$ uniq -c temp.txtOutput:
2 jane
3 johnThis command is helpful when you want to remove the duplicate entries/lines from a file.
The sedCommand
The [sed] is used to perform various operations on text streams, including search-and-replace, text filtering, and line numbering. Let consider this example that search and substitutes k8s with kubernetes in a blog content:
sed 's/k8s/kubernetes/g' blog.mdIn the above case, s means that we want to substitute a word, k8s is the word we want to substitute and kubernetes is the word that we want to substitute for k8s. g in the command means that we want this command to be executed in global scope which means that every instance of the match will be replaced.
So, if you call the command on the line below:
k8s k8s k8s k8s You will have the following output:
kubernetes kubernetes kubernetes kubernetesIf you call the command without the g, only the first instance of k8s will be replaced by kubernetes:
$ sed 's/k8s/kubernetes/' k8s.md Output:
kubernetes k8s k8s k8sWe have a whole post on Using sed for Find and Replace if you’d like to learn more.
The awk Command
The awk command is a versatile tool that can help you in text processing, searching for patterns in a file, scripting etc.
With the help of awk, you can do very advanced text processing like summing up numbers in a column of a file, Filtering based on a condition, Grouping and aggregating data etc . In this tutorial, you will use the awk command to select and sum the columns from the fields of a CSV file and also use it to filter out the content of a file.
The CSV file has a name, age, language, and hobby fields. You will first retrieve the age field, and then perform the sum operation on it.
The content of the CSV file is as shown below:
cat demo.csvOutput:
name,age,language,hobby
john,21,golang,painting
jane,22,python,singing
jack,25,java,reading
jill,23,python,cooking
jake,12,rust,hikingTo get the age field which is the second field:
$ awk -F , '{print $2}' demo.csvOutput:
age
21
22
25
23
12The -F flag in the above command sets the field separator to , which means awk will treat the file as a comma-separated value. With {print $2}, awk goes through each line of the file and prints the second field with.
To compute the sum of the ages in the file:
$ awk -F , '{sum+=$2} END {print sum}' demo.csvOutput:
103The above command calculates the sum of the second field in the file. The {sum+=2} will look at the second value in every field and then add it to the sum variable. The END {print sum} will be executed when all the lines are processed and prints out the final value of the sum variable.
While performing numerical computation on the content of a file, you can ignore the first line of the file in case it is a heading which are most cases, strings:
$ awk -F , 'NR>1 {print $2}' demo.csvOutput:
21
22
25
23
12NR refers to the number of records. NR>1 in the above examples means that it will not include the first record, which is the heading and not numeric data (age).
You can also use awk to filter out the content of a file. Here’s an awk script that will filter out all the links from your markdown document:
awk 'match($0, /\[([^\]]*)\]\(([^\)]*)\)/, a) \
{print "["a[1]"] ==> ("a[2]")"}' file.mdOutput:
# truncated
[cut] ==> (https://man7.org/linux/man-pages/man1/cut.1.html)
[sort] ==> (https://man7.org/linux/man-pages/man1/sort.1.html)
[tac] ==> (https://man7.org/linux/man-pages/man1/tac.1.html)
[uniq] ==> (https://man7.org/linux/man-pages/man1/uniq.1.html)The above command retrieves all the links from a markdown document. The link in a standard Markdown looks as shown below:
[Earthly](https://earthly.dev)So,the above command retrieves the link by looking for the pattern that matches how a link is embedded in a standard markdown. You can further use this to check if links are accessible or not.
We have a whole post on Understanding Awk if you’d like to learn more.
The tr Command
The tr command can be used to translate or delete characters from standard input and write the result to standard output. Some of the common use cases of the tr command include:
Translating characters from one set to another: For example, you can use the command to translate all the characters from uppercase to lowercase and vice-versa.
Removing repeated characters: You can use the command to delete and remove repeating characters from a stream of text.
Deleting characters: You can use them to delete specific characters from the input. For example, you can use the
trcommand to delete all digits from the input.
The command can be really helpful if you’re performing an operation that requires small letters only, then you can use this command as shown below:
$ echo "Hello World" | tr [A-Z] [a-z]And it will return hello world.
You can also use the following syntax for the same purpose.
echo "Hello" | tr [:upper] [:lower]Here is a practical example that you might encounter. Let’s say you have a project called “CoolProject” on GitHub and you are using a prebuilt workflow that relies on the $ variable as a tag for your container image. When the workflow is triggered, this variable will be replaced with the name of your repository. However, if your repository name includes uppercase letters, you may encounter an error similar to this:
Error parsing reference: "ghcr.io/username/CoolProject" \
is not a valid repository/tag: invalid reference format: \
repository name must be lowercaseTo avoid this error, you can use the tr command to convert the repository name to lowercase and use the result as the tag for your image. You can achieve this by passing $ to the tr command as shown below:
echo $ | tr '[:upper:]' '[:lower:]'This will ensure that your repository name is always in lowercase, which is required for container image tags.
The wc Command
wc stands for word count. It is a command that you can use to count the number of lines, words, and characters in a file. By default, the wc command counts and returns the three. To count them individually, you can specify the -l, -w, and -c flags for the number of lines, words, and characters respectively.
For example, if you have a file that has the following content:
$ cat markdown.mdOutput:
Markdown is a lightweight markup language for \
creating formatted text using a plain-text editor.When you execute wc markdown.md then you get the following output:
$ wc markdown.mdOutput:
1 14 97 markdown.mdYou specify the flag individually
For line count:
$ wc -l markdown.mdOutput:
1 markdown.mdFor word count:
$ wc -w markdown.mdOutput:
14 markdown.mdFor character count:
$ wc -c markdown.mdOutput:
97 markdown.mdThe tee Command
The tee command allows you to redirect the output of an operation to multiple streams simultaneously, such as the stdout and a file. This allows you to view the output in real-time and save it for future use.
A use case can be in inspecting your container image:
$ docker buildx imagetools inspect --raw \
hello-world | jq . | tee hello.jsonOutput:
# truncated
{
"manifests": [
{
"digest": "sha256:f54a58bc1aac5ea1a25d796ae155dc228b3f0e11d046ae276b39c4bf2f13d8c4",
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"platform": {
"architecture": "amd64",
"os": "Linux"
},
"size": 525
},
{
"digest": "sha256:40d0cfd0861719208ff9f7747ab3f97844eeca509df705db44a736df863b76af",
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"platform": {
"architecture": "arm",
"os": "Linux",
"variant": "v7"
},
"size": 525
},In this case, you’re inspecting the container and saving the output to a file for future reference. The output is redirected to both the terminal and the file.
The xargs Command
The xargs command allows you to pass the output of one command as an argument to another command.
The syntax is as shown below:
command1 | xargs command2In this case, the output of command1 will act as the input for command2. Thexargs command has flags that will give you more control on how you want the arguments to be processed.
One common use case of the xargs command is to perform batch operation on a large number of files.
For example, if you want to delete all files in the current working directory, you can use the ls command to list all the files, and then pass the output to the xargs which will execute the rm command on each file. This is shown below:
ls | xargs rmThe first command lists all the files in the current working directory using the ls command. The output of ls is then piped to the xargs, which takes each file name as an argument and passes it to the rm command. The rm command then deletes each file in one go.
It is important to note that this command can be very dangerous if used improperly as it will delete the files without asking for confirmation.
You can use -p or --interactive flag to prompt the user before running the command that follows:
$ lsOutput:
one.txt three.txt two.txtPiping the output of ls to the rm command with the command xargs in interactive mode:
$ ls | xargs -p rmOutput:
rm one.txt three.txt two.txt?...yes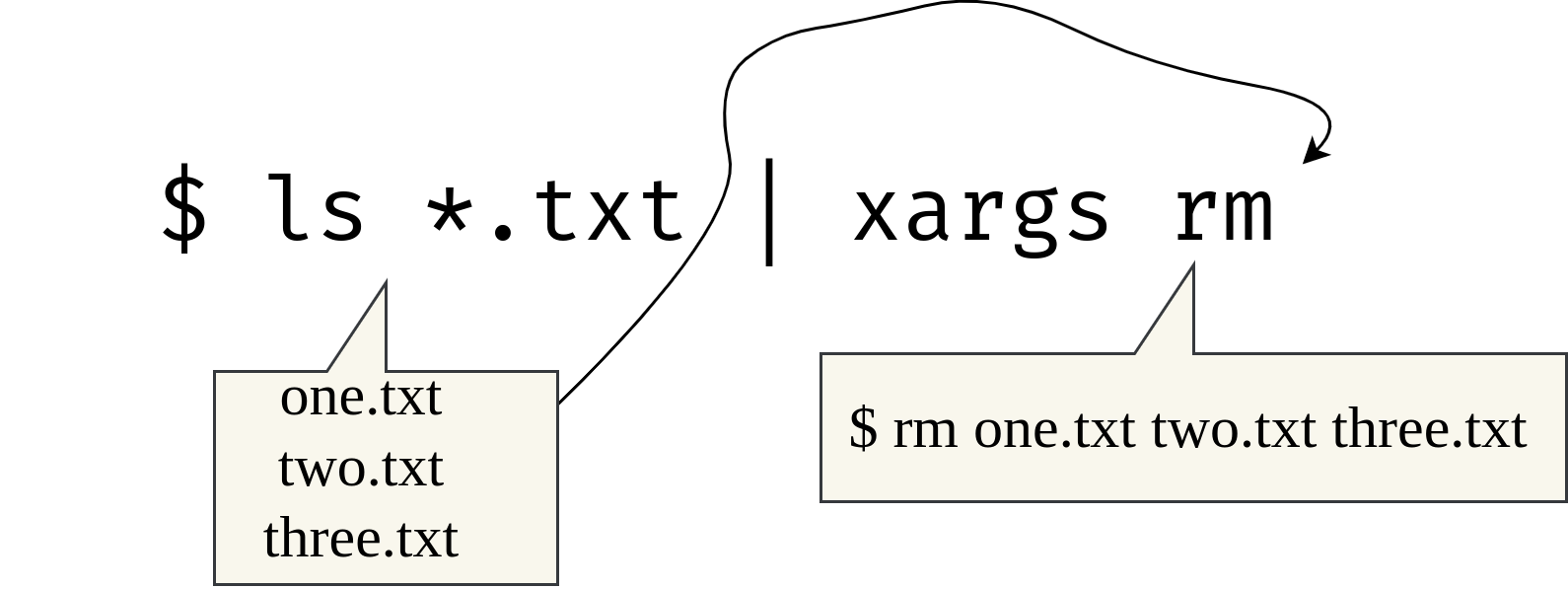
You can also use the xargs command when a particular command or subcommand is only accepting a limited number of arguments at a time, but you want to operate simultaneously on a number of arguments which is more than the limit.
Let’s take another example to understand the xargs command.
To delete multiple GitHub gists, you can use the gh delete command with the gist ID as an argument. To get the IDs of all gists in a repo, you can use gh gist list | cut -f 1. However, when passing the IDs to the delete command using xargs, it will throw an error because delete only accepts one ID at a time. To resolve this, You can use xargs -n 1 to pass one ID at a time, and confirm each deletion using -p.
List all the gists in a github repo:
$ gh gist listOutput:
ae426cdcd4ab4b5ceedd9a517c552b51 alacritty.yml \
1 file secret about 1 minute ago
0d69d3058f2250021f5de610e710de84 config.fish \
1 file secret about 1 minute ago
acadcd47046bfe82ce548c98ac928f35 init.lua \
1 file secret about 1 minute ago
508bcea1782e7aed3b03f30fe053823a after.txt \
1 file secret about 6 days agoGet the ids of all the gists using the cut command (You can also use awk):
$ gh gist list | cut -f 1Output:
ae426cdcd4ab4b5ceedd9a517c552b51
0d69d3058f2250021f5de610e710de84
acadcd47046bfe82ce548c98ac928f35
508bcea1782e7aed3b03f30fe053823aPipe gh gist delete to delete all the gists:
$ gh gist list | cut -f 1 | gh gist deleteOutput:
cannot delete: gist argument required
Usage: gh gist delete {<id> | <url>} [flags]The above command is giving us an error that says gist argument required.
Let’s use simple xargs and see if it works:
$ gh gist ls | cut -f 1 | xargs gh gist deleteOutput:
too many arguments
Usage: gh gist delete {<id> | <url>} [flags]It doesn’t work because the xargs command passes all the arguments at once which the gh gist delete command doesn’t accept. In this case, we will use the -n or --max-args flag and xargs will execute the command with one argument at a time only.
I’m using -p flag to prompt out on the terminal:
$ gh gist ls | cut -f 1 | xargs -n 1 -p gh gist deleteOutput:
gh gist delete 0548469636c528324c4b4e1fcb4e4ab3?...yes
gh gist delete f1fc4aff1ba53f7011cf6aa4b0cc39b4?...yes
gh gist delete fdbc6b77d5c3fee50f9bdab50668a841?...yes The command will operate on one gist ID at a time and will ask for your confirmation before deleting this.
The above command explains to you how you can use xargs to pass multiple arguments to a function which takes only one parameter.
Modern Linux Command Line Tools
Apart from the commands discussed above, there are many modern tools that can be used as alternatives to the longstanding Unix commands. These commands are generally fast and come with a rich UI. Majority of them are written in the Rust programming language. In order to use these commands, make sure that you’ve these tools installed on your system, as they’re not installed by default.
The rg Command
The ripgrep (rg) command is a modern alternative to grep. It’s a fast command line search tool that recursively searches the files in your current directory for a regex pattern. It’s written in Rust, and it’s very fast.
You can use this command to search for a pattern in a file or from standard output:
rg 'pattern'This will recursively search for the pattern in the current directory and give you the output along with filename and line number:
$ rg 'seven'Output:
numbers.txt
7:sevenYou can imitate the behaviour of the rg command in the grep command by specifying the -n flag to get the line number and -r flag to get recursive listing:
$ grep -rn 'seven'Output:
numbers.txt:7:sevenYou see that the output is almost the same. The only difference is that in rg recursive grepping with line number is the default behaviour.
The bat Command
The bat command is a modern alternative to the cat command. It supports syntax highlighting for a bunch of languages and comes with a lot of configuration options. For configuring bat, you can edit the bat config file at ~/.config/bat/config.
Let’s see a simple hello world program in Go and a CSV file:
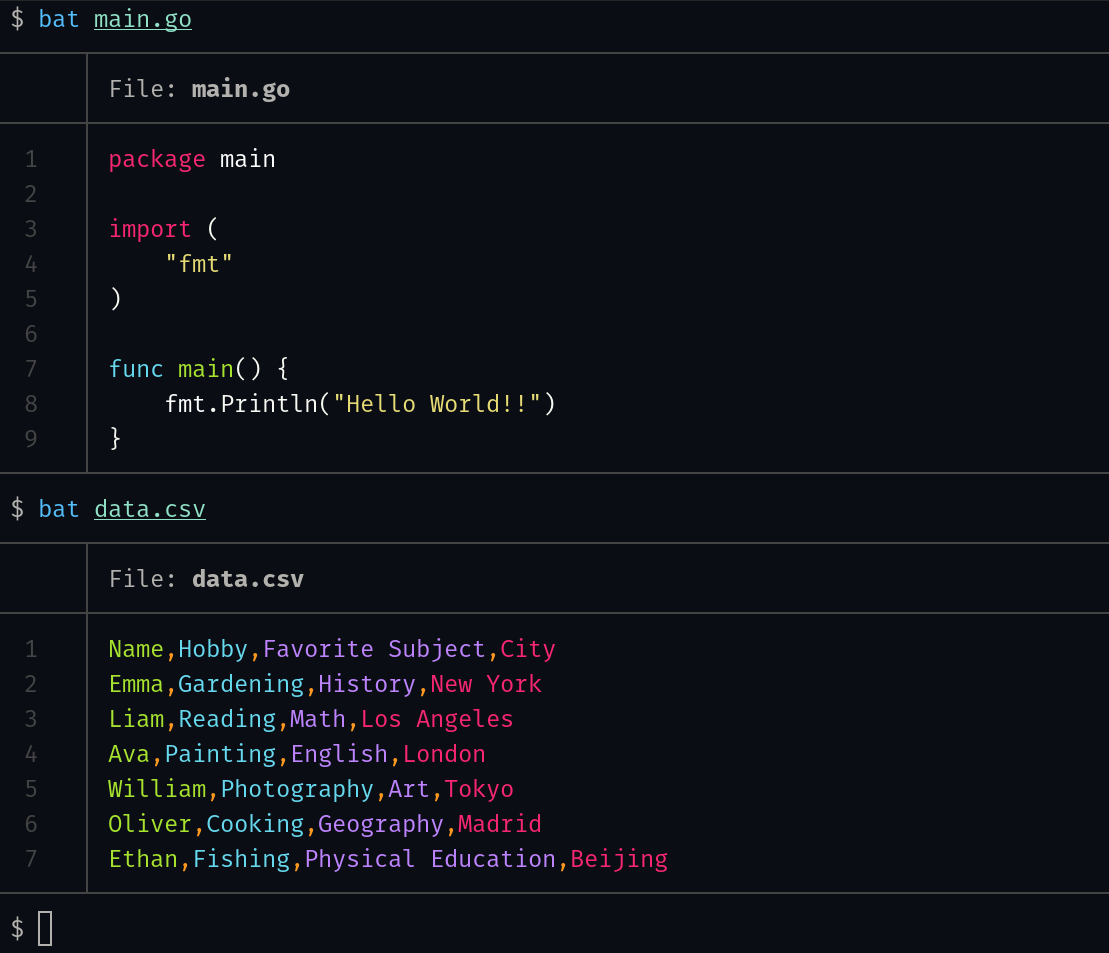
You can see the default syntax highlighting that the bat command ships with.
The fdCommand
The fd command lets you search for files with the name of the files in your system. The find command on Linux can be confusing to begin with because it comes with a lot of flags and when you want to search a file this can be tedious. One better alternative to find is fd. It’s simple, fast and user-friendly. This ships with perfect default options that make it easier to use. You just need to provide the file pattern, and it will give you the output.
$ fd bpfOutput:
# truncated
KubeArmor/BPF/
KubeArmor/BPF/enforcer.bpf.c
KubeArmor/BPF/libbpf/
KubeArmor/enforcer/bpflsm/
KubeArmor/enforcer/bpflsm/enforcer_bpfeb.goWith find, achieving the above result is a little complex as you’ve to do the same using this.
$ find . -type f | grep bpfOutput:
# truncated
./.gitbook/assets/bpf-lsm.png
./.github/workflows/install-libbpf.sh
./KubeArmor/enforcer/bpflsm/enforcer_bpfeb.o
./KubeArmor/enforcer/bpflsm/hostRulesHandling.go
./KubeArmor/enforcer/bpflsm/mapHelpers.go
./KubeArmor/enforcer/bpflsm/bpffs.goIn the above example, I have just given the expression that I want to query for in my file, and we received the file pattern that’s matching the expression. In this case, it’s giving me all the files that have bpf in their names.
Conclusion
In this blog, we have covered a variety of Linux text processing command including the sed, grep, awk, tr, wc, cut, sort, tac, bat, fd, uniq and xargs. The combination of these tools will help you perform a wide range of necessary text manipulation in your daily workflow, from searching and replacing text to extracting data from a file.
We have also discussed examples along with each command. As with everything in Unix, there are multiple ways to achieve them, so feel free to practise more according to your use cases. If you’re new to text processing, it is encouraged to experiment with these commands.
Additional Resources
Here are some more resources you can use to supplement your learning and fine-tune your skills.
Earthly makes CI/CD super simple
Fast, repeatable CI/CD with an instantly familiar syntax – like Dockerfile and Makefile had a baby.








