
Mining Meaningful Methods from Large Language Models

We’re Earthly. We simplify building software with containerization. This article shares lessons from a Proof-of-Concept Earthfile generator project.
A Newbs’s Guide to Applying Large Language Models
A month ago, the whole Earthly team was gathered in a board room at the Hilton Garden Inn in Minnesota. After a fun day of boating and then curling, we were getting down to planning. Our CEO was saying that one of the biggest adoption hurdles with Earthly is the time investment customers need to spend to change over their builds. The investment quickly pays off, but it’s also not zero, and so represents an onboarding challenge.
Ideas were kicked around for easing adoption. Several candidate projects were proposed and scheduled. And then, at some point, some poor soul raised their hand to volunteer to take on the most ambitious of those projects: a GitHub action (GHA) to Earthfile converter.
This is hard because while I find Earthfiles easier to write than GHA workflows, an Earthfile needs to know more about your build than can be found in a GHA workflow. There is missing information because Earthly needs to know what files are input into each step.
But there was a plan for how to close this gap. The theory went that GPT-4 could fill in the details. Or at least that volunteer could find out if that was possible. And that poor volunteer, did I mention that was me?
So my task was to build a translator using an LLM. It’s not entirely done, but it works well so far, (GitHub link). Building it was different than I thought, and I learned some lessons that are generally helpful if you are thinking of building on top of an LLM. Let’s go through them.
Context: A Scarcity in a Sea of Surplus
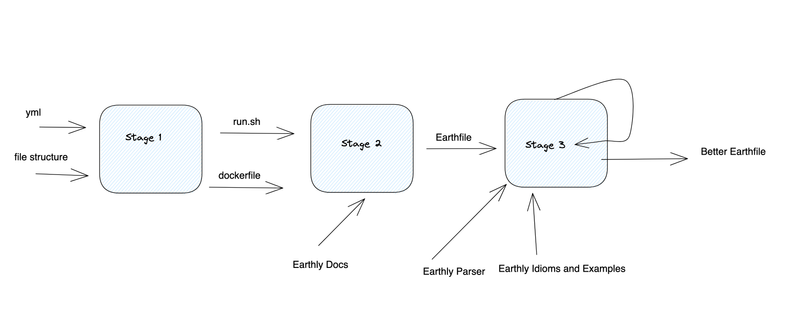
Lesson number one: context is precious. GPT-4 has a limited context window. I’m using the 8k token version, which means all the information I provide – and its answer – need to fit in less than 8000 words. For me, this includes the GitHub Actions yml, the file structure of the project, some example conversions, and some of the Earthly documentation. This limit – this narrow frame – demands our prompts be a masterful blend of brevity and precision.
You may have heard that vector databases solve the problem of limited context windows. That is incorrect. These databases help you select the most relevant information to fit within the context window. But you still have the same limit. You don’t get more tokens.
In fact, Earthly’s docs are bigger than the context window. So one of my challenges was feeding GPT-4 just enough of the docs to enable it to translate. And to do that, I needed to know what GPT-4 knows.
Knowing What It Knows
GPT-4 needs to learn more about the Earthfile format to translate it independently. Right now – without any outside information – it will just hallucinate some parts of the Earthfile syntax.
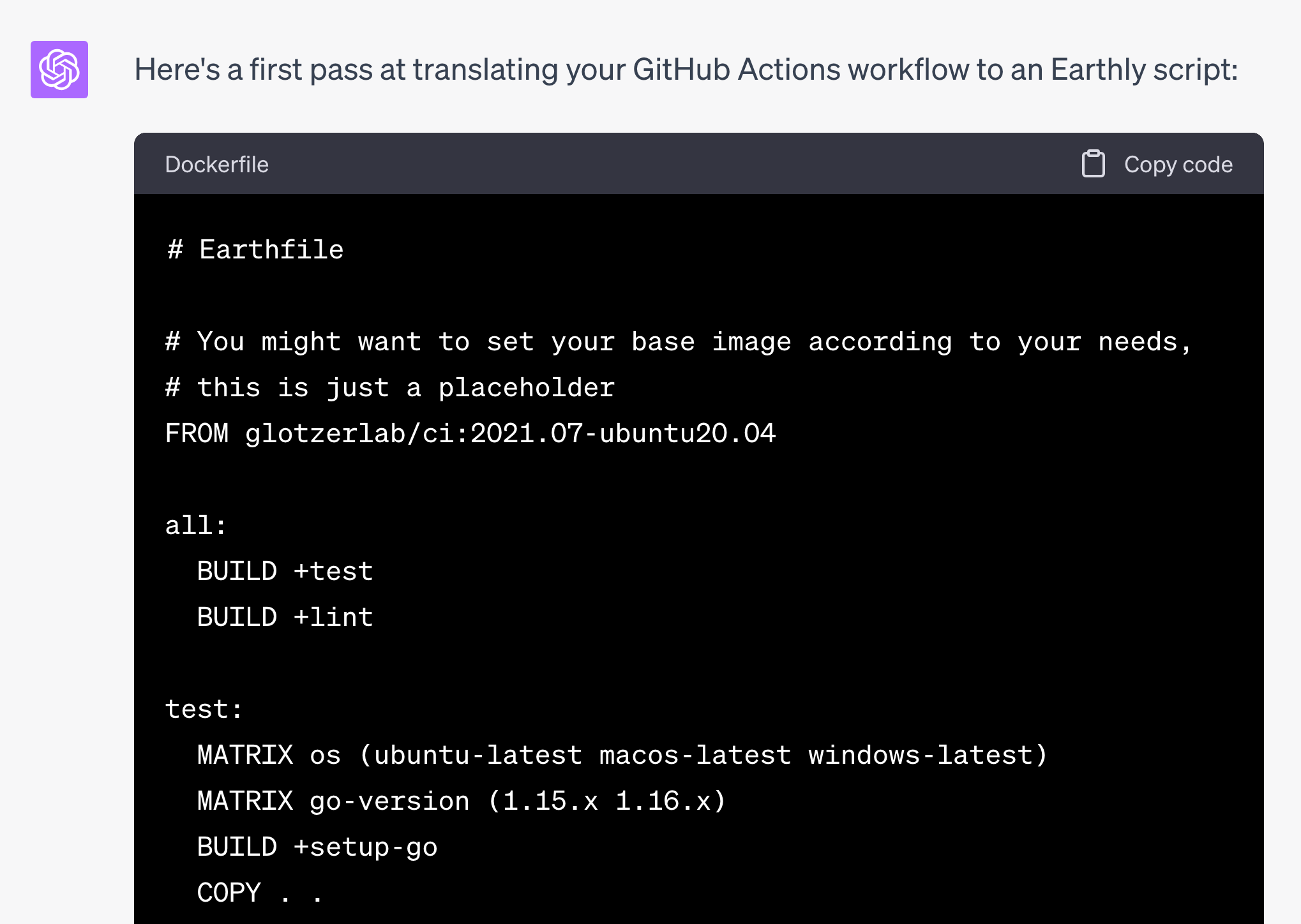
Perhaps its next training run will consume more of our docs, and it will just know how to translate, but right now, it doesn’t. It does know Dockerfiles, and makefiles, though. Ask it to write a dockerfile for a project, and it does an alright job. And so, prompting it with the shorthand ‘Earthly is like a Dockerfile but with targets like a makefile’ was able to get me a better result. Less Earthly documentation was needed in the prompt (saving precious context window).
Divide and Dominate
My next trick was to break my task into manageable pieces. Instead of tackling the entire conversion in one go, I introduced an intermediary step. First, translate GitHub Actions into bash scripts and Dockerfiles. Then, convert those to Earthly. This is more steps but makes the conversion somewhat mechanical.
There are more generic solutions to breaking tasks up. One method – related to “Tree of Thought” prompting – is to prompt the LLM for a list of steps for accomplishing a goal: “What are the key steps to convert between a GitHub Actions build and Earthly?” Then each substep could be turned into a further query. If the first step generated was “Understand the differences between GHA and Earthly,” then you’d prompt again, asking for the differences. You keep iterating on the steps until, hopefully, the substeps coalesce into a solution. For the type of very specific conversion I’m doing, though, this seems more like a gimmick than a viable solution. Instead, what really helped me make progress was understanding how to structure my messaging.
Messaging the Machine
People online often say that an LLM only predicts the next token. That’s true, but it’s not particularly helpful when it comes to crafting prompts. Instead, I found it helpful to imagine I was emailing a junior engineer. I’ve tried to onboard juniors remotely, and it’s always a challenge. Some adapt and learn quickly, while others struggle with every task. Anthropomorphizing like this is strictly incorrect, but GPT-4 feels like one of the juniors I worked with who struggled to get up to speed.
This engineer knows a lot but not in much depth. And they can’t ask for more info from you, so you have to give it all upfront. They can understand instructions reasonably well ( and because they are a machine, they turn around results pretty quickly, speeding up iteration.), but if they get confused, they will never ask for clarification.
If you’ve ever been confused about why someone on your team in isolation came up with a strange solution to something, you’ll get what working with an LLM is like. Thankfully there is a way to debug this: Thinking out loud.
Vocal Victory: The Power of ‘Thinking Out Loud’
Early on, I noticed my LLM teammate sometimes took a long time on specific queries. It was like they needed more time to think before answering. It turns out that is not true. LLMs don’t pause and think. They create the answers as they think and ‘think’ the same amount on every token. The varying response times were likely due to system load or job queue depth.
This no-internal-dialogue insight leads to a straightforward solution to getting more intelligent answers from LLMs: let the model use more tokens by encouraging step-by-step thinking. If your LLM can’t have an internal dialogue, give it an external one. This is called “Chain of Thought” (COT) prompting, but really, it’s just thinking out loud.
Instead of asking for an answer, I ask the LLM to translate by going through the input file line by line. It should describe what needs to be done for each translation step. Then, I request the answer, using the previous stream-of-non-conscious as part of the prompt, and I get a better, more intelligent answer. It works so well that it is my biggest tip: Tell it to think out loud! Use more tokens, and get a better answer.
Here are a couple of variations on this idea:
Experts-prompting: First, ask the transformer for 3 experts’ names. Then, ask each expert to solve the problem. Finally, request the transformer to synthesize an answer from their responses.
Critique-prompting: after generating an Earthfile, I asked GPT-4 to identify ways it can be improved. It then describes possible improvements. In this way, it finds mistakes by checking its own work.
Structured COT: COT can be adapted to JSON output as well. If labeling data, have a JSON field called “reasoning” that contains the reasoning for the label before outputting the actual label. This will force more ‘thinking’ to happen before choosing the label.

Most online tricks follow this formula: Make your LLM think more about the question in several ways before giving an answer.
No Trust Without Truth
Next Tip: Say you want to make a speech of yours more humorous using an LLM. Now you know not just to give it your notes and ask for more humor. Instead, you’d ask it to rewrite paragraphs like they were by Dave Barry, David Sedaris, or Amy Schumer. Then you could ask it to pick the funniest rewrites from all of those. Let it think and evaluate solutions creatively.
But you can’t just let go on forever, telling it to make your speech funnier and funnier because it doesn’t have access to the ground truth. It has no way to verify humor. It may generate a funny joke and then three nonsense jokes. When LLM don’t have the answer, they just make things up. This is the biggest complaint I see about LLMs. But it’s often not a problem if you can verify answers.

For my Earthfile project, GPT occasionally makes things up, but I can quickly check and correct them against Earthly. No need for open mic nights with a laptop. Tasks like these - NP-complete tasks, where the solution is expensive to generate but verifying is cheap - are an excellent fit for LLMs. All you need is a problem domain where you can cheaply validate results and a way to provide corrective feedback.
Taming Troubles With Thought Chains
Ok, corrective feedback. It’s great that I know a correct answer when I see one and can verify things with the Earthly parser, but what if I never get a correct answer for specific inputs? Well, then, I need to teach my junior engineer how to solve the problem.
When the LLM translated a section of GHA that wasn’t relevant into made up Earthly commands, how could I tell it to ignore that section? Easy; I can correct the generated chain of thought results and feed them back to it as part of the prompt.
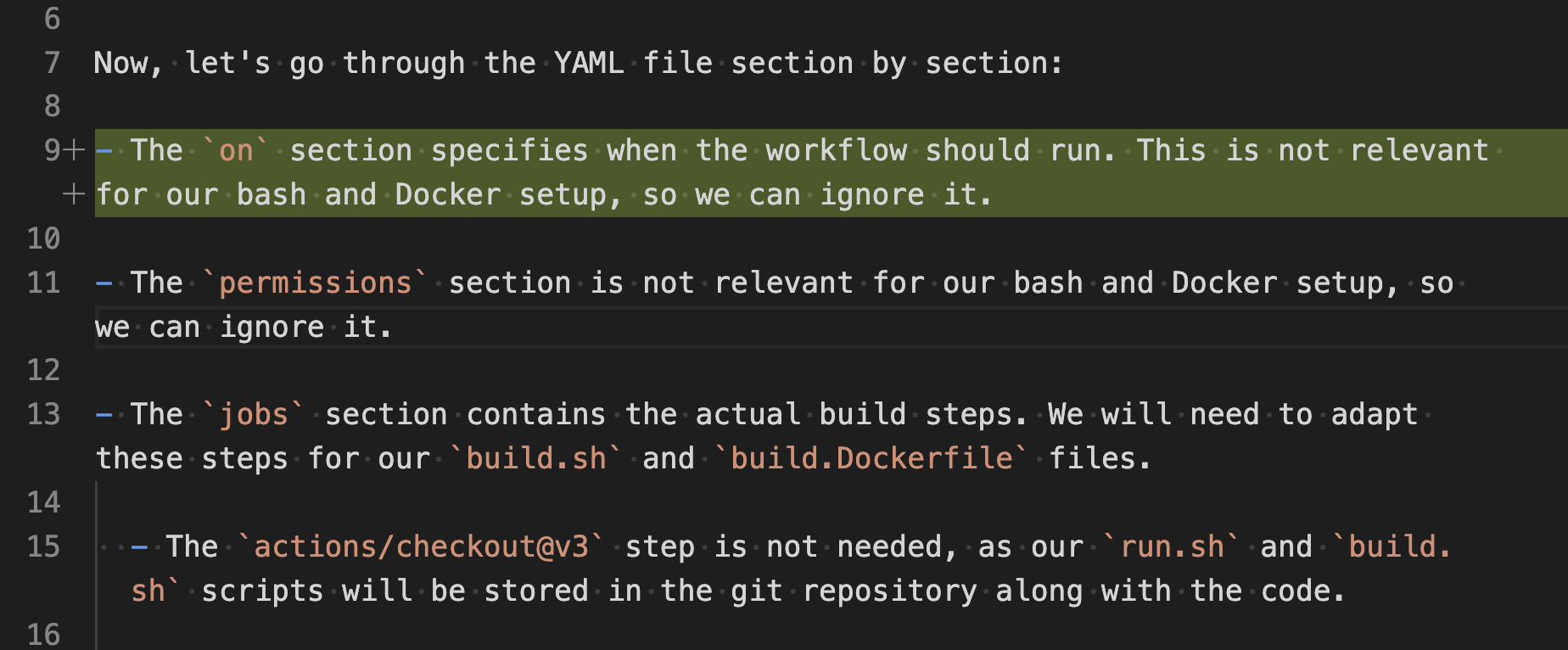
Because it is sharing its thinking with you, you can edit the thinking and feed it back as an example. In the above, I included an example where it ignored that on section. The LLM then learned the correct process by pattern matching on that example. This is called few-shot chain of thought, and it’s an excellent way to show the LLM the correct approach for a specific example.
(Ideally, you only need a few of these because it will quickly eat your 8k context window, and you’ll have to move to fine-tuning, or beg for GPT4-32k access. Context is Precious.)
Memory and Mastery: Wrapping Up the LLM Adventure
As a newcomer to working with large language models, I found the experience of building an Earthfile generator both challenging and enlightening. Through trial and error, I discovered several techniques that helped me overcome limited context windows and model limitations to achieve meaningful results:
Managing context carefully was essential. I learned to keep prompts focused and only provide the minimum necessary information. Context is scarce.
Framing the problem in familiar terms the model already understood helped minimize the new information I had to provide. For example, describing Earthly as “like Dockerfiles with Makefiles” required less additional explanation.
Breaking down the complex task into smaller steps made solving the problem more manageable. Solving subproblems was less frustrating than tackling the entire end-to-end process at once.
Using “thinking out loud” prompting and asking the model to reason through problems step-by-step produced better results. The model could connect its knowledge in a gradual, guided way. Variations like “expert prompting” and “critique prompting” offer added benefits.
Providing corrective feedback when the model struggled was an effective way for me to teach it appropriate approaches. Examples of input, reasoning, and the correct output I wanted helped the model learn.
These techniques were invaluable in helping me understand how to apply LLMs to real-world problems. The potential of these technologies, combined with thoughtful instructional approaches to overcome their limitations, is fantastic.
If you’re building things with LLMs, I’d love to hear about any tricks you’ve learned. Also, if you are using GitHub actions, you should give Earthly a try. Earthly can improve the consistency of your build, so you never get a build failure you can’t reproduce locally. It works great with GitHub actions. And want your GitHub Actions to be even faster? Our satellites can make that happen.
Earthly makes CI/CD super simple
Fast, repeatable CI/CD with an instantly familiar syntax – like Dockerfile and Makefile had a baby.







