
Understanding Kubernetes Operators

We’re Earthly. We make building software simpler and therefore faster using containerization. Check us out.
When you opt to use Kubernetes for application deployment, out of the box, it provides a wide range of automation features that make it easy to deploy and manage stateless applications. However, for more complex, stateful applications, additional automation may be required to manage the specific requirements of the application.
The key features of Kubernetes include its balance of simplicity and flexibility, its ability to automate various functions, and its capability to scale and adapt to diverse contexts and applications.
However, these same principles also limit its initial functionality to a restricted set of commands and operations that are exposed through APIs. For more complex tasks, this set must be extended and more sophisticated automation must be created depending on the specific application. This is where the operators come in.
Kubernetes Operators are custom controllers that extend the Kubernetes API to create, configure, and manage the lifecycle of complex applications. They provide a higher-level abstraction over the underlying Kubernetes resources, making it easier to deploy and manage stateful applications in Kubernetes. With operators, you can automate tasks such as scaling, backup and restore, and rolling updates, as well as manage the lifecycle of your application in a more automated and efficient way.
In this article, you’ll learn what Kubernetes operators are, how they work, and the benefits they can offer you.
What Are Kubernetes Operators?

Kubernetes Operators are application-specific controllers that extend the capabilities of the Kubernetes API to create, configure, and manage complex applications on behalf of Kubernetes users by extending the capabilities of the Kubernetes API.
The Kubernetes project defines “Kubernetes Operator” in a simple way: “Operators are software extensions that use custom resources to manage applications and their components”.
Operators, in a nutshell, allow for more specific management of an application within a Kubernetes cluster. Rather than managing a collection of basic building blocks like Pods, Deployments, Services, or ConfigMaps, an application is viewed as a single object that only exposes the adjustments that are relevant to that particular application, such as scaling, self-healing, and updates, when using operators. In this way, operators allow you to make application-specific changes rather than managing each component individually.
The Problem That Kubernetes Operators Solve
In Kubernetes, controllers of the control plane implement control loops that repeatedly compare the desired state of the cluster to its actual state. If the cluster’s actual state doesn’t match the desired state, then the controller takes action to fix the problem. These controllers can be used to manage and scale stateless applications, like web apps, mobile app backends, and API services, because these types of applications are generally easier to manage and scale. This is because stateless applications do not maintain any state or store any data locally, so they can be easily scaled up or down and recovered from failures without the need for additional knowledge or complexity.
Challenges Associated With Stateful Applications
Stateful applications like databases can be challenging to manage and scale since they are not as straightforward as stateless applications. In all stages of their lifecycle, these applications require more “hand holding” when they are created, while they are running, and when they are destroyed.
This hand holding includes additional steps that need to be taken such as configuring persistent storage, data migration, and setting up appropriate ReplicaSets. During the running phase, managing the state of the application, scaling and performing updates, and ensuring data consistency across replicas can be complex tasks. Finally, when destroying stateful applications, special care must be taken to ensure that data is properly backed up and migrated before the application is terminated. Kubernetes does not automatically handle all these tasks for stateful applications. Consider the example of creating three replicas of the MongoDB database:
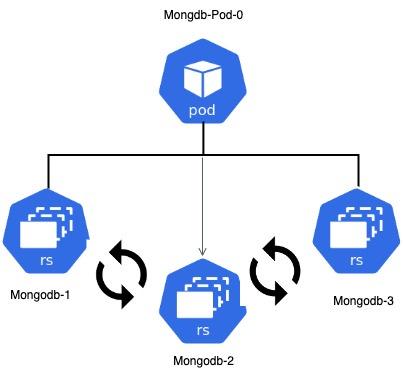
Each replica has its own state and identity, making it difficult to keep them in sync. When performing updates or destroying the database, the order in which these actions are performed is critical to maintaining data consistency. Furthermore, constant synchronization between replicas must be maintained. This is just one example, but the management processes for various databases such as MySQL, Postgres, Cassandra, and Redis will also differ. This makes it difficult to have a single solution that can automate the entire process for all systems and applications.
This makes managing stateful application lifecycles on Kubernetes require manual intervention by people, called “human operators”, to manage and operate these applications. Having to manually maintain and update these applications goes against Kubernetes’ main goal of providing automation and self-healing.
With Kubernetes Operator, the human operators are replaced with software operators. So all the manual tasks that human operators would do to operate a stateful application are now packed into a program that knows how to deploy and manage that specific application. This makes tasks automated and reusable. This means if some databases are running in your cluster, you don’t have to manually configure and maintain these applications. You simply declare the desired state of the application, and the Kubernetes operator handles the rest by creating the desired state.
Benefits of Using a Kubernetes Operator

Kubernetes operators are controllers that execute loops to check the actual state of a cluster and the desired state, acting to reconcile them when the two states are drifting apart. Kubernetes operators provide a number of benefits, including:
Simplicity and Flexibility
Kubernetes operators provide a simple and flexible way to automate complex tasks in Kubernetes. They allow you to define the desired state of your applications and infrastructure in custom resource definitions (CRDs), and then automatically ensure that the actual state matches the desired state. This can help reduce the time and effort required to manage and maintain your applications and infrastructure.
Automation
Kubernetes operators provide a high level of automation, which can help reduce the time and effort required to manage and maintain your applications and infrastructure. They can automatically provision and configure resources, such as pods and services, as well as monitor and maintain the health of your applications and infrastructure. For example, if a pod fails, an operator can automatically create a new pod to replace it, ensuring that the desired number of replicas is maintained.
Easy Integration With Other Tools
Kubernetes operators can be integrated with other tools, such as monitoring and observability tools, continuous delivery tools, and networking tools. This allows you to use them in conjunction with these other tools to manage and monitor your applications and infrastructure. For example, you can use an operator to automatically provision and configure a monitoring tool, such as Prometheus, and then use the monitoring tool to monitor the health and performance of your applications and infrastructure.
Extensibility
Kubernetes operators are highly extensible, which allows you to customize and tailor them to your specific needs. You can define your own CRDs and build custom controllers to automate tasks that are not covered by the out-of-the-box Kubernetes functionality. This can be particularly useful if you have specific requirements or constraints that are not addressed by the default Kubernetes functionality.
How Kubernetes Operators Work
Essentially, an operator watches the Kubernetes API for changes related to a specific resource, such as a custom resource definition (CRD). When a change is detected, the operator takes action to ensure the desired state of the resource is met. For example, if a new replica is added to a stateful set, the operator will ensure the necessary resources are allocated and the replica is correctly added to the set.
Operators use a control loop to continuously check the status of the resources they are managing and make any necessary adjustments. This allows for automatic scaling, failover, and other operations to be handled without human intervention.
Additionally, operators often provide a custom user interface, such as a command-line tool or web interface, for interacting with the resources they manage. This allows for more intuitive and user-friendly management of the underlying infrastructure.
In summary, Kubernetes operators provide a powerful and efficient way to manage stateful applications within a Kubernetes cluster. They use a control loop to continuously check the status of resources and make any necessary adjustments, and often provide a custom user interface for interacting with the resources they manage. This allows for automatic scaling, failover, and other operations to be handled without human intervention.
Understanding the Kubernetes Operator Architecture
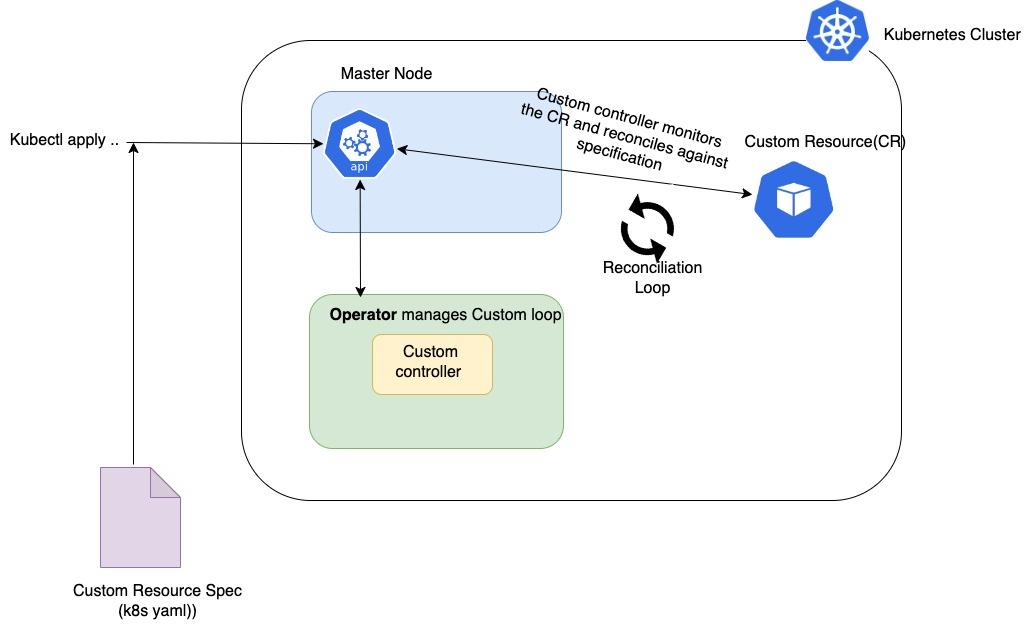
A Kubernetes operator at its core has the same control loop mechanism as Kubernetes that monitors changes to the application state. They typically consist of the following components:
Custom Resource Definitions (CRDs)
CRDs define the custom resources that are managed by the operator. They specify the desired state of the resources and the API used to interact with them.
Custom Controller
The controller is the main component of the operator. It executes a loop to continuously check the actual state of the resources and the desired state, and then acts to reconcile the two states when they are drifting apart. The controller uses the API specified in the CRDs to interact with the resources.
Reconciliation Loop
The reconciliation loop is the main loop executed by the controller in a Kubernetes operator. It continuously checks the actual state of the resources and the desired state, and then acts to reconcile the two states when they are drifting apart. The reconciliation process begins by fetching the current state of the resources from the API server. The API server stores the current state of the resources and makes it available to the controller. Once the current state has been fetched, the controller compares it with the desired state, which is defined in custom resource definitions (CRDs), and specifies the desired configuration and properties of the resources.
The controller identifies any differences between the current state and the desired state and performs any necessary actions to reconcile them. It may involve creating or deleting resources, or modifying their configurations.
For example, if the desired state specifies that a particular pod should have three replicas, but the current state only shows two replicas, the controller might create a new replica to match the desired state. Following the reconciliation process, the controller updates the desired state to reflect any changes. By doing so, the desired state is accurately reflected in the current state. As the resources drift away from the desired state, the controller continually checks the actual state of the resources and acts to reconcile them.
API Server
The API server is the component that exposes the API used to interact with the resources. It is responsible for storing the current state of the resources and making it available to the controller.
Kubernetes Operator in Action
This section will walk you through installing, and configuring a MongoDB Community Operator in your Kubernetes cluster. By the end of this section, you should have a MongoDB cluster running in your Kubernetes environment.

Prerequisites
To follow along with this step-by-step tutorial, you should have the following:
- Local installation of Kubernetes and kubectl
- Local installation of Git, JQ, and Mongosh.
Installing MongoDB Operator CRD
As a first step, you must install the MongoDB operator’s Custom Resource Definition (CRD). This is required because the CRD will be used to define the custom resource that the operator will use to manage the MongoDB cluster. To do so, run the following commands:
# clone the repository containing the MongoDB operator and Crds manifest.
git clone https://github.com/segunjkf/mongodb-operator.git && \
cd mongodb-operator
# Apply the MongoDB CRD configuration
kubectl apply -f mongodb-crd.yaml Installing the Kubernetes Operator
The next step is to create a namespace for the operator and its resources, which will create an isolated place in your Kubernetes cluster for the MongoDB operator resources to be deployed. Run the following commands to accomplish this.
kubectl create namespace mongodb-operatorAfter creating the namespace, the next step is to create the role and role-binding needed to grant the required permission to the MongoDB operator. To do so, run the following commands:
kubectl apply -f mongo/ -n mongodb-operator
You now have the required roles and permission for the operator to use, the next step is to deploy the MongoDB operator. To do run the following commands:
kubectl apply -f operator.yamlYou now have the MongoDB operator in your cluster. You can confirm the operator pod by running the following command:
kubectl get pods -n mongodb-operator
📑The GitHub repository you cloned was created specifically for this guide, and it has been modified so that you can quickly get started with the MongoDB operator. Please refer to the official MongoDB community operator Github Repository for more information and the full source code.
Setting Up the MongoDB Cluster
With the MongoDB operator now running in your Kubernetes cluster, you will create a MongoDB custom resource (CR) that defines your desired MongoDB cluster state.
# Create a secret for the MongoDB cluster
kubectl create secret generic admin-user-password -n mongodb-operator \
--from-literal="password=admin123"
# MongoDB Cluster YAML configuration
kubectl apply -f - <<EOF
---
apiVersion: mongodbcommunity.mongodb.com/v1
kind: MongoDBCommunity
metadata:
name: my-mongodb
namespace: mongodb-operator
spec:
members: 1
type: ReplicaSet
version: "5.0.5"
security:
authentication:
modes:
- SCRAM
users:
- name: admin-user
db: admin
passwordSecretRef:
name: admin-user-password
roles:
- name: clusterAdmin
db: admin
- name: userAdminAnyDatabase
db: admin
scramCredentialsSecretName: my-scram
additionalMongodConfig:
storage.wiredTiger.engineConfig.journalCompressor: zlib
statefulSet:
spec:
template:
spec:
containers:
- name: mongod
resources:
limits:
cpu: "1"
memory: 2Gi
requests:
cpu: 500m
memory: 1Gi
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- my-mongodb
topologyKey: "kubernetes.io/hostname"
volumeClaimTemplates:
- metadata:
name: data-volume
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 40G
EOFThe YAML file defines a Custom Resource Definition (CRD) for the MongoDB community operator. The file defines a MongoDBCommunity resource, with metadata that includes a name and namespace, and a spec field that contains configuration for the MongoDB Community replica set.
The spec field includes various parameters that define the configuration of the MongoDB replica set, such as the number of members, the version of MongoDB, and the security settings.
The members field specifies the number of members in the replica set, in this case 1. The type field is set to ReplicaSet, the version field is set to “5.0.5” and the security field specify how the authentication is going to be done, in this case using SCRAM and credential for that is defined in scramCredentialsSecretName field. The users field specifies the users that will be created when the replica set is deployed and their roles.
The additionalMongodConfig field is used to set additional configuration options for the MongoDB server. In this case, it’s setting the journalCompressor option to zlib.
The statefulSet field is used to configure the Kubernetes StatefulSet that will be created to deploy the MongoDB replica set. It specifies the template field with the container’s resources and the affinity field to configure podAntiAffinity and the volumeClaimTemplates field to configure the storage for the data-volume.
It may take a few seconds for your MongoDB cluster to be created. To make sure that the pod is running and passed all the health checks, run the following command:
kubectl get pods -n mongodb-operatorThe cluster is now up and running, under the hood, the MongoDB operator took care of creating and managing the necessary Kubernetes resources, such as pods, PVC, and services, to reach the desired state of the defined MongoDB cluster. The operator will also handle tasks such as scaling, updates, and ensuring data consistency across replicas.
Connecting to the MongoDB Database
Having set up MongoDB Cluster, you are now ready to start using it. You will test the database by connecting to it, creating a new user, and inserting a record to test your MongoDB cluster.
Firstly, connect to the database. You are going to be using a mongosh shell to connect to the MongoDB cluster. To ensure access to the cluster locally, forward traffic to the mongoDB cluster. To do so, run the following commands
kubectl port-forward my-mongodb-0 27017 -n mongodbThe next step is to connect to the database, but first, you must obtain the database password. Alternatively, open a new terminal and run the following commands:
kubectl get secret my-mongodb-admin-admin-user -n \
mongodb-operator -o json | jq -r '.data | with_entries(.value |= @base64d)'
Now run MongoSH to connect to the database:
Mongosh "mongodb://admin-user:admin123@127.0.0.1:27017/admin?directConnection=true&serverSelectionTimeoutMS=2000"
You have now established a connection to the MongoDB cluster. Let’s list the databases that are currently available:
show dbs
You will now create a new user and grant read and write permissions. To do so run the following command:
db.createUser(
{
user: 'new-user',
pwd: 'new-user-password',
roles: [ { role: 'readWrite', db: 'store' } ]
}
);
This command creates a new user in the MongoDB database with username “new-user” and password “new-user-password”, and assigns the “readWrite” role to the user on the “store” database. This allows the “new user” to have read and write permissions on the store database.
The next step is to confirm its access by authenticating it with its credentials against the current cluster. In order to do this, run the command below:
db.auth( 'new-user', 'new-user-password' )
Following successful authentication, you will create a new database named ‘store’ for the new user. Run the following command to accomplish this:
use storeNext, insert a record using the insertOne command:
db.employees.insertOne({name: "Anton"})
This command created a new employee document with the field name “Anton” in the employees collection. Now you can try to retrieve all the records in the collection. To do so run the following command:
db.employees.find()
To sum up, you deployed a MongoDB operator to your Kubernetes cluster, and declared the desired cluster state with an operator custom resource YAML, and the operator took care of meeting the desired state. You also connected to the database and performed some queries to test the setup.
Examples of Kubernetes Operators

Here are some K8s operators that you’ll find helpful:
MongoDB Operator
MongoDB operator translates human knowledge of creating a MongoDB instance into a scalable, repeatable, and standardized method. It provides features such as automated provisioning and scaling of database instances, as well as backup and restore capabilities.
Prometheus Operator
Prometheus operator simplifies the deployment and management of Prometheus monitoring instances in production environments by providing automated provisioning, scaling, integration with other monitoring tools, and alerting capabilities.
It uses custom resource definitions (CRDs) to specify the desired configuration of the Prometheus instances and handles tasks such as creating pods, services, and persistent volumes, as well as configuring the instances. The operator also integrates with other monitoring and observability tools, such as Grafana, Alertmanager, and Cortex, and includes alerting capabilities to notify of issues with applications or infrastructure.
Calico Operator
Calico operator simplifies the deployment and management of Calico networking components in production environments by automating provisioning, configuration, integration with other networking tools, and monitoring features. In addition to defining the desired configuration of Calico components via custom resource definitions (CRDs), it handles tasks such as creating pods, services, persistent volumes, and configuring Calico components, as well as handling network topology, IP ranges, and network policies. It also integrates with Kubernetes NetworkPolicy, Istio, and OpenShift Router, and enables monitoring so that users are alerted if there are issues.
ArgoCD Operator
ArgoCD Operator automates provisioning, configuration, integration with other continuous delivery tools, and monitoring for ArgoCD, a continuous delivery tool, in Kubernetes-based production environments. The ArgoCD operator makes ArgoCD deployment and management easier. It is in charge of tasks like creating pods, services, and persistent volumes, as well as configuring ArgoCD instances with custom resource definitions. It also allows you to configure options for ArgoCD instances such as replication number, storage size, and resource limits. The operator also includes monitoring capabilities to send alerts if an issue arises with the instances, as well as integration with Jenkins, GitLab, and GitHub.
A central repository for finding and deploying Kubernetes operators is provided by two official applications: Artifact Hub and Operator Hub. Artifact HUB, a CNCF project, provides a searchable repository for both operators and Helm charts, while Operator Hub, a Red Hat project, focuses exclusively on operators. These applications make it easy to discover and deploy operators in your Kubernetes clusters.
Conclusion
In this quick read, we dug into Kubernetes operators—what they are, why they’re great for handling stateful apps, their perks, architecture, and operation. In short, these operators automate and simplify managing trickier apps by customizing Kubernetes resources. They’re a lifesaver for managing stateful apps in a Kubernetes cluster.
As you continue to explore their application in your projects and learn more about the different operators available for your specific needs, you might also be interested in further streamlining your CI/CD process. If so, take a peek at Earthly. It could be a game-changer for your Kubernetes workflow.
Earthly makes CI/CD super simple
Fast, repeatable CI/CD with an instantly familiar syntax – like Dockerfile and Makefile had a baby.








