
Scheduling Periodic Log Compression and Upload to AWS S3 using Kubernetes CronJobs

We’re Earthly.dev. We make building software simpler and therefore faster – like Dockerfile and Makefile had a baby. This article shows us how to compress Kubernetes logs and send them to S3 periodically.
Logs are essential for monitoring and troubleshooting modern applications in a Kubernetes environment. However, as applications generate more logs, managing them can become a challenge. The storage costs can quickly add up, and retrieving relevant logs from multiple locations can be time-consuming and inefficient. To solve this problem, log compression and periodic uploading to a centralized location like AWS S3 can help reduce storage costs and make log retrieval much easier. Kubernetes CronJobs offers a powerful way to automate these tasks, allowing you to compress and upload logs at scheduled intervals with ease.
In this article, you’ll explore how to use Kubernetes CronJobs to manage logs in a Kubernetes environment and also dive into using Kubernetes CronJobs to set up and configure log compression and uploading to AWS S3.
By the end of this article, you’ll have a clear understanding of how to use Kubernetes CronJobs to automate the management of logs in a Kubernetes environment, reducing storage costs and making log retrieval more efficient.
Prerequisites
To follow along in this tutorial, you should have the following:
- A basic understanding of NodeJS and NPM installed on your machine.
- Kubectl installed on your machine, and a running Kubernetes Cluster already created (any number of nodes works fine).
- An AWS S3 bucket already created - this tutorial utilizes a pre-existing bucket named
postgres-database-logs. - An AWS IAM user with permission to interact with the S3 bucket.
- Docker installed on your machine, a DockerHub account, and a public repository already set up. The public repository will be used to host the Docker image of our script and will make it publicly accessible. This allows Kubernetes to pull the image from the repository without needing additional credentials or access permissions - This tutorial uses a repository called logs-cronjob.
Setting Up the Environment
To implement log compression and uploading to AWS S3 with Kubernetes CronJobs, several steps must be implemented to set up the necessary environment. In this section, we will walk through the process of setting up the environment for our implementation. This includes creating a Kubernetes Statefulset for PostgreSQL, verifying the Statefulset, and creating an S3 bucket in AWS for compressed log files.
💡Stateful applications, such as databases, are deployed and managed in Kubernetes using resources called StatefulSets. For database systems to guarantee data consistency and durability, they provide stable and distinct network identities, orderly deployment, and scaling, and stable storage for each instance.
Create a database namespace with the following kubectl command:
kubectl create ns database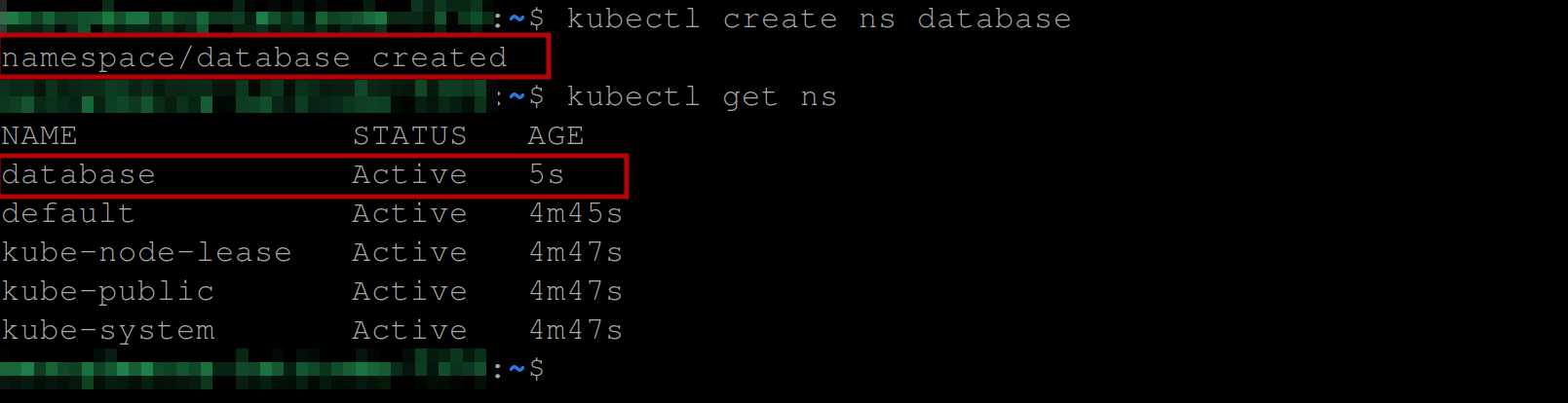
Execute the following line of code to create a Kubernetes secret object in the databse namespace. This Kubernetes secret will store a username and password for the PostgreSQL database securely. This is the secret we’ll use in our PostgreSQL Statefulset, later on, to authenticate with the PostgreSQL database server.:
kubectl create -n database secret generic postgres-secret \
--from-literal=username=admin --from-literal=password=123456
Create a file postgres-statefulset.yaml and paste in the following configuration settings to create a Kubernetes Statefulset object for a PostgreSQL database with two replicas:
#postgres-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: postgres
spec:
serviceName: postgres
selector:
matchLabels:
app: postgres
replicas: 2
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres
imagePullPolicy: "IfNotPresent"
env:
- name: POSTGRES_USER
valueFrom:
secretKeyRef:
name: postgres-secret
key: username
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: postgres-secret
key: password
ports:
- containerPort: 5432 Let’s go through each section of the above YAML file:
apiVersion: Specifies the API version used for the Kubernetes resource.kind: Defines the resource type as aStatefulSetfor managing stateful applications.metadata: Sets the unique name of the StatefulSet resource topostgres.spec: Specifies the name of the associated Kubernetes service which is namedpostgresin this case.selector: Defines the labels used to select the Pods that the StatefulSet should manage..replicas: Sets the desired number of pod replicas to2.template: Describes the pod template used to create the actual pods.metadata: Contains labels used to identify the Pods (app: postgres).labels: Defines the label for the pod template, ensuring that pods created from this template are assigned the labelapp: postgres.spec: Defines the specification of the Pods.containers: Contains a list of containers within the pod. In this case, this pod will only contain one container.name: Specifies the name of the container aspostgres.image: Specifies the container image to be used. Which in this case is the officialpostgresdocker image.imagePullPolicy: Defines the image pull policy for the container. In our case, it is set toIfNotPresentwhich means the image is pulled only if it is not already present locally.env: This section defines environment variables for the container. In our case, we set an environment variablePOSTGRES_USERwith a value retrieved from a keyusernamewithin a secret. The secret is thepostgres-secretwe created earlier. Also, we set another environment variablePOSTGRES_PASSWORDfrom the same secret and retrieve the value of the keypassword.
ports: Specifies the container’s port configuration.containerPort: Sets the port number5432to be exposed by the container, which is the default port for PostgreSQL.
Execute the following commands to create and view the Statefulset resource:
kubectl apply -n database -f postgres-statefulset.yaml
kubectl get statefulsets -n database
kubectl get pods -n databaseThese commands will create a Statefulset and then list all Statefulsets and pods in the cluster within the database namespace, respectively.
The image below shows that the Postgres StatefulSet is being created with the 2 replicas (pods) up and running:

When interacting with a PostgreSQL server running as a StatefulSet in a Kubernetes cluster, we need to create a service to expose it. You can create a Kubernetes service through the below YAML configuration file. You can create a file postgres-service.yaml and paste into it the following configuration settings:
#postgres-service.yaml
apiVersion: v1
kind: Service
metadata:
name: postgres-service
spec:
selector:
app: postgres
ports:
- name: postgres
port: 5432
targetPort: 5432This will create a service named postgres-service to expose the Postgres StatefulSet within the Kubernetes cluster to listen on port 5432 and forward traffic to the same port on the target pods.
Execute the following command to create the Kubernetes service:
kubectl apply -f postgres-service.yaml -n database
Now, the Postgres Statefulset is exposed internally - inside the Kubernetes Cluster - and we can interact with it through the service we just created.
Scripting and Dockerization
Since we have set up the environment and created a Statefulset for the PostgreSQL database, the next step is to create a script using NodeJS, that will enable us to programmatically retrieve, compress, and upload the logs to a centralized location such as AWS S3.
💡 This tutorial uses NodeJS to write the script, you can use any programming language you are conversant with.
First, we will write a script using the Node.js Kubernetes client library to retrieve logs from the PostgreSQL Statefulset programmatically. Next, we will write a script to compress the logs for storage efficiency. Finally, we will write a script using the AWS SDK for JavaScript to upload the compressed logs to AWS S3.
Once the scripts have been written and tested, we will containerize them using Docker to create a portable and easily distributable solution.
Create a working directory with the following command and change the directory to it:
mkdir cronjob
cd cronjobInitialize a NodeJS project and install the NodeJS Kubernetes client library with the following commands:
npm init -y
npm install @kubernetes/client-nodeThis will provide a set of APIs and tools to interact with Kubernetes clusters programmatically using Node.js, and will also allow us to manage Kubernetes resources, perform operations like creating, updating, and deleting objects, and retrieve information about our cluster.
Execute the following command to install the AWS SDK for JavaScript module that provides functionality for working with Amazon S3, specifically the @aws-sdk/client-s3 module:
npm install @aws-sdk/client-s3 
Once you have AWS SDK installed, follow these instructions to proceed to the next step:
Create a file named
index.jsin your current working directory. This file will serve as the main location for our script.Locate the
package.jsonfile in your working directory. This file was automatically created when we initialized our NodeJS project using thenpm init -ycommand.Open up the
package.jsonfile and make the edits to match the following configuration below:
#package.json
{
...
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "node index.js"
},
...
}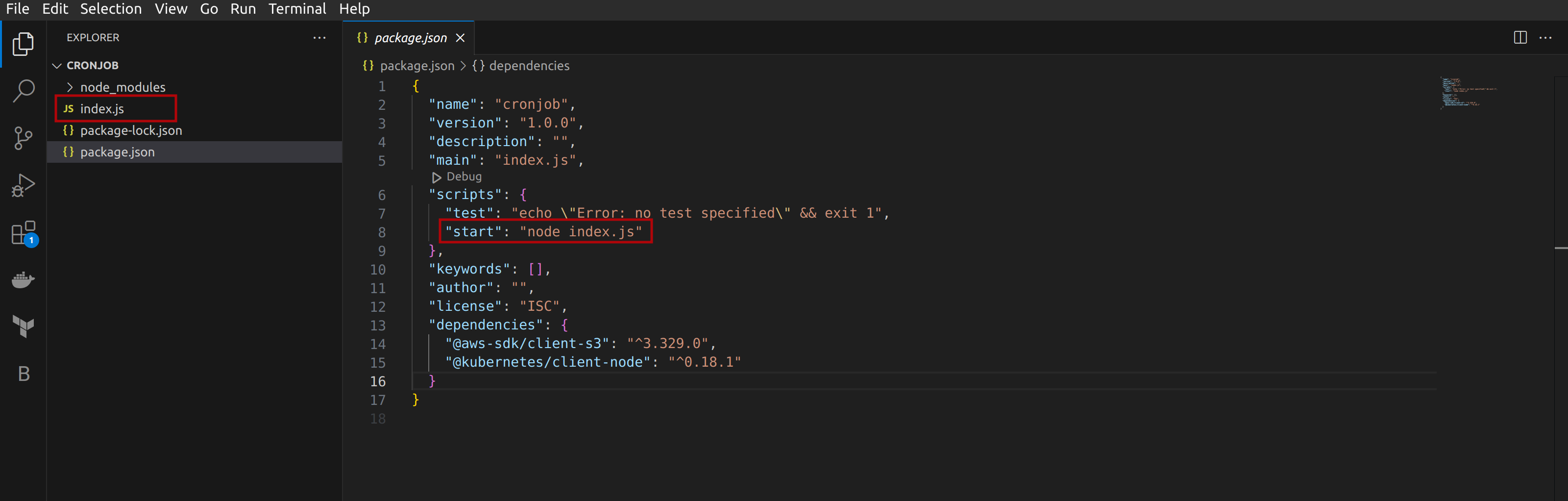
package.json fileDoing this will set the index.js file as the main entry point and set the script to run with the npm start command.
Now refer to the following URL from github to get the full NodeJS script and paste it into the index.js file.
Here’s a brief explanation of what each section in the code does:
- First, we import the libraries needed for our script to run successfully which are the AWS SDK for JavasScript V3, the
gzipSyncfunction from the Node.jszliblibrary and the Kubernetes client for Node.js. Then we load the Kubernetes configuration from a file namedcronjob-kubeconfig.yaml.
💡In this scenario, you need to create a file called cronjob-kubeconfig.yaml that contains your cluster’s kubeconfig (i.e the information about your Kubernetes cluster, such as the API server address, authentication credentials, and cluster context) in your working directory.
Doing this will ensure that the script can locate and load the configuration settings for your Kubernetes cluster correctly. You have the flexibility to choose any name for this file according to your preference.
const { S3Client, PutObjectCommand } = require("@aws-sdk/client-s3");
const { gzipSync } = require("zlib");
const k8s = require("@kubernetes/client-node");
const kc = new k8s.KubeConfig();
kc.loadFromFile("./cronjob-kubeconfig.yaml");- Secondly, we create instances of the Kubernetes API clients for
AppsV1ApiandCoreV1Apiby defining the Kubernetes namespace from which the logs will be retrieved which is in this case calleddatabase, the name of the StatefulSetpostgres, and the name of the compressed log file.
const k8sApi = kc.makeApiClient(k8s.AppsV1Api);
const coreApi = kc.makeApiClient(k8s.CoreV1Api);
const namespace = "database";
// Define the namespace where the logs will be retrieved from
const statefulSetName = "postgres";
const compressedLogFilename = `${statefulSetName}-logs-` \
+ new Date().toISOString() + ".gz";Also, we initialize an instance of the AWS S3 client with our specified AWS region and access credentials. And then, define the name of the S3 bucket where the compressed log file will be uploaded.
const s3 = new S3Client({
region: "YOUR_REGION",
credentials: {
accessKeyId: 'ACCESS_KEY_ID',
secretAccessKey: 'SECRET_ACCESS_KEY_ID',
},
});
const bucketName = "postgres-database-logs"; Be sure to replace the following REGION, ACCESS_ID and SECRET_ACCESS_ID with your own data.
Next, we define an asynchronous function retrieveLogs() to retrieve logs from all pods in the postgres StatefulSet. We then fetch the StatefulSet object, extract the pod labels, and list the pods using those labels. After that, we iterate over the pods and retrieve their logs; then we compress and upload them to our pre-existing S3 bucket using the AWS SDK for JavaScript. Finally, we log a success message for each pod indicating that its logs have been uploaded.
async function retrieveLogs() {
const statefulSet = await k8sApi.readNamespacedStatefulSet\
(statefulSetName, namespace);
const podLabels = statefulSet.body.spec.selector.matchLabels;
const pods = await coreApi.listNamespacedPod(namespace, undefined, \
undefined, undefined, undefined, Object.keys(podLabels).map \
(key => `${key}=${podLabels[key]}`).join(','));
for (const pod of pods.body.items) {
const logsResponse = await coreApi.readNamespacedPodLog \
(pod.metadata.name, namespace);
const compressedLogs = gzipSync(logsResponse.body);
const uploadParams = {
Bucket: bucketName,
Key: `${pod.metadata.name}-${compressedLogFilename}`,
Body: compressedLogs,
};
const uploadCommand = new PutObjectCommand(uploadParams);
await s3.send(uploadCommand);
console.log(`Logs for pod ${pod.metadata.name} uploaded to S3 \
bucket ${bucketName} as ${pod.metadata.name}-${compressedLogFilename}`);
}
}Finally, we invoke the retrieveLogs() function and handle any errors that may occur during its execution.
retrieveLogs().catch((err) => console.error(err));Dockerizing the Script and Deploying to DockerHub
Now that we have our script, it’s time to containerize it using Docker. We will create a Docker image that includes our NodeJS script and its dependencies, and then deploy it to our DockerHub repository.
Create a file Dockerfile in your working directory and paste the following code snippets into it:
FROM node:18
WORKDIR /app
COPY package*.json ./
RUN npm install
COPY . .
CMD [ "npm", "start" ]Considering the Dockerfile above, each command specifies the following:
FROM node:18: This line specifies the base image for the Docker container. Here, it is using the official Node.js version 18 image as the base for the container.WORKDIR /app: This line sets the working directory inside the container to/appand defines that subsequent commands or instructions will be executed within this directory.COPY package*.json ./: This line copies thepackage.jsonfile (and any other files starting with “package”) from the host machine to the/appdirectory inside the container. It allows the dependencies defined in thepackage.jsonfile to be installed within the container.RUN npm install: This line runs thenpm installcommand inside the container to install the dependencies specified in thepackage.jsonfile.COPY . .: This line copies all the files and directories from the current directory (on the host machine) to the current working directory (/app) inside the container. It includes all the source code and additional files required for the application to function properly.CMD [ "npm", "start" ]: This line specifies the default command to be executed when the container starts. It runs thenpm startcommand, which typically starts the Node.js application defined in thepackage.jsonfile.
Build the image for our Node.js script with the command below:
docker build -t <your-dockerhub-username/your-repo-name:tagname> .Considering the command above, ensure you are logged in to your DockerHub account. Logging in is necessary to interact with your DockerHub account, such as pushing or pulling images. To log in, you can run the docker login command on your terminal or command prompt.
This command will prompt you to enter your DockerHub username and password. You will be logged in once you provide the correct credentials associated with your DockerHub account. Once logged in, you’ll be able to perform various actions, such as pushing your local Docker images to your DockerHub repository or pulling images from DockerHub to your local machine; indicating that you have the necessary permissions and authentication to interact with DockerHub services.
Now push this image to your DockerHub repository with the following command:
docker push <your-dockerhub-username/your-repo-name:tagname>
Creating the CronJob
Since we now have our script on DockerHub, the next step is to create a CronJob in our cluster to use that script.
Create a file cronjob.yaml and paste into it the following configuration settings:
# cron-job.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: mysql-logs
spec:
schedule: "*/10 * * * *"
successfulJobsHistoryLimit: 2
failedJobsHistoryLimit: 2
concurrencyPolicy: Forbid
jobTemplate:
spec:
template:
spec:
containers:
- name: cronjob
image: mercybassey/logs-cronjob:latest
command: ["npm", "start"]
restartPolicy: NeverThis is what each section in the configuration settings above stand for:
apiVersion: This specifies the API version of the CronJob resource.kind: This specifies the type of resource being defined, a CronJob.metadata: This section defines the metadata for the CronJob, including its name.spec: This section defines the desired behavior, schedule, and configuration of the CronJob resource and does the following:- Specifies the schedule for the CronJob. It uses a cron expression to define the frequency at which the job should run. Here, it will run every 10 minutes, using the
scheduleproperty. - Sets the
successfulJobsHistoryLimitproperty to only keep two successful job completions in the job history. - Specifies the number of failed job completions to keep in the job history using the
failedJobsHistoryLimitproperty. - Prevents concurrent runs of the CronJob resource by setting the value of the
concurrencyPolicyproperty toForbid. - Defines the template for creating individual job instances using the
jobTemplateproperty, which contains the specifications for the template’s pod, containers, and other resources.
- Specifies the schedule for the CronJob. It uses a cron expression to define the frequency at which the job should run. Here, it will run every 10 minutes, using the
Deployment and Monitoring
To deploy the CronJob resource in our Kubernetes cluster, run the following commands.
kubectl apply -f cronjob.yaml -n database
kubectl get cronjob -n databaseThe commands above will create and list the status of the CronJob, respectively.
You can see from the image below that the CronJob is scheduled to run every 10 minutes and is currently inactive:

You might want to execute the above command more than once to keep track of its active state. Once it is in an active state, execute the following commands sequentially to view the outcome of the CronJob:
kubectl get job -n database
kubectl get pods -n database
kubectl log <THE_POD_NAME_CREATED_BY_THE_JOB> -n databaseIf you have the below output, then the CronJob was successful:
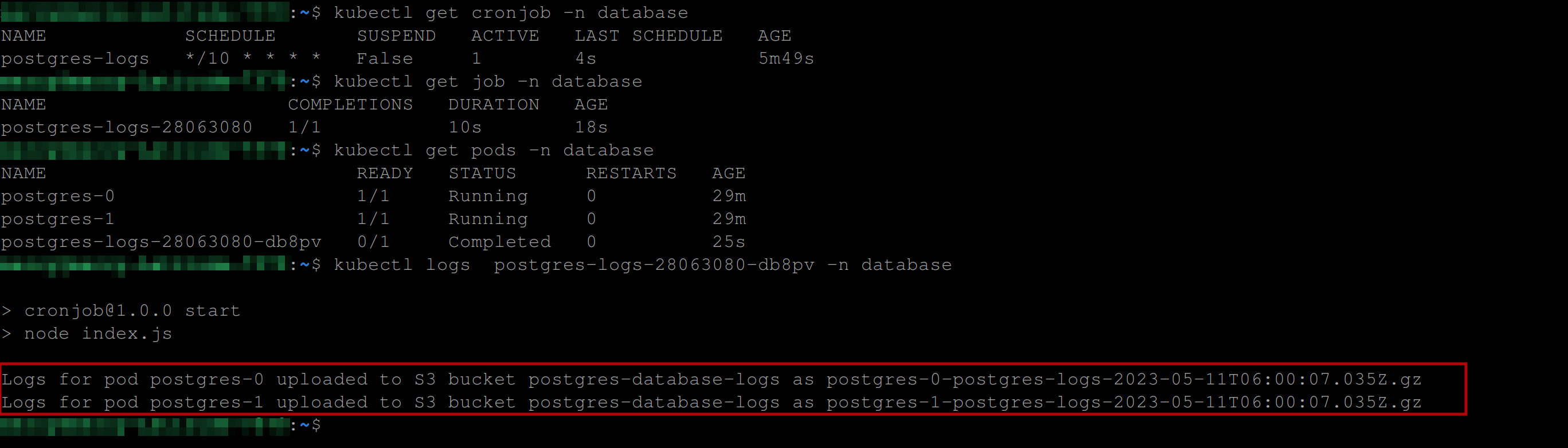
You can see from the image above that the job retrieved the logs from Postgres, compressed them, then uploaded the logs of the two replicas postgres-0 and postgres-1 created by the Postgrestatefulset and uploaded them to your AWS S3 bucket.
You can also see from the image above that the naming convention for the compressed logs file follows the pattern of <POD_NAME-STATEFULSET_NAME-logs-TIMESTAMP.gz>. Here, the POD_NAME is postgres-0, representing a specific pod in the Statefulset. The STATEFULSET_NAME is postgres, denoting the name of the Statefulset to which the pod belongs. The inclusion of “logs” in the convention signifies that the file contains pod logs. The TIMESTAMP, such as 2023-05-11T06:00:07.035z, represents the date and time of log file compression. The .gz extension indicates that the file is compressed using the gzip algorithm.
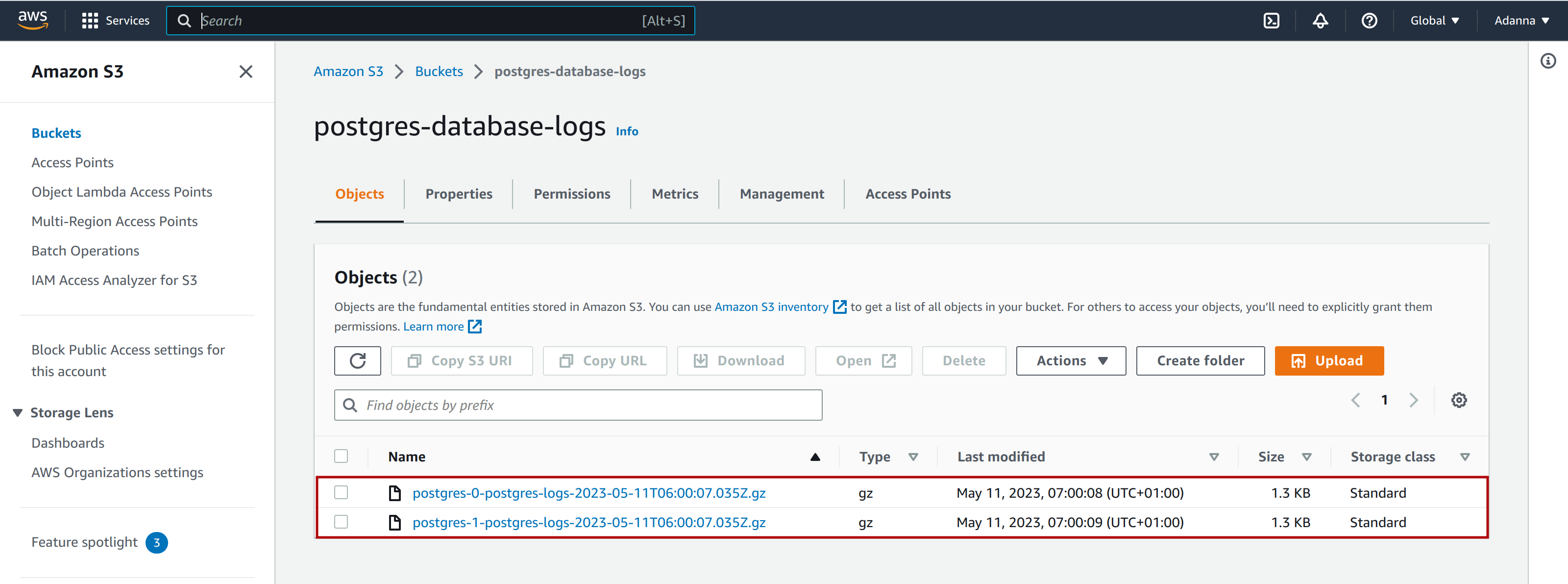
Once you head over to the S3 page on the AWS management console, you should see the log objects as shown below, which you can then download and use to suit your needs:
Conclusion
CronJobs in Kubernetes provide valuable automation for periodic tasks like log management. This tutorial walked you through creating, building, and deploying a script for log retrieval and compression. You’ve now learned how to effectively schedule tasks using Kubernetes CronJobs. Go ahead and implement this knowledge in your projects for a scalable solution.
If you’ve enjoyed automating with Kubernetes, you might also love optimizing your builds. For that, check out Earthly, a tool that can further enhance your development workflow.
Earthly makes CI/CD super simple
Fast, repeatable CI/CD with an instantly familiar syntax – like Dockerfile and Makefile had a baby.








