
How to Build a News Categorization Classifier with NewsAPI, NLP, and Logistic Regression

We’re Earthly.dev. We make building software simpler and therefore faster – like Dockerfile and Makefile had a baby. This article shows you how to build a news classifier with NewsAPI, NLP, and Logistic Regression
According to Earth Web over 2-3 million, news articles are published every day on the internet, with big publishing platforms like The Washington Post publishing over 500 news articles daily. This is a staggering number and it makes one wonder how news is separated into different categories for readers, editors, and other stakeholders.
Categorizing news is a very important process. It is the first step before moving to news aggregation, monitoring, filtering, organization, summarization, and retrieval; which are all very important components of news publishing. Different methods, like the use of APIs and software, have been employed to make news categorization simpler. However, machine learning models offer an even more efficient system and will be the basis of this article.
In this article, we will explore how to build a news categorization classifier using NewsAPI, Natural Language Processing (NLP), and Logistic Regression. The news categorization classifier is a form of text classification that assigns labels or tags to text organising it into groups. Through this classifier, we can effectively categorize our news articles into various categories.
We will use the NewsAPI to build a dataset comprising news of different categories. Afterward, we will use logistic regression to train and evaluate the datasets - NewsAPI and Logistic Regression will be explained later in the article.
This project’s text classifier model will be trained to go through a list of news headlines or titles to determine the category they fall into - this could be business, entertainment, sports, or tech. Companies, professionals, researchers, students, and data analysts who work with text data would find this article a useful resource on how to classify text with a logistic regression model.
By building this text classifier with logistic regression, we will learn how to collect news from NewsAPI, pre-preprocess, and transform the news data using NLP techniques, build, and train a logistic regression model to classify news into different categories, and predict other categories of news with unseen data.
Text Data and Text Classification
Text data is a very common type of data. It can be found almost everywhere - in reviews, comment sections, forms, emails, forums, and feedback. Companies, professionals, researchers, students, data analysts, and machine learning practitioners must frequently engage with text data to gain useful insights into a problem.
Unlike numeric data, text data is unstructured and non-linear. Working with large texts requires advanced techniques and a more complex process for analysis.
Text classification is widely used in many digital services today for checking spam emails, identifying customers’ sentiments on a company’s comment section, tracking hate speech on social media, etc. Because of the sheer volume of text that needs to be processed, machine-learning algorithms are trained to classify text. One such algorithm is the Logistic Regression.
Logistic Regression
Logistic regression is a machine learning classification algorithm that predicts a finite number of outcomes for independent variables. It is usually used to determine the probability of an event occurring. These could be binary events with only two outcomes - yes or no. For example, if a student would pass a course or not.
However, it could also be extended to handle multi-class or multinomial classification problems in which there are multiple classes in a target variable and the algorithm would have to predict the class that best fits. For example, classifying movies or books into different genres.
Why Is Logistic Regression Important?
Logistic regression falls under the classification technique in machine learning, and according to DataCamp, “70% of problems in data science are classification problems”. This makes it a very significant algorithm, seeing that it can be used to solve an extensive number of problems in diverse fields such as statistics and social sciences.
Compared to other classification algorithms like Naive Bayes, Random Forest and K-nearest Neighbors, it is simple, easy to implement and can be used in combination with other techniques for data analysis and decision-making.
What Can We Build With Logistic Regression?
We can build a lot of classification models with logistic regression algorithms. They include models with a binary outcome like:
Weather forecasting (to determine if it will rain or not).
Stock prices (to determine if the value of a stock will rise or drop).
Email spam detection (to determine if an email is spam or not).
Or models with multiclass, categorical values like:
Sentiment analysis.
Flagging fake news.
Predicting the category of an article.
Predicting which party a person will vote for.
Tools To Be Used in The Project

We will need to make sure we have the proper tools before we can start building our classifier. Let’s start by installing Scikit-Learn.
Scikit-Learn, , also called Sklearn. This is the most important library for building this classifier. It provides a selection of efficient tools for building machine-learning models.
We will need it to import the classes like the LogisticRegression class, the train_test_split class, the accuracy class and the predicted class, which all play a vital role in constructing the classifier and obtaining accurate results.
Install scikit-learn with pip:
pip install scikit-learn Next, we will install the NLTK. package. The Natural Language Toolkit (NLTK) is a Python package for Natural Language Processing (NLP). We will need it to tokenize the text and remove stopwords.
Install with pip:
pip install --user -U nltkThe next library that we need is the Python re module which allows us to work with regular expressions. This will be needed for cleaning and processing text. We don’t need to install it as it’s inbuilt into Python.
The NewsAPI Python client library is a wrapper for the NewsAPI API. The API is an easy-to-use REST API that will return breaking news articles from all over the world, from over 80,000 sources, some of which include BBC News, MSNBC, Google News, Wired, Lequipe, and Ynet. is important because it provides us with the dataset that we can work with in this article.
Install with pip:
pip install newsapi-pythonFinally, we need the Pandas library for data frame manipulation and analysis.
Install using pip:
pip install pandasThe NewsAPI
To get started, we need a dataset that contains news and the different categories they belong to.
Setting Up An Account With NewsAPI
To use the NewsAPI’s API, we also need an API key, and we can only get that by creating an account. This is pretty straightforward, and once the registration is successful, a page with the API key is displayed.
Make sure to copy the key somewhere safe. We will need it later.
Extracting Data With the NewsAPI
With the NewsAPI’s Python client library we can integrate NewsAPI directly into our application and fetch the data we need using either of these methods provided by the client library; get_everything(), get_top_headlines() and get_sources(). These methods provide an abstraction over the NewsAPI’s REST API endpoints. We’ll use the get_everything() method in this tutorial.
Each method requires different request parameters. These request parameters include sources, domain and date, and q. The sources parameter specifies the news sources where the news was gotten from, the domain parameter is the domain name of the website, the date parameter is the date the news was published, and the query is the phrase or keyword to search for in the news body or title.
To extract the news articles for a specific query, we will first import the NewsAPIClient class:
from newsapi import NewApiClientInstantiate the NewsAPIClient class with your API key:
newsapi = NewsApiClient(api_key='2a7dd9f4dd8fxxxxxxxxxxxxxxxxx')
#use your API key hereThen extract with the query, language, and page size parameters:
tech_articles = newsapi.get_everything(q='tech', language='en', \
page_size=100)
tech_articlesThe output is a dictionary of 100 news articles related to tech:
Transform Output Data Into Pandas DataFrame
NewsAPI search result returns a JSON object when the API is called. Although JSON is a good format for data storage and processing, we will be performing data analysis and manipulation that is best suited for data in a tabular format. This is why we need a Pandas DataFrame.
A quick look at the tech_articles object keys shows that there are three dictionary keys returned.
tech_articles.keys()Output:
#output
dict_keys(['status', 'totalResults', 'articles'])We only need the object of the articles, which will be transformed into a Pandas data frame:
import pandas as pd
tech = pd.DataFrame(tech_articles['articles'])
tech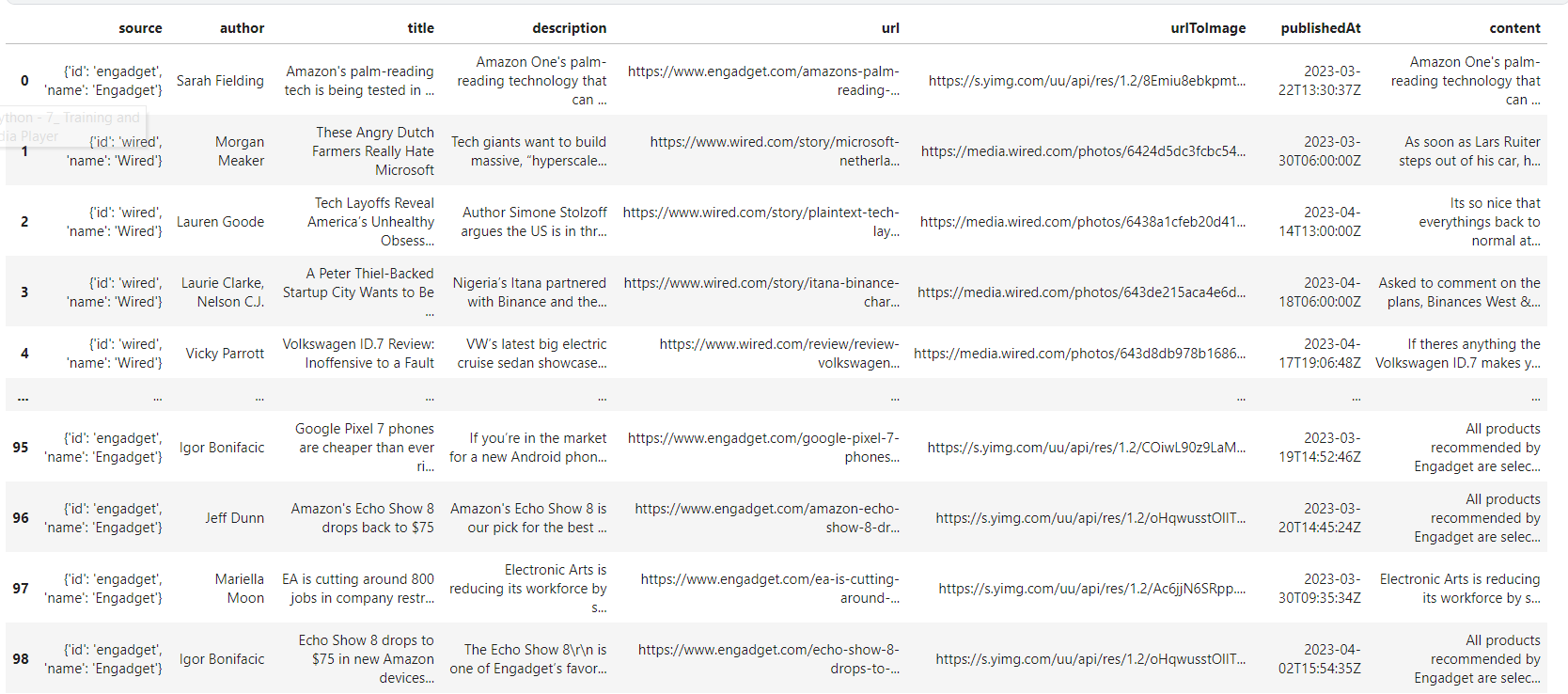
The output is 100 rows of tech data with 8 columns.
Exploring Independent and Dependent Variables
A logistics regression algorithm needs an independent variable and a dependent variable for training. The independent variable also called the predictor variable is the variable to experiment on. Training the independent variables allows the algorithm to capture the various segments and patterns of text necessary for classification, thereby empowering the text classifier to adapt well to new and unseen text.
The independent variables are derived from the text itself, which means the news title column, content, or description columns can act as independent variables because they have the actual news text, or headlines.
The dependent variables are the outcome variable. They are the variables that we want the independent variable to predict or classify. They represent the class or category to which news belongs. Without them, there would be no target for the model to make predictions on. In this scenario, our objective is to classify news headlines (the independent variable) into various categories (the dependent variable).
We have gotten our news headlines and content on the data frame, however, we don’t have a column for news categories. We’ll need to add one:
#adding the tech category
tech['category'] = 'Tech'
tech 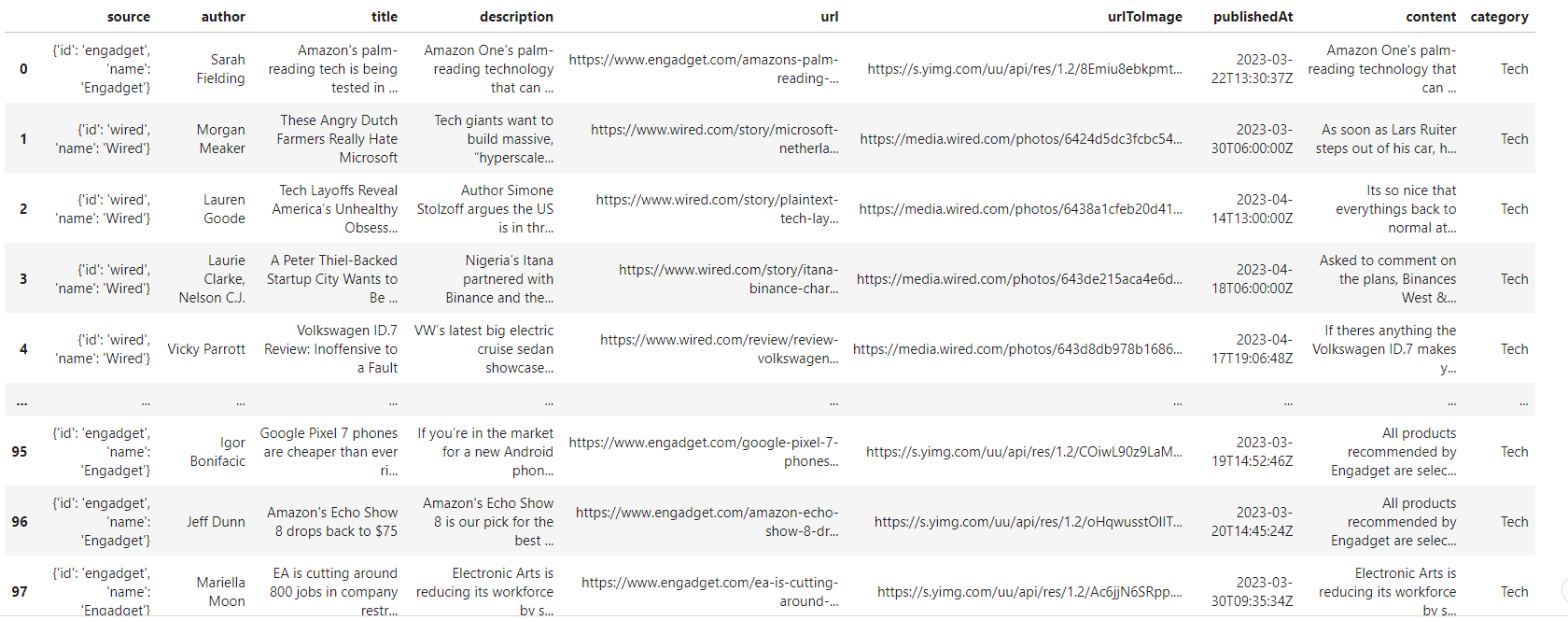
Prediction model algorithms like logistic regression typically benefit from having an adequate dataset size to mitigate the risk of overfitting and inaccurate outputs. However, logistic regression stands out as a suitable choice for small datasets due to its simplicity, interpretability, low risk of overfitting, and reduced computational requirements. Generally, a suitable dataset size can vary depending on several factors including the complexity and diversity of the dataset, the complexity of the algorithm, and the number of outputs needed.
Considering the specific requirements for this project, we only require a small number of outputs (about 6) and the logistic regression algorithm is suitable for this need. Its compatibility with small datasets makes it suitable. For these reasons, a dataset of 800 entries seems adequate.
We only have the tech category available. We will need to go through the steps again to get 7 other categories, making it a total of 800 entries.
NB: Remember each category has 100 entries due to the
page_sizeparameter we specified earlier.
So let’s grab some more articles by category:
entertainment_articles = newsapi.get_everything(q='entertainment',\
language='en', page_size=100)
business_articles = newsapi.get_everything(q='business',\
language='en', page_size=100)
sports_articles = newsapi.get_everything(q='sports',\
language='en', page_size=100)
politics_articles = newsapi.get_everything(q='politics',\
language='en', page_size=100)
travel_articles = newsapi.get_everything(q='travel',\
language='en', page_size=100)
food_articles = newsapi.get_everything(q='food',\
language='en', page_size=100)
health_articles = newsapi.get_everything(q='health',\
language='en', page_size=100)And remember to convert them into a DataFrame and add the category column:
entertainment = pd.DataFrame(entertainment_articles['articles'])
entertainment['category'] = 'Entertainment'
business = pd.DataFrame(business_articles['articles'])
business['category'] = 'Business'
sports = pd.DataFrame(sports_articles['articles'])
sports['category'] = 'Sports'
politics = pd.DataFrame(politics_articles['articles'])
politics['category'] = 'Politics'
travel = pd.DataFrame(travel_articles['articles'])
travel['category'] = 'Travel'
food = pd.DataFrame(food_articles['articles'])
food['category'] = 'Food'
health = pd.DataFrame(health_articles['articles'])
health['category'] = 'HealthMerge everything into one Pandas DataFrame using the concat function from the Pandas library. This puts all the information in one data frame, making it easier to access, analyse and train:
categories = [tech, entertainment, business, sports, politics, \
travel, food, health]
df = pd.concat(categories)
df.info()Output:
# output
<class 'pandas.core.frame.DataFrame'>
Int64Index: 800 entries, 0 to 99
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 source 800 non-null object
1 author 639 non-null object
2 title 800 non-null object
3 description 799 non-null object
4 url 800 non-null object
5 urlToImage 633 non-null object
6 publishedAt 800 non-null object
7 content 800 non-null object
8 category 800 non-null object
dtypes: object(9)A quick look into the new DataFrame using the Pandas .info() function shows there are 800 entries and 9 columns. There are columns with null values like the urlToImage column which has only 633 non-null entries. However, since the columns with missing values are the ones we won’t need in this tutorial, we won’t do anything about it.
Building the Classifier
We have retrieved our data from the NewsAPI database and arranged the data frame to be suitable for use. In this section, we will look at the steps to building the classifier (which is the logistic regression model). We will go through preparing and processing the text, splitting the data into training and testing subsets using the train_test_split class, training the classifier, and evaluating the performance of the model.
Text Preprocessing
Now that we have downloaded and transformed our training dataset, we will move on to preparing and processing the text. Text data is often messy and unstructured, filled with punctuation, ambiguity, spelling mistakes, and special characters that add noise to it. By preparing the text, we make it suitable for the classifier.
There are three important steps for text preprocessing:
First, we remove all punctuation, symbols, spaces, non-characters, and quotes. This can be done with regex.
Secondly, tokenize all sentences. Tokenization will split phrases, sentences, and complex words into small units. Machine learning models have an easier time understanding and interpreting the meaning of the text when they are broken into tokens. Let’s say we have the sentence ‘Christmas is here.’ When tokenized, this becomes, ‘Christmas’, ‘is’, ‘here’.
Finally, remove stopwords. Stopwords are common words in a language that adds very little meaning to a text. Examples include “is”, “the”, “because”, “it” etc. Removing them helps to get rid of words that only make a text weighty but with little value. It also takes away noise from the text.
At our first stage of preprocessing, we will use re to remove all punctuations, special characters, full stops, commas, extra spaces, and quotes:
import re
# Define the function to clean the title column
def cleaned_desc_column(text):
# Remove commas
text = re.sub(r',', '', text)
# Remove extra spaces
text = re.sub(r'\s+', ' ', text)
# Remove full stops
text = re.sub(r'\.', '', text)
# Remove single quotes and double quotes
text = re.sub(r"['\"]", '', text)
# Remove other non-word characters
text = re.sub(r'\W', ' ', text)We must get rid of anything insignificant to the classifier from the text. Punctuations, extra spaces, and special characters only add variations to a text. Hyphens on the other hand do not need to be removed. They teach the classifier how to handle compound words. Next, we tokenize the text:
import nltk
nltk.download('punkt')
def cleaned_desc_column(text):
…Punkt is a tokenizer that divides the text into a list of sentences using an unsupervised learning algorithm. We could use a pre-trained punkt or train one on a large collection of text. The NLTK package comes with a pre-trained punkt tokenizer for English. We’ll use this - rather than train one - to initialize the word_tokenizer() function:
from nltk.tokenize import word_tokenize
…
def cleaned_desc_column:
…
text_token = word_tokenize(text) To tokenize our text, we used NLTK’s inbuilt function word_tokenize(). This function provides a standardized way of tokenizing text for further use. It can handle contractions, hyphenated words, and other word forms according to a language’s rules. It only takes the text to be tokenized as an argument. Next, we need to remove stop words: To remove stopwords, we used NLTK’s stopword function and set the language to English. English has over 170 stop words. The stopword function goes through the text and whenever it comes across a word in its corpus (which is the 170 stopwords in its collection), it removes it.
from nltk.corpus import stopwords
…
nltk.download('stopwords')
…
def cleaned_desc_column:
…
stop_words = set(stopwords.words('English'))
filtered_text = []
for sw in text_token:
if sw not in stop_words:
filtered_text.append(sw)
text = " ".join(filtered_text)
return textHere is what the whole code block looks like:
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
import nltk
nltk.download('punkt')
nltk.download('stopwords')
# Define the function to clean the news title column
def cleaned_desc_column(text):
# Remove commas
text = re.sub(r',', '', text)
# Remove extra spaces
text = re.sub(r'\s+', ' ', text)
# Remove full stops
text = re.sub(r'\.', '', text)
# Remove single quotes and double quotes
text = re.sub(r"['\"]", '', text)
# Remove other non-word characters
text = re.sub(r'\W', ' ', text)
text_token = word_tokenize(text)
stop_words = set(stopwords.words('english'))
filtered_text = []
for sw in text_token:
if sw not in stop_words:
filtered_text.append(sw)
text = " ".join(filtered_text)
return textIn the code below, we successfully processed our data, now we apply the cleaned_desc_column function to the ‘title’ column since that is our independent variable:
# Apply the clean_text_column function to the text_column in the DataFrame
df['news_title'] = df['title'].apply(cleaned_desc_column)
df
# The cleaned column 'news_title' is added to the data frame. To get the categories we need for training and testing, we’ll use the cleaned title column as the independent variable and the category column as a dependent variable:
#getting the category we need for testing
X = df['news_title']
y = df['category']Splitting Data Into Training and Testing Subsets
At this stage, we need to divide the data into training and testing datasets using the train_test_split class from the sklearn library::
import sklearn
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = \
train_test_split(X, y, test_size = 0.30, random_state = 90)
print(X_train.shape)
print(X_test.shape)Output:
(560,)
(240,) The output shows the number of rows assigned to the train data and the number assigned to the test data.
The test_train_split class implements the train-test-split technique which is used to train a dataset and test it on unseen data. This process involves dividing a dataset into two - train and test datasets. The consequence of training the entire dataset without splitting is that the model would overfit and perform extremely well on the trained data, but fare poorly on new data, hence the need to split data into training and testing subsets. Usually, the training data takes a higher percentage, so we will split the dataset into a 70:30 percent ratio. This is denoted in the train_test_split function parameters as simply 0.30.
We also need to add the random_state hyperparameter in the model to allow for consistent results and control over dataset randomness. The choice of any positive number for random_state is sufficient, as its numerical value doesn’t hold specific meaning. By using the same random_state number in different runs of the model, the behavior remains consistent, while changes in the number can introduce variability.
Text Vectorization and the TF-IDF Score
After splitting our dataset into training and testing subsets, the next stage is to feed it into the logistic regression algorithm. Machine learning algorithms do not accept raw text no matter how well-processed they are. This is because most algorithms including the logistic regression algorithm, are built to accept statistical and numerical data. Text data, after preparation and processing have to be converted to numeric values in a process called text vectorization.
Text vectorization is important because they not only convert words into numeric data but also offers ways of assigning values or weights to words based on their relevance. The relevance of a word in a document determines how it is ranked by the model. There are different text vectorizers to perform text vectorization on a text, but for this project, we would be using the TF-IDF (Term Frequency - Inverse Document Frequency) score.
TF-IDF is a combination of two techniques. The first part, TF (Term Frequency) focuses on how common a word appears in a document, and gives importance to frequent words. IDF (Inverse Document Frequency) is the opposite of TF. It rather emphasises the rarity of a word.
TF-IDF calculates a weight (score) that reflects the importance of every word in a category. While TF assigns weight to words as they appear. The basic formula for computing TF is:
TF = (Number of occurrences of the term in the document)
/(Total number of terms in the document. IDF measures the rarity of a word in a document. It considers that a word that occurs too often might not be relevant or informative to the text and so reduces the weight attached to the word. IDF formula is calculated as:
IDF = log((Total number of documents in the collection)
/(Number of documents containing the term)). To compute the final score of a term within a document, TF, and IDF are multiplied together. This multiplication emphasizes terms that are both frequent and rare within a document. The formula for calculating the TF-IDF score is:
TF-IDF = TF * IDFThe output of this multiplication is a score that is adjusted to strike a balance between common and rare terms, making the TF-IDF more robust in handling various term frequencies in the document collection. By considering the TF and IDF of a word before assigning a score, the TF-IDF vectorizer offers a counter-balance to how words are ranked. Low scores indicate a word has low relevance while high scores indicate more relevance.
Assume we have a text that includes words like ‘championship’, ‘team’, ‘victory’, ‘politician’, ‘movie’, ‘votes’ and ‘reviews’. If words like ‘team’ and ‘championship’ are given more weight, TF-IDF will classify the text under sports. And if words like ‘politician’, ‘votes’, and ‘victory’ are given more weight, TF-IDF will classify the text as politics.
The TF-IDF score is crucial in text classification because it captures the discriminative power of words and helps to reduce the dominance of some words over others, thereby improving the performance of the classifier.
To convert our text to numeric representation and calculate the TF-IDF score, we will be using the tfidfVectorizer() class.
Training the Classifier
With a pipeline, we will instantiate our LogisticRegression, and tfidfVectorizer classes. Next, we train the logistic regression model on the training set using the logistic regression fit class:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
lr = Pipeline([('tfidf', TfidfVectorizer()),
('clf', LogisticRegression(max_iter = 1000)),
])
# Train the logistic regression model on the training set
lr.fit(X_train,y_train)After training the dataset, we move on to making predictions:
# Make predictions on the test set
y_pred = lr.predict(X_test)Evaluating the Performance of the Model
After training the dataset, we need to evaluate its performance. There are different ways to evaluate the performance of the model. For this tutorial, we will use the most straightforward which is the accuracy score. The accuracy score compares the accuracy of predicted labels to the test set and calculates the proportion of correct predictions. Models with accuracy scores between 70% - 90% are generally considered to have good performance.
from sklearn.metrics import accuracy_score
# Calculate the accuracy of the model
print(f"Accuracy is: {accuracy_score(y_pred,y_test)}")Output:
#Output
Accuracy is: 0.7208333333333333Test The Model With Different Articles
Once the model is trained, we can make predictions with the predict() method and unseen data. For this, we’ll choose headlines that are not in the dataset:
news = ["Biden to Sign Executive Order That Aims to Make Child Care Cheaper",
"Google Stock Loses $57 Billion Amid Microsoft's AI 'Lead'—And \
Reports It Could Be Replaced By Bing On Some Smartphones",
"Poland suspends food imports from Ukraine to assist its farmers",
"Can AI Solve The Air Traffic Control Problem? Let's Find Out",
"Woman From Odisha Runs 42.5 KM In UK Marathon Wearing A Saree",
"Hillary Clinton: Trump cannot win the election - but Biden will",
"Jennifer Aniston and Adam Sandler starrer movie 'Murder Mystery 2' \
got released on March 24, this year"]
predicted = lr.predict(news)
for doc, category in zip(news, predicted):
print(category)Output:
Health
Tech
Food
Tech
Sports
Politics
EntertainmentSeeing that a news headline can fall into more than one category, the model tries to predict the best category that suits a news headline. From the output, the model’s classification of news headlines matches the categories expected. So our model works well.
Conclusion
In this tutorial, we have successfully built a logistic regression text classifier using Python, Scikit-learn, NLP, and NewsAPI. We have learned how to pre-process text data, train, and test a logistic regression model and predict the category of news articles. To gain further understanding, I recommend practicing with other datasets, and evaluating the performance of the models.
You can get the code here on Github
Earthly makes CI/CD super simple
Fast, repeatable CI/CD with an instantly familiar syntax – like Dockerfile and Makefile had a baby.








